







前言
论文地址:https://arxiv.org/pdf/2103.00020
官方代码:openai/CLIP: CLIP (Contrastive Language-Image Pretraining)
本项目代码:https://github.com/Auorui/clip_pytorch
CLIP的是由 OpenAI 开发的一种多模态模型,能够将图像和文本嵌入到同一个语义空间中进行处理,使用4亿个图像和文本对数据进行训练,通过对比学习的方式学习图像和文本之间的对齐关系。接下来,本文将梳理一下CLIP的原理以及使用流程。
CLIP模型
CLIP的思想还是比较容易的,接下来我们按照这下面的图来讲解,在下图的左边是训练过程,他这里一共有两个模态,分别为文本模态和视觉模态,对应图中的Text Encoder和Image Encoder,分别对其信息进行编码得到文本特征向量和图像特征向量,然后两个向量做相似度计算,其中和图像对应的文本为正相关样本,和图像不对应的文本为负相关样本。CLIP用的是余弦相似度计算,使正样本的余弦相似度尽可能接近1,使负样本的余弦相似度尽可能的解决0,CLIP的基本原理就是对比学习,通过对比让学习区分正样本和负样本。
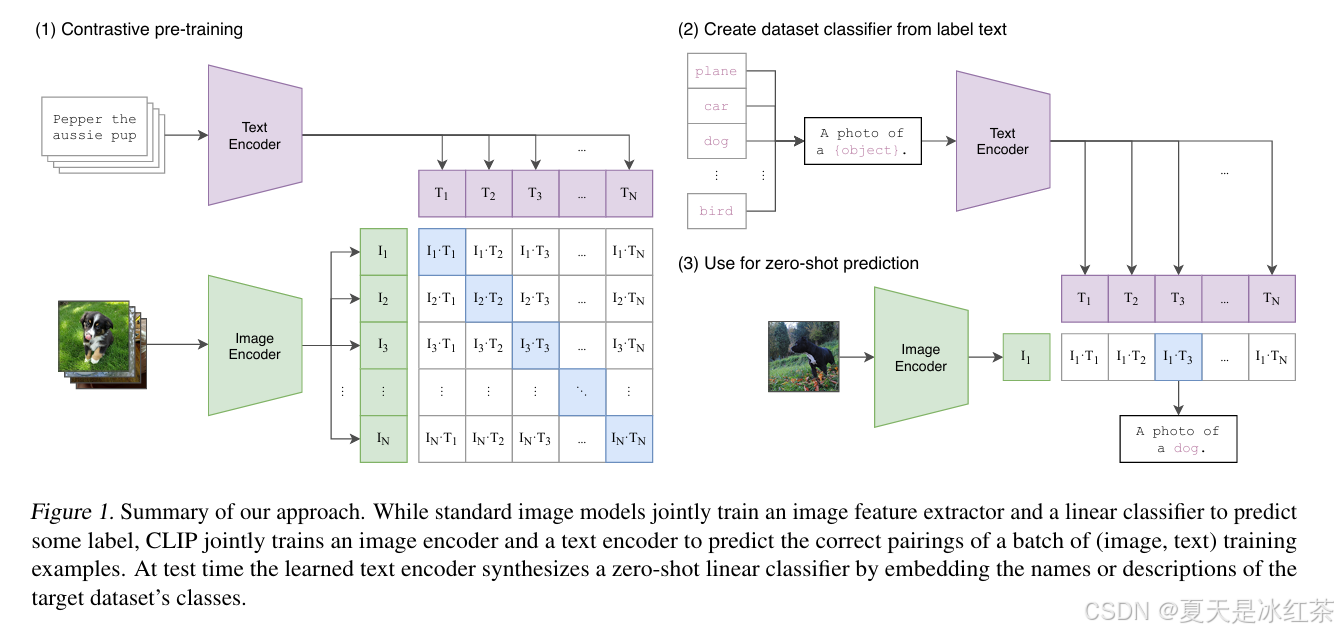
下面是CLIP模型的代码:
from typing import Tuple, Union
import numpy as np
import torch
from torch import nn
from models.bert import Transformer
from models.vit import VisionTransformer
from models.resnet import ModifiedResNet
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
def forward(self, x: torch.Tensor):
orig_type = x.dtype
ret = super().forward(x.type(torch.float32))
return ret.type(orig_type)
class CLIP(nn.Module):
def __init__(self,
embed_dim: int = 512,
# vision
image_resolution: int = 224,
vision_layers: Union[Tuple[int, int, int, int], int] = 12,
vision_width: int = 768,
vision_patch_size: int = 32,
# text
context_length: int = 77,
vocab_size: int = 49408,
transformer_width: int = 768,
transformer_heads: int = 12,
transformer_layers: int = 12
):
super().__init__()
self.context_length = context_length
if isinstance(vision_layers, (tuple, list)):
vision_heads = vision_width * 32 // 64
self.visual = ModifiedResNet(
layers=vision_layers,
output_dim=embed_dim,
heads=vision_heads,
input_resolution=image_resolution,
width=vision_width
)
else:
vision_heads = vision_width // 64
self.visual = VisionTransformer(
input_resolution=image_resolution,
patch_size=vision_patch_size,
width=vision_width,
layers=vision_layers,
heads=vision_heads,
output_dim=embed_dim
)
self.transformer = Transformer(
width=transformer_width,
layers=transformer_layers,
heads=transformer_heads,
attn_mask=self.build_attention_mask()
)
self.vocab_size = vocab_size
self.token_embedding = nn.Embedding(vocab_size, transformer_width)
self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))
self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.initialize_parameters()
def initialize_parameters(self):
nn.init.normal_(self.token_embedding.weight, std=0.02)
nn.init.normal_(self.positional_embedding, std=0.01)
if isinstance(self.visual, ModifiedResNet):
if self.visual.attnpool is not None:
std = self.visual.attnpool.c_proj.in_features ** -0.5
nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)
nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:
for name, param in resnet_block.named_parameters():
if name.endswith("bn3.weight"):
nn.init.zeros_(param)
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)
attn_std = self.transformer.width ** -0.5
fc_std = (2 * self.transformer.width) ** -0.5
for block in self.transformer.resblocks:
nn.init.normal_(block.attn.in_proj_weight, std=attn_std)
nn.init.normal_(block.attn.out_proj.weight, std=proj_std)
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
if self.text_projection is not None:
nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
def build_attention_mask(self):
# lazily create causal attention mask, with full attention between the vision tokens
# pytorch uses additive attention mask; fill with -inf
mask = torch.empty(self.context_length, self.context_length)
mask.fill_(float("-inf"))
mask.triu_(1) # zero out the lower diagonal
return mask
@property
def dtype(self):
return self.visual.conv1.weight.dtype
def encode_image(self, image):
return self.visual(image.type(self.dtype))
def encode_text(self, text):
x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]
x = x + self.positional_embedding.type(self.dtype)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_final(x).type(self.dtype)
# x.shape = [batch_size, n_ctx, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection
return x
def forward(self, image, text):
image_features = self.encode_image(image)
text_features = self.encode_text(text)
# normalized features
image_features = image_features / image_features.norm(dim=1, keepdim=True)
text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_image = logit_scale * image_features @ text_features.t()
logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size]
return logits_per_image, logits_per_text
def convert_weights(model: nn.Module):
"""Convert applicable model parameters to fp16"""
def _convert_weights_to_fp16(l):
if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):
l.weight.data = l.weight.data.half()
if l.bias is not None:
l.bias.data = l.bias.data.half()
if isinstance(l, nn.MultiheadAttention):
for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:
tensor = getattr(l, attr)
if tensor is not None:
tensor.data = tensor.data.half()
for name in ["text_projection", "proj"]:
if hasattr(l, name):
attr = getattr(l, name)
if attr is not None:
attr.data = attr.data.half()
model.apply(_convert_weights_to_fp16)
def build_model(state_dict: dict):
if "visual.proj" in state_dict:
vision_width = state_dict["visual.conv1.weight"].shape[0]
vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])
vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]
grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)
image_resolution = vision_patch_size * grid_size
else:
counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]
vision_layers = tuple(counts)
vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]
output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)
vision_patch_size = None
assert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]
image_resolution = output_width * 32
embed_dim = state_dict["text_projection"].shape[1]
context_length = state_dict["positional_embedding"].shape[0]
vocab_size = state_dict["token_embedding.weight"].shape[0]
transformer_width = state_dict["ln_final.weight"].shape[0]
transformer_heads = transformer_width // 64
transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith("transformer.resblocks")))
model = CLIP(
embed_dim,
image_resolution, vision_layers, vision_width, vision_patch_size,
context_length, vocab_size, transformer_width, transformer_heads, transformer_layers
)
for key in ["input_resolution", "context_length", "vocab_size"]:
if key in state_dict:
del state_dict[key]
convert_weights(model)
model.load_state_dict(state_dict)
return model.eval()Image Encoder
图像编码器Image Encoder是基于VIT模型,关于VIT的一些知识可以参考我之前写的博客:Vision Transformer模型详解(附pytorch实现)。
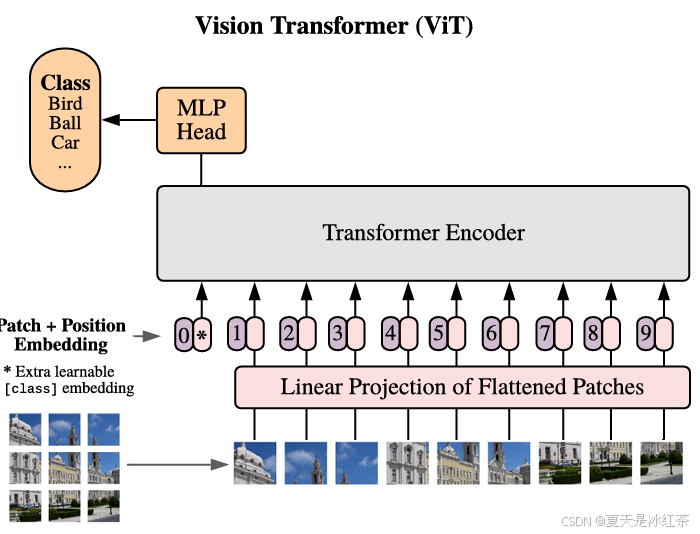
在VIT当中,对输入进来的图片进行分块处理,每隔一定的区域大小划分图片块。然后将划分后的图片块组合成序列,通常采用卷积去完成,步长设置为16,卷积核也设置为16,卷积会每隔16个像素进行一次像素点提取,那么此时一个224x224x3的图像就会得到14x14x768的特征层,将前两个维度展平之后就是196x768的特征层。
平铺完成后,在序列开头插入一个可学习的[CLS]标记,用于聚合全局图像特征(最终用该标记作为图像特征向量)。然后为每个图像块添加可学习的位置编码,保留空间位置信息,与NLP中的Transformer不同,ViT的位置编码是随机初始化并学习的。
from collections import OrderedDict
import torch
from torch import nn
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
def forward(self, x: torch.Tensor):
orig_type = x.dtype
ret = super().forward(x.type(torch.float32))
return ret.type(orig_type)
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
return x * torch.sigmoid(1.702 * x)
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)
class VisionTransformer(nn.Module):
def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):
super().__init__()
self.input_resolution = input_resolution
self.output_dim = output_dim
self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)
# 224, 224, 3 -> 196, 768
scale = width ** -0.5
self.class_embedding = nn.Parameter(scale * torch.randn(width))
# 196, 768 -> 197, 768 类别编码
self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))
# 197, 768 -> 197, 768 位置编码
self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width)
self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor):
x = self.conv1(x) # shape = [*, width, grid, grid]
x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]
x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]
x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]
x = x + self.positional_embedding.to(x.dtype)
x = self.ln_pre(x)
x = x.permute(1, 0, 2) # NLD -> LND
x = self.transformer(x)
x = x.permute(1, 0, 2) # LND -> NLD
x = self.ln_post(x[:, 0, :])
if self.proj is not None:
x = x @ self.proj
return xText Encoder
文本编码器Text Encoder,是基于一个Transformer的编码器的模型,由12层的Transformer Encoder组成,由于文本信息相比于视觉信息更加简单,因此每一个规模的CLIP使用到的Text Encoder没有变化,大小都是一样的。
from collections import OrderedDict
import torch
import torch.nn as nn
class LayerNorm(nn.LayerNorm):
"""Subclass torch's LayerNorm to handle fp16."""
def forward(self, x: torch.Tensor):
orig_type = x.dtype
ret = super().forward(x.type(torch.float32))
return ret.type(orig_type)
class QuickGELU(nn.Module):
def forward(self, x: torch.Tensor):
return x * torch.sigmoid(1.702 * x)
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = LayerNorm(d_model)
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
class Transformer(nn.Module):
def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):
super().__init__()
self.width = width
self.layers = layers
self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])
def forward(self, x: torch.Tensor):
return self.resblocks(x)Text Encoder的宽度为512,num_head为8,层数为12,结构上也是经典的Attention加FFN前馈网络,编码器会对每个句子增加一个Class Token,用于整合特征,以一个固定长度向量来代表输入句子。一般会将Class Token放在第0位,也就是最前面。而在CLIP中,Class Token被放在了文本的最后。
zero-shot推理
以前的分类任务分类的类别是固定的,如果要更改类别的数量,就需要修改最后一层的类别数目num_classes。而给CLIP提供的标签是不固定的,可以是任何的内容,此外,提供的句子模板的选择很重要,论文当中还对prompt engineering进行了讨论,并且测试了很多种类的句子模板。

提供给网络的分类标签可以数量不固定,而且可以是任意内容。如果提供两个标签,就是二分类问题,提供100个标签,就是100分类问题。CLIP摆脱了事先定好的分类标签。
import torch
from PIL import Image
import numpy as np
from models.clip_utils import load, tokenize
def zeroshot(image_path, text_language, model_pth):
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = load(model_pth, device=device) # 载入模型
image = preprocess(Image.open(image_path)).unsqueeze(0).to(device)
text = tokenize(text_language).to(device)
with torch.no_grad():
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
idx = np.argmax(probs, axis=1)
print("Label probs:", probs)
for i in range(image.shape[0]): # batch
id = idx[i]
print('{}:\t{}'.format(text_language[id], probs[i, id]))
print('image {}:\t{}'.format(i, [v for v in zip(text_language, probs[i])]))
if __name__=="__main__":
model_pth_path = r"E:\PythonProject\clip_pytorch\models\models_pth\ViT-B-16.pt"
image_path = "./R_mAP.png"
text_language = ["two line charts", "a schematic diagram", "a landscape photo", "a oil painting"]
zeroshot(image_path, text_language, model_pth_path)运行的结果如下所示:
Label probs: [[9.547376e-01 4.508087e-02 8.620646e-05 9.542132e-05]]
two line charts: 0.9547376036643982
image 0: [('two line charts', 0.9547376), ('a schematic diagram', 0.04508087), ('a landscape photo', 8.620646e-05), ('a oil painting', 9.542132e-05)]
项目代码
数据集采用的是flickr8k,通过网盘分享的文件:flickr8k.zip,直接解压到工程项目中即可
链接: flickr8k.zip,提取码: k7j7
项目地址:Auorui/clip_pytorch
flickr8k上进行微调
详细的训练和推理内容请看工程项目当中的README.md文件。
推理代码
import cv2
import torch
from PIL import Image
import numpy as np
import torch.nn as nn
from models.clip import train_clip_model
from models.clip_utils import tokenize
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize, InterpolationMode
class Predict(nn.Module):
def __init__(self, model_pth, target_shape=224):
super(Predict, self).__init__()
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.model = train_clip_model(model_pth, jit=False).to(self.device)
self.transform = Compose([
Resize(target_shape, interpolation=InterpolationMode.BICUBIC),
CenterCrop(target_shape),
ToTensor(),
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
def preprocess(self, image_path):
pil_image = Image.open(image_path).convert('RGB')
return self.transform(pil_image).unsqueeze(0)
def forward(self, image_path, text_language):
image = self.preprocess(image_path).float().to(self.device)
text = tokenize(text_language).to(self.device)
self.model.eval()
original_image = cv2.imread(image_path)
with torch.no_grad():
logits_per_image, logits_per_text = self.model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
idx = np.argmax(probs, axis=1)
print("Label probs:", probs)
for i in range(image.shape[0]): # batch
id = idx[i]
prediction = f"{text_language[id]}: {probs[i, id]:.2f}"
(text_width, text_height), baseline = cv2.getTextSize(prediction, cv2.FONT_HERSHEY_SIMPLEX, .8, 2)
text_x = (original_image.shape[1] - text_width) // 2
text_y = original_image.shape[0] - 10
cv2.putText(original_image, prediction, (text_x, text_y), cv2.FONT_HERSHEY_SIMPLEX, .8,
(255, 255, 255), 2, cv2.LINE_AA)
print(prediction)
print('image {}:\t{}'.format(i, [v for v in zip(text_language, probs[i])]))
cv2.imshow("predict opencv image", original_image)
cv2.waitKey(0)
if __name__=="__main__":
while True:
model_pth_path = r"E:\PythonProject\clip_pytorch\logs\2025_05_06_16_36_12\weights\best_epoch_weights.pth"
image_path = input("请输入图像路径:")
# E:\PythonProject\clip_pytorch\flickr8k\images\35506150_cbdb630f4f.jpg
# E:\PythonProject\clip_pytorch\flickr8k\images\3682277595_55f8b16975.jpg
text_language = ["A man in a red jacket is sitting on a bench whilst cooking a meal",
"A greyhound walks in the rain through a large puddle",
"A group of people ride in a race",
"A cyclist is performing a jump near to a railing and a brick wall"]
model_predict = Predict(model_pth_path)
model_predict(image_path, text_language)分类指标
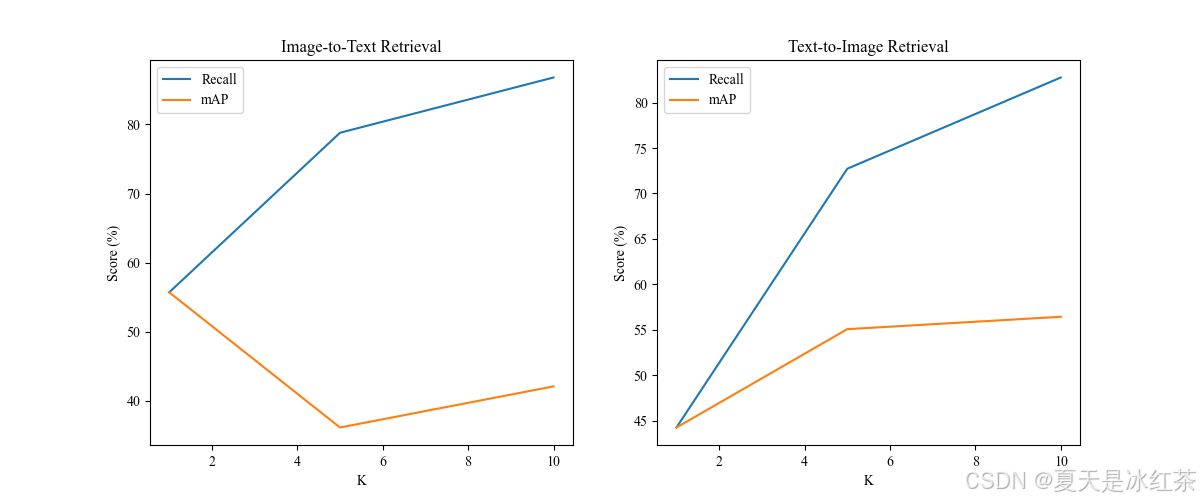
这里提供了两个分别是Recall@K 和 mAP@K,运行utils/metric.py即可。
| 指标 | 公式 | 物理意义 |
|---|---|---|
| Recall@K | 前K个结果中命中的相关结果数 / 所有相关结果总数 | 衡量前K个结果是否包含正确答案 |
| mAP@K | 衡量前K个结果的排序质量(考虑位置加权) |
为了让图线更加平滑,这里采用的是1到10。
参考文章
深度学习算法应用实战 | 利用 CLIP 模型进行“零样本图像分类”-CSDN博客
使用CLIP模型进行零样本图像分类的分步指南 - overfit.cn
CLIP——多模态预训练模型介绍_clip模型-CSDN博客
CLIP算法的Loss详解 和 交叉熵CrossEntropy实现_clip loss-CSDN博客
多模态模型学习1——CLIP对比学习 语言-图像预训练模型_clip模型-CSDN博客
参考项目
bubbliiiing/clip-pytorch: 这是一个clip-pytorch的模型,可以训练自己的数据集。
mlfoundations/open_clip: An open source implementation of CLIP.
owenliang/mnist-clip: a super easy clip model with mnist dataset for study



















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











