






在自然语言处理(NLP)领域,模型微调(Fine-Tuning)是提升预训练模型在特定任务上表现的关键步骤。本文将详细介绍如何使用 Hugging Face Transformers 库进行模型微调训练,涵盖数据集下载、数据预处理、训练配置、评估、训练过程以及模型保存。我们将以 YelpReviewFull 数据集为例,逐步带您完成模型微调训练的整个过程。
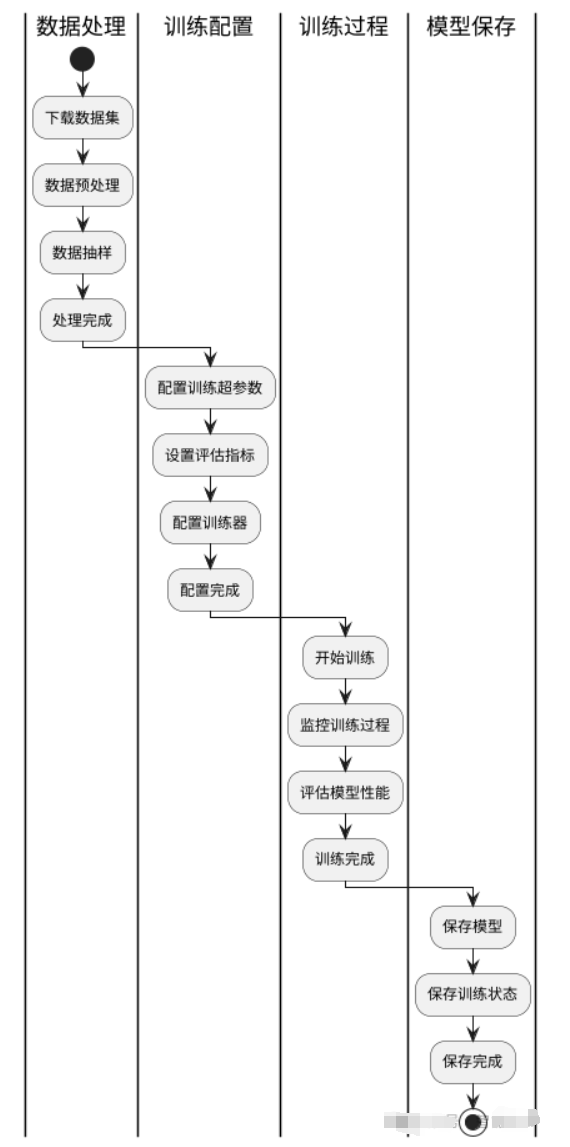

一、数据集下载
1、获取 YelpReviewFull 数据集
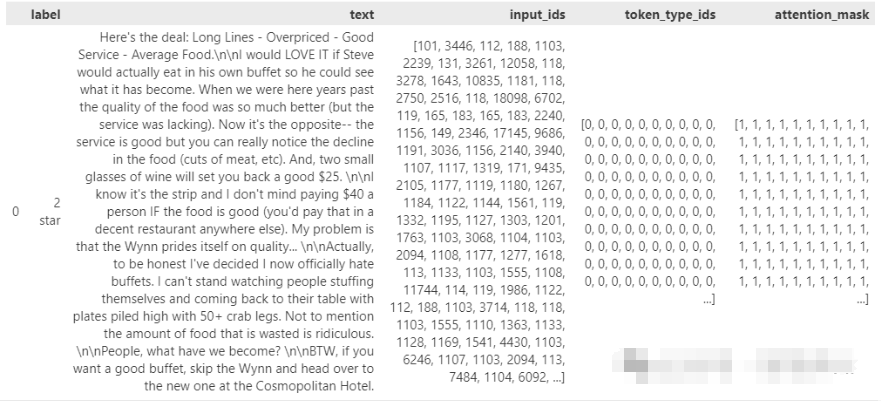
YelpReviewFull 数据集是一个经典的情感分析数据集,包含了大量来自 Yelp 的评论。数据集从 Yelp Dataset Challenge 2015 数据中提取,主要用于文本分类任务,目标是预测评论的情感分数。数据集的评论主要用英语编写,适合进行情感分类研究。
2、数据集结构与实例
数据集包含两个主要字段:
- text: 评论的文本内容。
- label: 评论的情感标签,范围从 1 到 5。
例如,一个典型的数据点如下:
{
'label': 0,
'text': 'I got \'new\' tires from them and within two weeks got a flat...'
}
3、数据拆分
数据集的总量为 700,000 条记录,其中包括 650,000 个训练样本和 50,000 个测试样本。在实际操作中,我们通常会将数据集随机拆分为训练集和测试集。例如,我们可以选择 130,000 个训练样本和 10,000 个测试样本用于模型训练和评估。
4、下载数据集代码
可以使用 Hugging Face 的 datasets 库来下载数据集:
from datasets import load_dataset
# 下载 YelpReviewFull 数据集
dataset = load_dataset("yelp_review_full")
二、数据预处理
1、数据预处理步骤
下载数据集后,我们需要对文本数据进行预处理,以便于模型的训练。预处理包括将文本转换为模型可以接受的输入格式。通常,我们使用 Tokenizer 对文本进行编码,并进行填充(padding)和截断(truncation)。
以下代码展示了如何使用 BERT Tokenizer 对数据集进行预处理:
from transformers import AutoTokenizer
# 加载预训练的 BERT Tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
"""
使用 Tokenizer 对文本进行编码,并进行填充和截断
"""
return tokenizer(examples["text"], padding="max_length", truncation=True)
# 对数据集进行预处理
tokenized_datasets = dataset.map(tokenize_function, batched=True)
2、数据抽样
在训练过程中,为了更好地控制训练过程,我们可以从数据集中抽样出一部分数据进行测试。例如,选择 1000 个样本进行小规模训练:
# 从数据集中抽样 1000 个训练样本
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
# 从数据集中抽样 1000 个测试样本
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
三、训练评估指标设置
1、微调训练配置
在微调模型之前,我们需要配置训练参数,包括加载模型和设置训练超参数。以下代码展示了如何加载 BERT 模型,并为情感分类任务配置输出标签数量:
from transformers import AutoModelForSequenceClassification
# 加载 BERT 模型,并设置标签数量为 5(情感评分从 1 到 5)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
2、训练超参数配置(TrainingArguments)
我们使用 TrainingArguments 来配置训练超参数。这些参数包括训练批次大小、训练轮数、日志记录频率等。以下是一个示例配置:
from transformers import TrainingArguments
model_dir = "models/bert-base-cased-finetune-yelp"
# 配置训练参数
training_args = TrainingArguments(
output_dir=model_dir, # 模型保存路径
per_device_train_batch_size=16, # 每个设备的训练批次大小
num_train_epochs=5, # 训练轮数
logging_steps=100 # 每 100 步记录一次日志
)
四、训练器基本介绍
1、训练指标评估
Hugging Face 提供了 evaluate 库来计算模型的评估指标。例如,我们可以使用准确率(accuracy)作为评估指标。以下代码展示了如何使用 evaluate 库计算模型的准确率:
import numpy as np
import evaluate
# 加载准确率指标
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""
计算准确率
"""
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1) # 将 logits 转换为预测值
return metric.compute(predictions=predictions, references=labels)
2、训练器(Trainer)
Trainer 类是 Hugging Face 提供的用于训练和评估模型的工具。我们需要将模型、训练参数、数据集以及计算指标的函数传递给 Trainer:
from transformers import Trainer
# 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset, # 训练数据集
eval_dataset=small_eval_dataset, # 验证数据集
compute_metrics=compute_metrics # 计算指标的函数
)
五、实战训练
1、训练过程中的指标监控
为了监控训练过程中的评估指标,我们可以配置 TrainingArguments 中的 evaluation_strategy 参数,以便在每个 epoch 结束时报告评估指标:
# 更新训练参数配置
training_args = TrainingArguments(
output_dir=model_dir,
evaluation_strategy="epoch", # 每个 epoch 结束时进行评估
per_device_train_batch_size=16,
num_train_epochs=3,
logging_steps=30 # 每 30 步记录一次日志
)
2、开始训练
使用 Trainer 类的 train 方法开始训练模型:
# 开始训练
trainer.train()
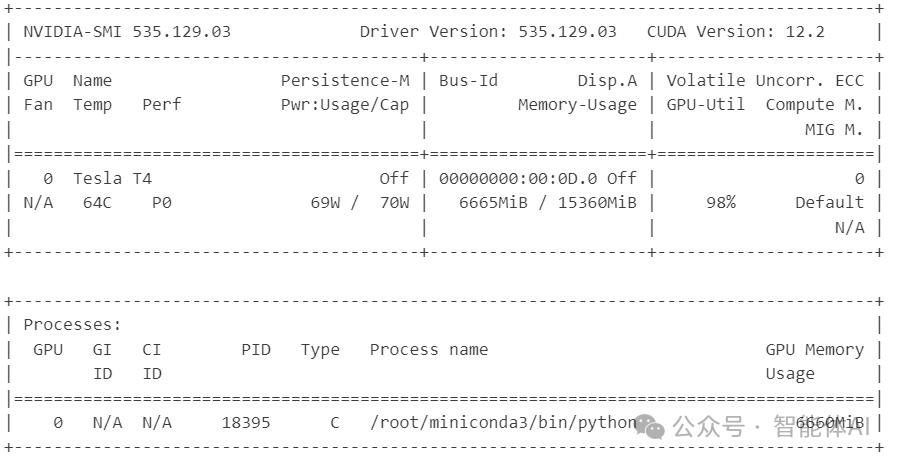
3、使用 nvidia-smi 监控 GPU 使用
在训练过程中,使用 nvidia-smi 命令监控 GPU 的使用情况,以确保训练过程的高效进行:
watch -n 1 nvidia-smi
六、模型保存
1、保存模型和训练状态
训练完成后,我们需要保存模型及其训练状态,以便后续加载和使用:
# 保存训练后的模型
trainer.save_model(model_dir)
# 保存训练状态
trainer.save_state()
通过 trainer.save_model 方法保存模型,您可以使用 from_pretrained() 方法重新加载模型。trainer.save_state() 方法保存训练状态,便于后续继续训练或评估。
七、完整代码汇总
下面是包含所有步骤的完整代码示例:
# 导入必要的库
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
import numpy as np
import evaluate
# 数据集下载
dataset = load_dataset("yelp_review_full")
# 数据预处理
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
def tokenize_function(examples):
"""
使用 Tokenizer 对文本进行编码,并进行填充和截断
"""
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 数据抽样
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
# 模型加载与训练配置
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
model_dir = "models/bert-base-cased-finetune-yelp"
training_args = TrainingArguments(
output_dir=model_dir,
per_device_train_batch_size=16,
num_train_epochs=5,
logging_steps=100
)
# 指标评估
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
"""
计算准确率
"""
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# 实例化 Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics
)
# 开始训练
trainer.train()
# 监控 GPU 使用
# 使用命令行工具: watch -n 1 nvidia-smi
# 保存模型和训练状态
trainer.save_model(model_dir)
trainer.save_state()
八、总结
本文详细介绍了使用 Hugging Face Transformers 库进行模型微调训练的完整流程,包括数据集下载、数据预处理、训练配置、评估、训练过程和模型保存等步骤。希望这些信息能帮助您更好地进行模型微调,提高模型在特定任务上的表现。
如何学习大模型?
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方CSDN官方认证二维码,免费领取【
保证100%免费】

如有侵权,请联系删除

















 421
421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









