









简介
论文原址:1807.06521.pdf (arxiv.org)
CBAM(Convolutional Block Attention Module)是一种卷积神经网络模块,旨在通过引入注意力机制来提升网络的表示能力。CBAM包含两个顺序子模块:通道注意力模块和空间注意力模块。
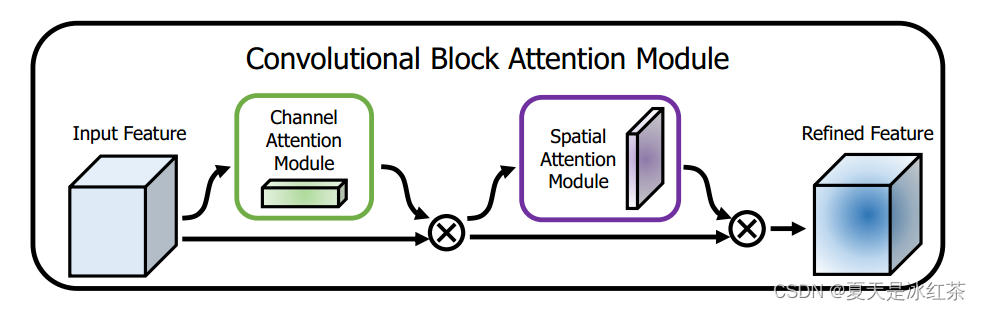
通过在深度网络的每个卷积块中自适应地优化中间特征图,CBAM通过强调通道和空间维度上的有意义特征,实现了对关键信息的关注和不必要信息的抑制。研究表明,CBAM在ImageNet-1K数据集上能够显著提高各种基线网络的准确性,通过grad-CAM可视化验证,CBAM增强的网络能够更准确地关注目标对象。在MS COCO和VOC 2007数据集上的目标检测任务中,CBAM也展现出显著的性能改进,而由于CBAM精心设计为轻量级模块,其在大多数情况下几乎没有参数和计算开销。CBAM注意力模块可广泛应用于提升卷积神经网络的表示能力。
Channel attention module(CAM)
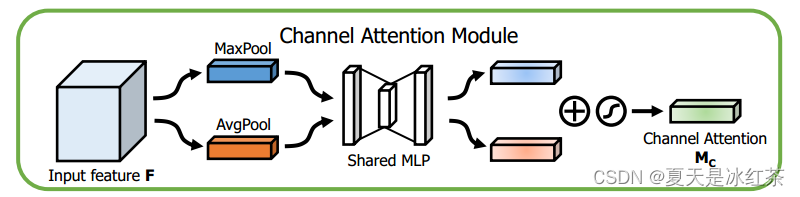
通过平均池化和最大池化操作,整合输入特征图的空间信息,生成两个不同的空间上下文描述符,得到两个 1×1×C 的特征图,分别表示为 F_c_avg 和 F_c_max。将 F_c_avg 和 F_c_max 分别送入一个共享的多层感知机(MLP),该 MLP 具有一个隐藏层,其中第一层神经元个数为 C/r(r 为减少率),激活函数为 ReLU,第二层神经元个数为 C。这两层神经网络是共享的,即它们的权重相同。将两个 MLP 的输出特征进行逐元素相加,并通过 sigmoid 激活函数,生成通道注意力图 Mc。

这是对池化操作的使用进行实验比较的结果。研究者发现,采用平均池化和最大池化并行的方式能够取得更好的效果。可能是因为采用并行连接方式,相比于单一的池化,能够更有效地保留有用的信息,进而提升模型性能。
Spatial attention module(SAM)
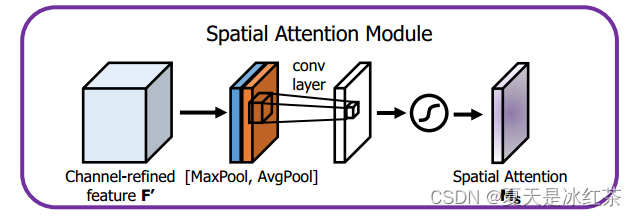
首先,将 Channel Attention 模块输出的特征图作为 Spatial Attention 模块的输入特征图。接着,对输入特征图进行基于通道的全局最大池化和全局平均池化操作,得到两个 H×W×1 的特征图。然后,将这两个特征图在通道维度上进行拼接,经过一个 7×7 的卷积操作,将通道数降维为 1,即得到 H×W×1 的特征图。最后,经过 sigmoid 操作生成空间注意力特征,即 Ms。将该特征与输入特征图进行乘法操作,得到最终生成的特征。这一过程有助于模型关注输入特征图中的重要区域,从而增强表示能力。
CBAM的pytorch实现
"""
Original paper addresshttps: https://arxiv.org/pdf/1807.06521.pdf
Time: 2024-02-28
"""
import torch
from torch import nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes, reduction=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
# shared MLP
self.mlp = nn.Sequential(
nn.Conv2d(in_planes, in_planes // reduction, 1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_planes // reduction, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.mlp(self.avg_pool(x))
max_out = self.mlp(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7, padding=3):
super(SpatialAttention, self).__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAM(nn.Module):
def __init__(self, in_planes, reduction=16, kernel_size=7):
super(CBAM, self).__init__()
self.ca = ChannelAttention(in_planes, reduction)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
out = x * self.ca(x)
result = out * self.sa(out)
return result
if __name__ == '__main__':
block = CBAM(16)
input = torch.rand(1, 16, 8, 8)
output = block(input)
print(output.shape)


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











