









引言
近期,我着手对我的代码进行了全面的整理与优化,特别是对之前开发的一个分类项目进行了大幅度的重构。除此之外,我还采用了PyQt框架设计了一个直观的用户界面。这次整改不仅是对代码结构的优化,更是对过往开发经验的深刻反思。
在初次涉足深度学习项目时,我倾向于采用一些较为复杂的组织方式,比如利用YAML文件、配置文件或是嵌套函数等。然而,随着经验的积累,我逐渐意识到这些做法虽然对于开发者本人来说可能暂时清晰,但对于其他想要理解或使用项目的人来说,却可能构成不小的障碍。
因此,在本次整改中,我刻意避免了这些复杂的组织方式,力求使代码结构更加清晰、易于理解。如果你有幸成为第一个接触到这个优化后项目的人,那么我相信你将能够节省大量宝贵的时间,避免走我过去走过的弯路。
项目直达车:Auorui/pytorch-classification-Auorui: 一个基于pytorch的分类训练模版
视频教程:基于Pytorch的图像分类系统,最适合初学者的项目
项目简介
一个基于pytorch的分类训练模版
此项目提供了一个清晰且高效的基于PyTorch的图像分类训练模板,旨在简化二分类和多分类任务的实现过程。 无论是初学者还是有一定经验的开发者,都可以通过这个模板快速上手并构建自己的图像分类模型。
-
二分类和多分类:每个样本只能属于一个类别。二分类是特殊的多分类任务,类别数为2。多分类通过softmax来选择一个最可能的类别。
-
多标签:每个样本可以同时属于多个类别,每个标签的预测是独立的,通常需要sigmoid输出每个标签的概率值。这带来了标签间的依赖问题,需要考虑标签的相关性。
本项目仅支持二分类和多分类任务,在多标签任务中,模型需要为每个标签分别进行预测,并在训练过程中计算更多的梯度, 这可能会增加计算复杂度和训练时间。更重要的是我目前遇到的都是二分类和多分类,关于多标签的任务没有遇到过。
分类数据集加载与预处理
关于数据集的目录结构,请按照此处讲解。这里有一个小建议就是,将我提供的示例数据集跑通之后再替换自己的数据集。
在项目当中我提供的数据增强方式有resize pad,随机水平翻转,随机90度旋转以及随机颜色抖动。在验证集中只做了resize pad,因为验证集并不需要做什么数据增强,只需要保证输入网络的图像大小是相同的就可以了。如下所示:
def class_augument(self, image, target_shape, is_train, prob=.5):
h, w = target_shape
ih, iw = image.shape[:2]
scale = min(w / iw, h / ih)
nw = int(iw * scale)
nh = int(ih * scale)
resized_image = cv2.resize(image, (nw, nh), interpolation=cv2.INTER_CUBIC)
new_image = np.full((h, w, 3), (128, 128, 128), dtype=np.uint8)
top = (h - nh) // 2
left = (w - nw) // 2
new_image[top:top + nh, left:left + nw] = resized_image
new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB)
if is_train:
if random.random() > (1 - prob):
new_image = np.flip(new_image, axis=1)
r = random.randint(0, 3)
new_image = np.rot90(new_image, r, (0, 1))
# 转换到HSV颜色空间
hsv_image = cv2.cvtColor(new_image, cv2.COLOR_RGB2HSV).astype(np.float32)
h_channel, s_channel, v_channel = cv2.split(hsv_image)
# 随机调整色调(Hue)
delta_h = random.randint(-30, 30)
h_channel = (h_channel + delta_h) % 180
# 随机调整饱和度(Saturation)和亮度(Value)
s_scale = np.random.uniform(0.5, 1.5)
v_scale = random.uniform(0.5, 1.5)
s_channel = np.clip(s_channel * s_scale, 0, 255).astype(np.uint8)
v_channel = np.clip(v_channel * v_scale, 0, 255).astype(np.uint8)
# 合并通道并转换回RGB颜色空间
hsv_image[..., 0] = h_channel.astype(np.uint8)
hsv_image[..., 1] = s_channel
hsv_image[..., 2] = v_channel
new_image = cv2.cvtColor(hsv_image.astype(np.uint8), cv2.COLOR_HSV2RGB)
# 将图像归一化到[0, 1]范围
new_image = new_image / 255.0
return new_image这里我还提供了经过数据增强,数据加载器后,再还原回图像的函数。以前是没有这个习惯的,但有过几次经验教训后,我发现训练不收敛大多数情况是数据集的问题。这里我就举几个例子,在做去雾任务的时候,我的gt图像大小为620和460,而我的hazy图像大小为640和480,我当时采取的数据增强策略不是resize pad,而是随机裁剪,这就导致了我的图像虽然大小一样,但是指标却上不去,如果不是后面将经过数据加载器后还原回图像,这还真发现不出来。再比如做分割任务的时候,将标签的顺序弄混了,导致最终预测的不太对。
def show_image_from_dataloader(test_dataset):
loader = DataLoader(
test_dataset,
batch_size=1,
shuffle=True,
num_workers=1,
pin_memory=False,
drop_last=True
)
for i, (img, label) in enumerate(loader):
img = img[0].numpy()
img = np.transpose(img, (1, 2, 0))
img = (img*255).astype(np.uint8)
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
cv2.putText(img, f"{label.item()}", (30, 30), fontFace=cv2.FONT_HERSHEY_SIMPLEX,
fontScale=1, thickness=2, color=(255, 0, 255))
cv2.imshow('show image from dataloader', img)
cv2.waitKey(0)
cv2.destroyAllWindows()这里的使用方法很简单,就只需要将dataset示例化后传入这个函数就可以了。下面我们来看一看经过数据加载器后还原回的图像。

这种是高和宽都是相同的情况,所以没有pad,只有resize的效果。
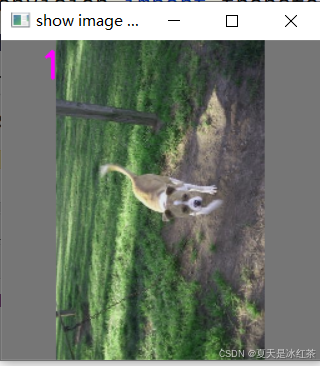
这种就是高和宽不相同的情况,如果直接使用resize,会导致它的的宽进行拉伸,导致图像的失真,当前在图像分类中没什么关系,但对于如分割任务就会有一定的影响了。
除此之外,你可以使用torchvision的transformer,这里我给大家提供一个参考:
transform = transforms.Compose([
transforms.ToPILImage(), # convert numpy to PIL image
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomRotation(degrees=90),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomResizedCrop(size=(256, 256)),
transforms.PILToTensor()
])
train_dataset = ClassificationDataset(root_dir=data_path, target_shape=[256, 256], is_train=True,
transform=transform)对于标签的处理,为了确保顺序的一致性,我对其组成的列表进行了自然排序。
self.categories = natsorted(os.listdir(data_folder))然后将其转换为整型的tensor就可以了。
label = torch.tensor(label).long()损失函数
在图像分类任务中,损失函数的选择对模型的性能至关重要。通常,二分类任务和多分类任务会使用不同的损失函数。例如,二分类任务常用 BCEWithLogitsLoss,而多分类任务则常用 CrossEntropyLoss。然而,由于 BCEWithLogitsLoss 的输入参数要求与我们的数据集加载方式不完全匹配,因此我们选择了一种更灵活的联合损失函数方法。
为了适应不同的分类任务,我们采用了以下策略:
- 二分类任务:使用 FocalLoss 和 CrossEntropyLoss 的联合损失。
- 多分类任务:使用 DiceLoss 和 CrossEntropyLoss 的联合损失。
def get_criterion(num_classes=None, alpha=.5, beta=None):
"""
根据任务类型(二分类或多分类)选择合适的损失函数。
二分类常用的是BCEWithLogitsLoss,但这个函数的输入参数要求与我们的这个dataset载入的不太一样,所以这里放弃使用
这里采用的是联合损失,你可以自己随机组合,也可以只使用 celoss
"""
if num_classes is None:
criterion = nn.CrossEntropyLoss()
else:
if num_classes == 2:
# criterion = nn.BCEWithLogitsLoss() # 二分类通常使用 BCEWithLogitsLoss
criterion = Joint2Loss(nn.CrossEntropyLoss, FocalLoss, alpha=alpha, beta=beta)
elif num_classes > 2:
criterion = Joint2Loss(nn.CrossEntropyLoss, DiceLoss, alpha=alpha, beta=beta) # 多分类使用 CrossEntropyLoss
else:
raise ValueError("num_classes must be greater than or equal to 2")
return criterion联合损失函数的优势在于,它能够同时考虑模型的多种优化目标,帮助提高训练的效果。比如,我们可以在处理极度不平衡数据时,使用 FocalLoss 来关注难分类样本,同时通过 CELoss 维持全局的分类效果。
当然,在此处你可以根据自己的任务需求灵活调整损失函数的组合,以达到最佳效果。
优化器与学习率调度器
优化器能够控制模型权重的更新方式,关于这块其实我自己也只用过sgd,adam,adamw,其他的没有过也不怎么了解。
以下是获取优化器的代码示例:
def get_optimizer(
network, optimizer_type = 'adam', init_lr = 0.001, momentum = 0.9, weight_decay = 1e-4
):
"""
返回指定优化器及学习率调度器。
Args:
network (torch.nn.Module): 模型网络。
optimizer_type (str): 优化器类型,支持 'sgd', 'adam', 'adamw'。
init_lr (float): 初始学习率。
momentum (float): 动量(SGD专用)。
weight_decay (float): 权重衰减。
Returns:
optimizer, scheduler: 返回优化器和学习率调度器。
"""
# 选择优化器
if optimizer_type in ['sgd', 'SGD']:
optimizer = optim.SGD(network.parameters(), lr = init_lr, momentum = momentum,
weight_decay = weight_decay)
elif optimizer_type in ['adam', 'Adam']:
optimizer = optim.Adam(network.parameters(), lr = init_lr,
weight_decay = weight_decay)
elif optimizer_type in ['adamw', 'AdamW']:
optimizer = optim.AdamW(network.parameters(), lr = init_lr,
weight_decay = weight_decay)
else:
raise ValueError(f"Optimizer {optimizer_type} is not supported.")
return optimizer学习率调度器可以帮助我们在训练过程中动态调整学习率,以便更好地训练模型。常用的调度器有以下几种:
StepLR:每隔 step_size 个epoch降低一次学习率,适用于训练稳定但需要逐渐减小学习率的任务。
MultiStepLR:在指定的epoch时刻降低学习率,适用于在特定阶段需要显著调整学习率的任务。
CosineAnnealingLR:使用余弦退火策略,逐步减小学习率,适用于训练过程中需要平滑衰减的任务。
Warmup:在训练初期使用线性增加的学习率,帮助模型更好地进行预热,适用于模型初期训练不稳定的情况。
以下是获取学习率调度器的代码示例:
def get_lr_scheduler(
optimizer, scheduler_type='step', total_epochs=100,
warmup_steps=None, milestones=None, gamma=0.75
):
"""
根据指定的调度策略返回学习率调度器。
Args:
optimizer: 优化器
scheduler_type: 学习率调度器类型,支持 'step', 'multistep', 'cos', 'warmup'
total_epochs: 训练总轮数,仅在 'cos' 调度器时使用
warmup_steps: warmup步数,仅在 'warmup' 调度器时使用
milestones: 多步下降的关键点列表,仅在 'multistep' 调度器时使用
gamma: 学习率下降的倍率,默认是 0.1
Returns:
scheduler: 学习率调度器
"""
if scheduler_type == 'step':
# StepLR: 每隔 step_size epoch 学习率下降一次
scheduler = StepLR(optimizer, step_size = 30, gamma = gamma)
elif scheduler_type == 'multistep':
# MultiStepLR: 在指定的 milestones(epoch 列表) 时学习率下降
if milestones is None :
# 如果没有提供 milestones,就平均分配
milestones = [total_epochs // 5 * i for i in range(1, 5)]
# print(milestones)
scheduler = MultiStepLR(optimizer, milestones = milestones, gamma = gamma)
elif scheduler_type == 'cos':
# CosineAnnealingLR: 余弦退火调度
scheduler = CosineAnnealingLR(optimizer, T_max=total_epochs)
elif scheduler_type == 'warmup':
# Linear warmup: 线性增加学习率,直到达到 warmup_steps
if warmup_steps is None:
warmup_steps = int(total_epochs * 0.25)
if warmup_steps <= 0:
raise ValueError("For 'warmup' scheduler, 'warmup_steps' must be greater than 0.")
scheduler = WarmUp(optimizer, warmup_steps)
else:
raise ValueError(f"Scheduler type '{scheduler_type}' is not supported.")
return scheduler这里通过参数选择的方式,你可以灵活地选择适合的优化器和学习率调度策略,帮助模型更高效地训练。
混淆矩阵与常见分类评价指标
在机器学习与深度学习的分类任务中,评估模型的性能是至关重要的一步。除了传统的准确率(Accuracy)外,还有许多其他指标可以帮助我们更加全面地了解模型的表现,比如精确率(Precision)、召回率(Recall)、F1分数、AUC等。这里将介绍一下如何使用PyTorch和torchmetrics库,结合混淆矩阵来计算这些常见的分类指标。
混淆矩阵是分类任务中最基本的评估工具之一。它展示了模型在各类标签上的预测结果。对于二分类任务,混淆矩阵通常包含四个值:
- TP:实际为正例且被正确预测为正例的样本数。
- FN:实际为正例但被错误预测为负例的样本数。
- FP:实际为负例但被错误预测为正例的样本数。
- TN:实际为负例且被正确预测为负例的样本数。
对于多分类任务,混淆矩阵则会变得稍微复杂,但同样通过行列交叉来表示真实类别和预测类别的对应情况。
在我提供的代码中,ConfusionMatrix类支持二分类和多分类任务,计算TP、FN、FP和TN,并能够将结果以热力图的形式可视化。
早些时候写过关于这部分的博客,可以看看:
class ConfusionMatrix(nn.Module):
def __init__(
self,
num_classes,
threshold=.5,
ignore_index=None,
):
super(ConfusionMatrix, self).__init__()
if num_classes == 2:
self.matrix = BinaryConfusionMatrix(threshold=threshold, ignore_index=ignore_index)
elif num_classes > 2:
self.matrix = MulticlassConfusionMatrix(num_classes=num_classes, ignore_index=ignore_index)
else:
raise ValueError(
"num_classes should be either 2 for binary classification or greater than 2 for multiclass classification.")
self.matrix.reset()
self.num_classes = num_classes
def update(self, preds, target):
self.matrix.update(preds, target)
@property
def get_matrix(self):
return self.matrix.compute()
def ravel(self):
confusion_matrix = self.matrix.compute()
metrics=np.zeros((4,))
if self.num_classes > 2:
for i in range(self.num_classes):
TP = confusion_matrix[i,i]
FN = torch.sum(confusion_matrix[i,:]).item() - TP
FP = torch.sum(confusion_matrix[:,i]).item() - TP
# 多分类任务中通常不计算TN,因为对于每个类别,其他所有类别都可以被视为“负类”,这使得TN的计算变得复杂且不直观
TN = torch.sum(confusion_matrix).item() - (TP + FN + FP)
metrics[0] += TP
metrics[1] += FN
metrics[2] += FP
metrics[3] += TN
else:
metrics = confusion_matrix.flatten().numpy()
return metrics
def plot_confusion_matrix(self, save_path="./class_confusionmatrix.png"):
cm = self.get_matrix
if self.num_classes == 2:
class_names=['Negative','Positive']
else:
class_names=[f'Class {i}' for i in range(self.num_classes)]
matplotlib.use('TkAgg')
plt.figure(figsize=(10, 7))
sns.heatmap(cm, annot=True, fmt='d',xticklabels=class_names,yticklabels=class_names,cmap='Blues')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title('Confusion Matrix')
if save_path:
plt.savefig(save_path)
print(f"Confusion matrix saved to {save_path}")
else:
plt.show()除了混淆矩阵,分类任务的性能评估还依赖于一系列常见的指标,关于这部分我就不做过多的介绍了,详细可以看看我提供的代码里面。
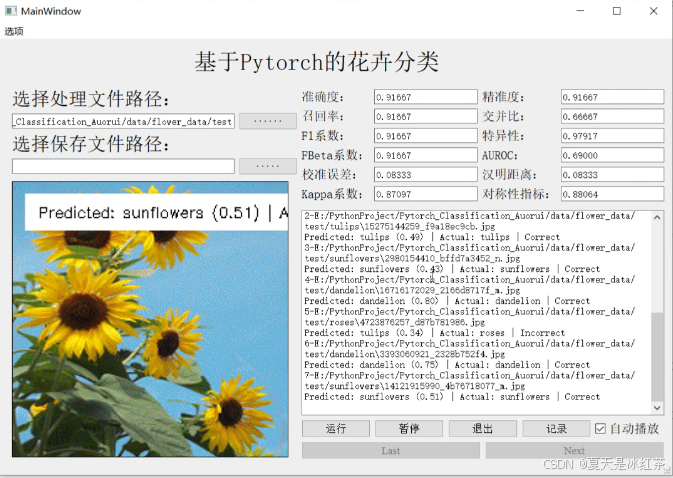
基于Pytorch的分类系统UI界面
下面的我ui界面是我在此篇当中进行修改的:图像与视频的加载与显示
UI界面的动图太大了,这里放不了,可以在视频讲解或仓库中查看,这里只是说明一下参数修改的问题。参数设置均在./runui.py当中, 你需要修改的有ui设计的界面名称, 输入大小, 类别, 网络模型以及训练好的权重。
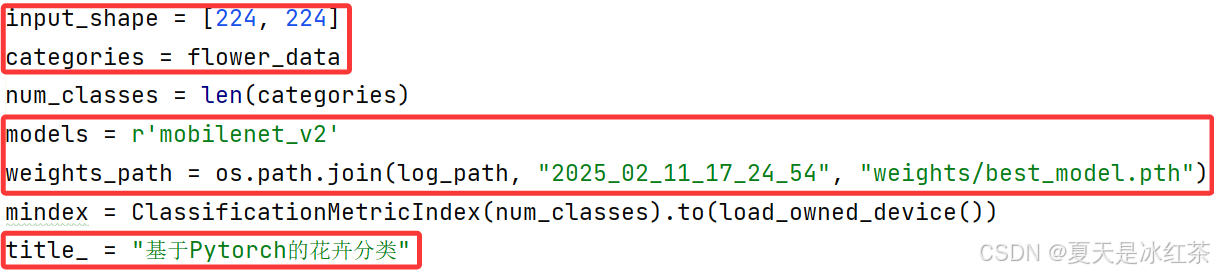
其中这里的输入大小要与你自己训练时候设置的一样。
总结
关于模型的训练和推理部分,请你严格按照仓库中的README.md文件来进行操作。博主是从图像处理领域开始学习,经过长时间的摸索和实践,才逐渐理清了整个流程。最初接触的是裂缝分割,那时我尚缺乏深度学习的实战经验,每一步都走得尤为艰难。很多细节和要点,只有亲自走一遍整个流程才能真正理解。这个项目既是为了记录博主自己的学习历程,也是因为博主非常喜欢“教学相长”的过程。这种感觉特别好,每次在帮助别人解决问题时,自己也会获得新的理解和成长。每一个小小的突破,都是自己学习的积累,而这些积累,最终会成为你迎接更大挑战的基础。



















 309
309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











