







 该篇博客介绍了如何使用Python的requests和BeautifulSoup库爬取豆瓣电影Top250的电影名称。通过设置请求头模拟浏览器访问,逐页抓取电影信息,并存储到列表中。博客详细展示了爬虫的实现过程,包括获取网页源码、解析HTML以及状态码的检查。
该篇博客介绍了如何使用Python的requests和BeautifulSoup库爬取豆瓣电影Top250的电影名称。通过设置请求头模拟浏览器访问,逐页抓取电影信息,并存储到列表中。博客详细展示了爬虫的实现过程,包括获取网页源码、解析HTML以及状态码的检查。
当你找不到电影看的时候,收藏此篇,方便看。
import requests
from bs4 import BeautifulSoup
def get_movies():
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36',
'Host': 'movie.douban.com'
}
movie_list = []
for i in range(0,10):
link = 'https://movie.douban.com/top250?start=' + str(i * 25)
r = requests.get(link, headers=headers, timeout=10)
print(str(i+1), "页响应状态码:", r.status_code)
soup = BeautifulSoup(r.text, "lxml")
div_list = soup.find_all('div', class_='hd')
for each in div_list:
movie = each.a.span.text.strip()
movie_list.append(movie)
return movie_list
movies = get_movies()
print(movies)
我们一点一点的来解析一下:
1,获取网页响应头
打开Google Chrome,输入网址:豆瓣电影 Top 250 https://movie.douban.com/top250在页面右键点击检查
https://movie.douban.com/top250在页面右键点击检查

进入下面的控制台中,按以下步骤,如果点击All,发现没有东西,可以点击Ctrl+R:
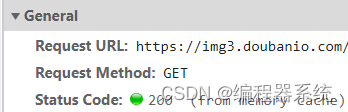
Request 获取方式为GET,Status Code输出200,状态码正常,获得
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
第一页的网址为:https://movie.douban.com/top250
第二页的网址为:https://movie.douban.com/top250?start=25&filter=
第三页的网址为:https://movie.douban.com/top250?start=50&filter=
我们可以看到在start后面是以此增加25,网页我们就可以以这样的办法来表示:
'https://movie.douban.com/top250?start=' + str(i * 25)
我们添加上页响应状态码,方便观察爬取进度:
str(i+1), "页响应状态码:", r.status_code
如下图显示:

右键点击网页源码:

最后将得到的电影目录放进列表中,得到:



















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











