







最近这一两周不少互联网公司都已经开始秋招提前批面试了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
总结如下:
《AIGC 面试宝典》圈粉无数!
《大模型面试宝典》(2024版) 发布!
喜欢本文记得收藏、关注、点赞。
开源啦!开源啦!
早上起来发现,Meta AI又开源模型,文本模型开源了端侧小模型1B和3B模型,也是首次开源了多模态大模型11B和90B两个版本;同时还开源了一个 Llama Stack项目。
Blog: https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices/
HF: https://huggingface.co/collections/meta-llama/llama-32-66f448ffc8c32f949b04c8cf
其中Llama3.2多模态模型在图像识别和一系列视觉理解任务方面效果优于Claude 3 Haiku 和 GPT4o-mini。文本模型-Llama3.2-3B模型在循指令、总结、提示重写和工具使用等任务上优于 Gemma 2 2.6B 和 Phi 3.5-mini 模型。
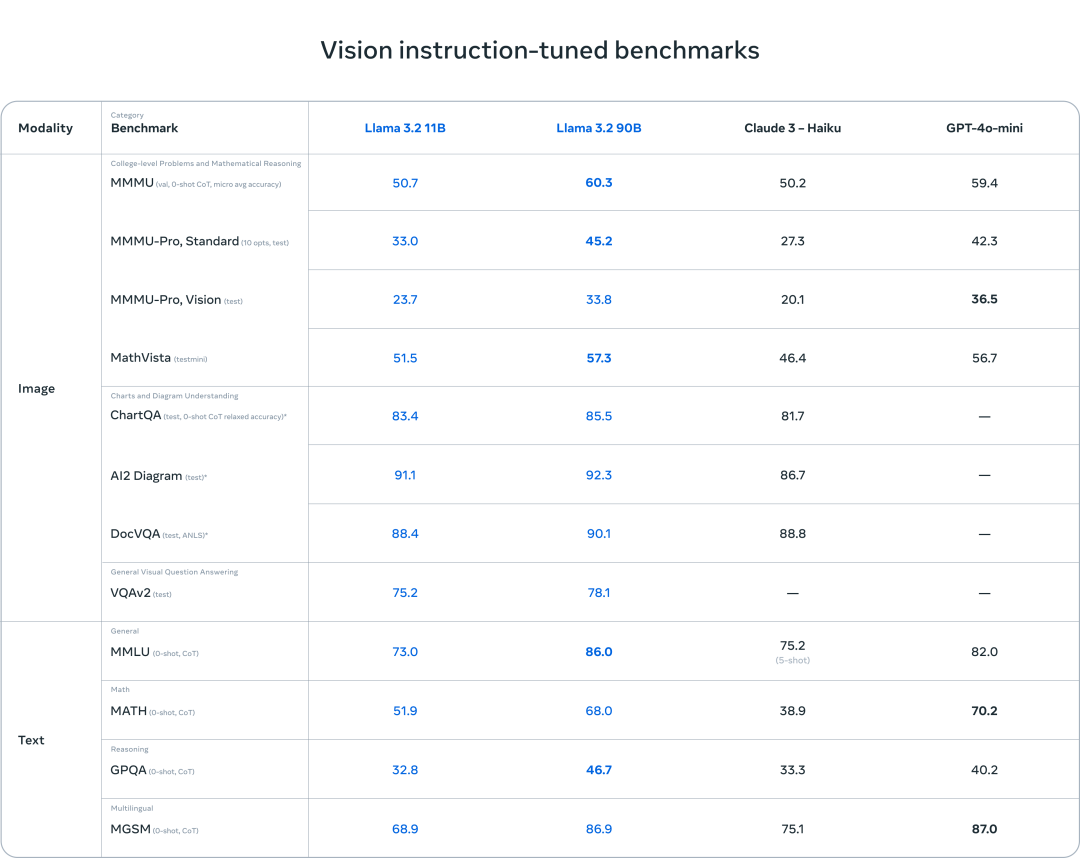
多模态模型效果
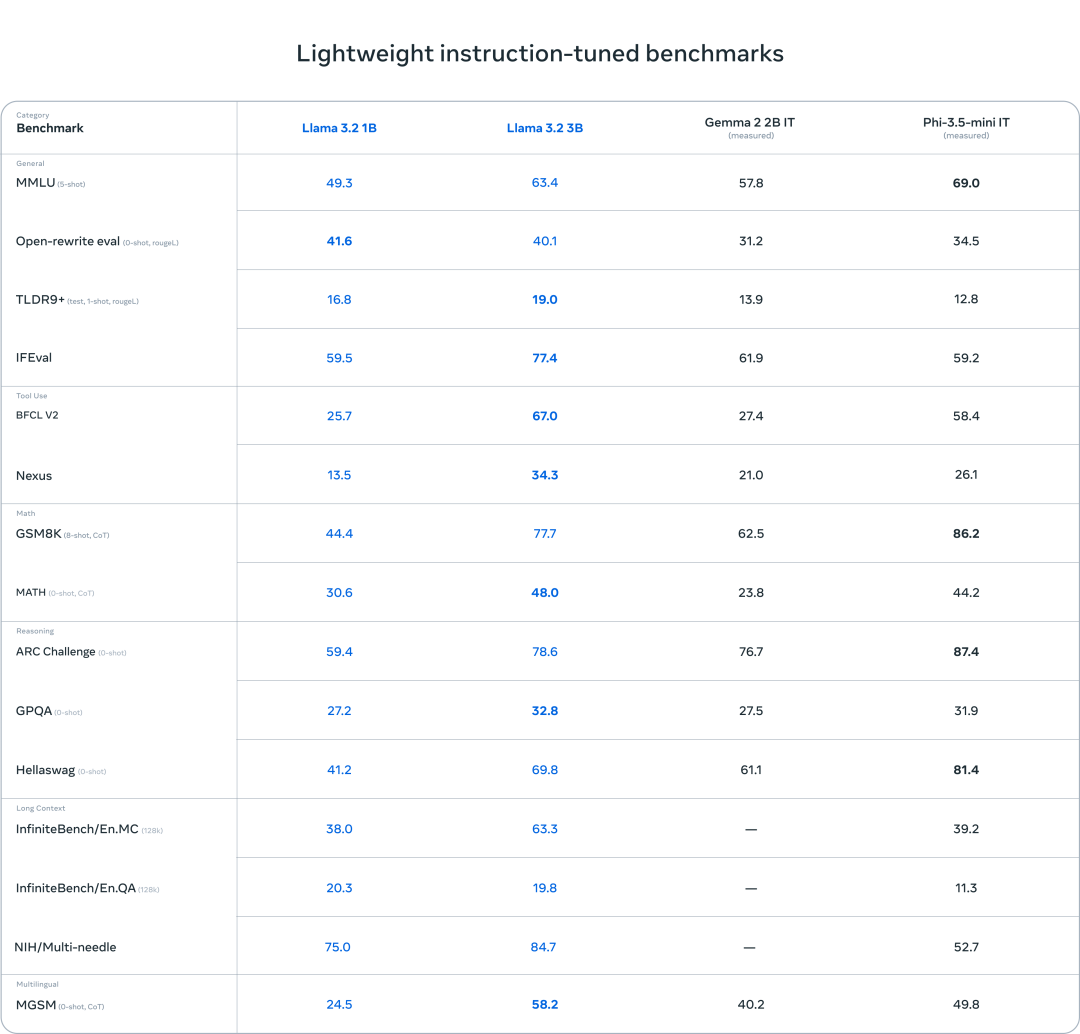
端侧模型效果
多模态模型
Llama3.2的11B和90B模型多模态是基于Llama3.1-8B、70B文本模型上,增量增加图像模型。
pretrain阶段:
-
文本模块由Llama3.1模型初始化,并初始化图像编码器,利用大规模噪声(图像、文本、6B数据对)对数据进行预训练
-
再用中等规模的高质量的领域、知识增强的(图像、文本、3M数据对)数据预训练。
posting-train阶段:
-
通过监督微调、拒绝采样和直接偏好优化进行多轮对齐
-
使用 Llama 3.1 模型 过滤和增强 图像上的问题和答案,利用合成数据生成和奖励模型对所有候选答案打分排序,获取高质量的微调数据
-
还添加了安全数据
端侧小模型
1B和3B模型都是基于8B模型裁剪后进行模型初始化,并且利用8B和70B模型进行模型蒸馏,9T数据预训练。
特别注意,这里蒸馏不是那种通过更大模型进行数据生成的蒸馏,而是再模型训练阶段,利用8B 和 70B 模型输出的 logits 影响模型loss,也就是传统的蒸馏方法。
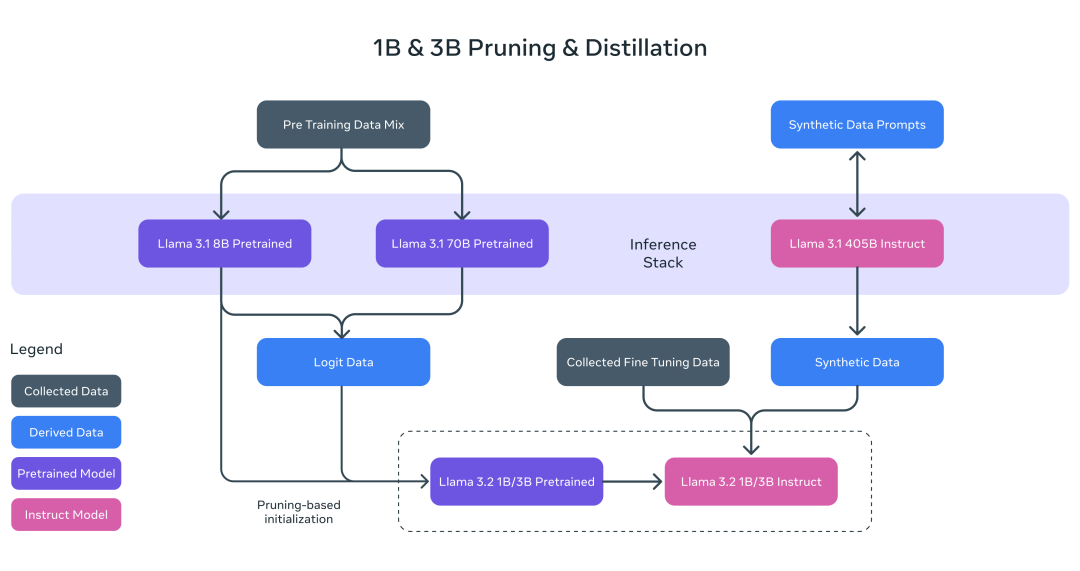
在post-traning阶段,训练方式语Llama3.1一致,采样监督微调、拒绝采样和直接偏好优化模型。
最后模型支持上下文扩展到 128K 个,同时也针对性优化了模型的多种能力,例如摘要、重写、指令遵循、语言推理和工具使用。
Llama Stack项目
Github: https://github.com/meta-llama/llama-stack
定义并标准化了将生成式 AI 应用程序推向市场所需的构建模块,跨越整个开发生命周期:从模型训练和微调,到评估,再到在生产环境中构建和运行AI Agent。
主要是为了简化开发人员在不同环境(包括单节点、本地、云和设备上)中使用 Llama 模型的方式,帮助快速实现检索增强生成、工具使用等能力的快速部署。

















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









