






在接触 AI 应用开发的这段时间,我以为会像以前学.net,学 java,学 vue 一样。先整个 hello world,再一步一步学搭功能,学搭框架直到搭一个系统出来。然而,理想总是很丰满,现实很骨感。在实践的过程中各种千奇百怪的问题:
-
概念太多。你以为就 GPT、LLM?太年轻了,huggingface、transformers、torch、tokenizers、langchain、modelscope、fastapi、CUDA、cuDNN、Conda、vLLM、ResNet-50、top_p 等等等等....它们有些是工具,有些只是个库,有些甚至就是个参数名以及还有些我到现在都不知道是个啥。
-
运行代码时,经常莫名奇妙地各种报错。以前学 vue 的时候,我以为前端的包已经够混乱了,直到开始接触 AI,没有最混只有更混。
-
运行时间太长,且结果不确定。没有云上足够的算力和显卡,一个简单的代码运行少则 10 分钟,多则几小时,一般人是忍受不了的。就算当你历经千辛万苦程序跑完了,你会发现不太容易验证运行结果的正确性,不知道改了某个参数到底是起没起作用。
看了网上一堆 AI 开发的文章,得出两个字总结:写的都是垃圾!对,都是
在学的过程中,我就想着。等我做出个东西。一定要把这些个牛鬼蛇神给掰扯清楚。废话不多说,故事就从 hello world 说起。
工具准备
1、MiniConda 首先装这个,这个玩意有点像 docker,可以隔离多个项目的 python 环境,并且默认带有 vc++等库。为什么我把它放第一?作为一个程序员,我还是有洁癖的,开始的时候我非常不想装这玩意,直接装个 python 3.12,手动 pip install 霹雳巴拉下各种包多潇洒。直到运行一个最简单的代码缺各种依赖环境时,不但缺 python 的包,竟然还缺各种 dll,还缺 vc++运行时,当时心里各种 NMBD....然后老老实实把它装上了,一切都顺了。安装它会默认会集成 python,所以不用单独装 python。我装的版本:MiniConda3 py312_24.7.1
2、PyCharm 开发 python 的第一选择。开始我用的 vs code,调试运行各种手动命令敲烦了,还是 pycharm 按钮好使。
就先装这俩吧。
环境准备
电脑 cmd 命令提示符。设置清华的镜像,用于后面下载各种 python 的包。默认国外的镜像和.net nuget 包、java maven 库及前端 npm 包一个尿性卡的要死,只能用国内的。
python -m pip install --upgrade pippip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
复制代码
新建项目
直接 pycharm 新建一个项目,名字随便起。毕竟我们是整大模型的,不是学 python 入门的。叫 llmTest 吧!如图 1:
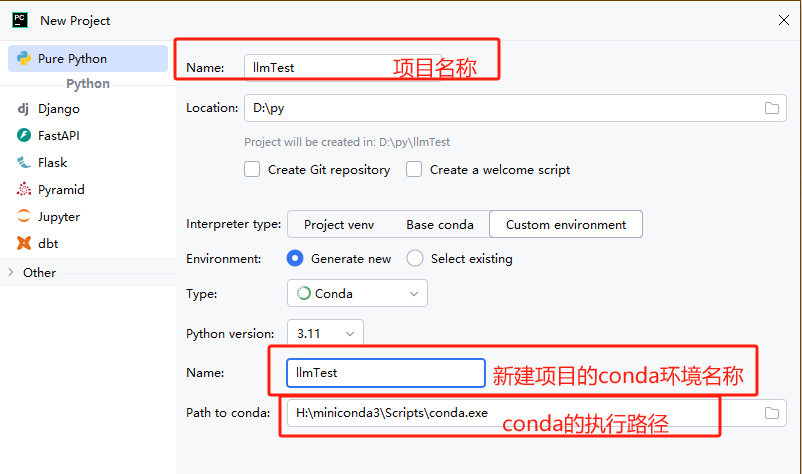
(图 1)
这里注意:
-
interpreter type:就是运行环境,选 custom environment。基于 conda 新建的环境名(想象成 docker 的一个实例,这个环境只对我们这个项目有效)。界面上提供了 project venv,这种方式也可以控制项目的运行环境,想了解地自行搜索,新手不能太多选择,我就喜欢用顺手的,哈哈哈!!
-
path to conda:就是工具准备里面 miniconda3 的安装路径。
模型下载
目前国内外的通用大模型可以用密密麻麻来形容,gitee 上面已经收录了 1 万多个了:https://ai.gitee.com/models 。模型下载方式很多,有直接用 git lfs 下载的、有直接下文件的,还有不直接下载运行时才加载的写代码方式。关键是这种方案还挺好使。本着新手不能太多选择,直接推最顺手的原则。我用的阿里魔塔 modelscope(注意它不是模型,不是!它只是个下载工具)。直接在 pycharm 命令终端里面执行 pip install modelscope,如图 2:
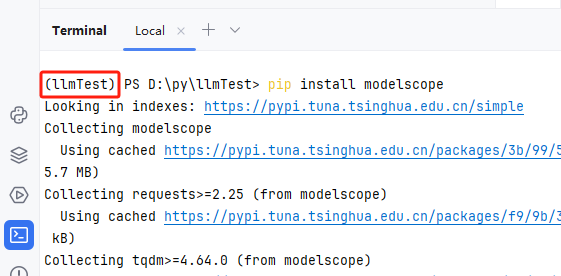
(图 2)
注意图上红框的部分。这里没有用 windows 的命令终端执行,就是保证一直用的是我们刚刚创建的 conda 环境 llmTest。防止安装包的时候,装到其他找不到的位置了。也可以看出下载的源用的是我们刚刚设置的清华镜像。
新建一个 app.py。编写下载代码:
#模型下载from modelscope import snapshot_downloadmodel_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='D:\Transformers')
复制代码
这里我以清华智谱 ChatGLM3 模型为例,下载到 D:\Transformers。如果人品不是太差的话,运行效果如下:
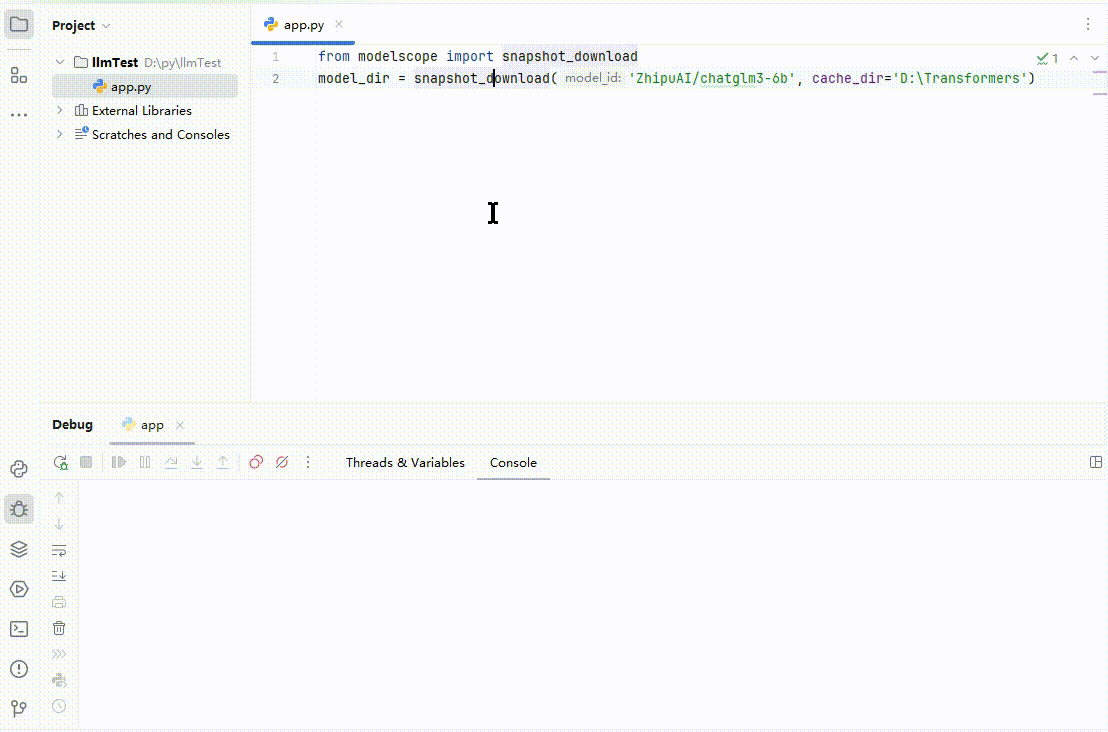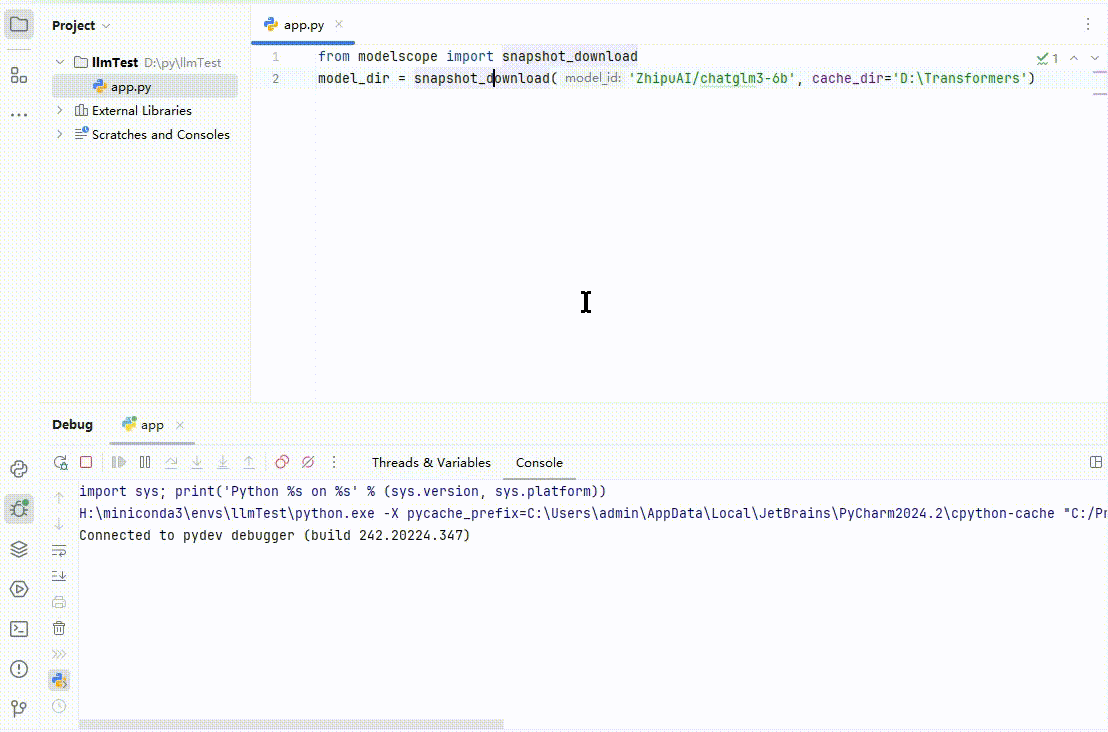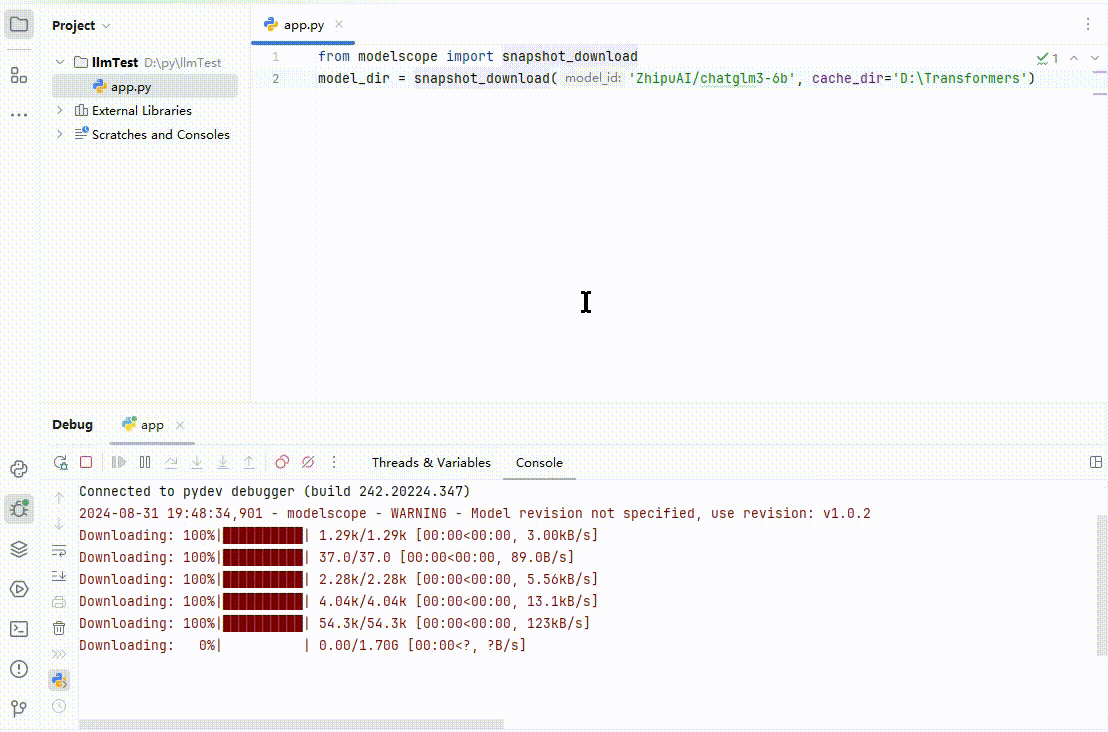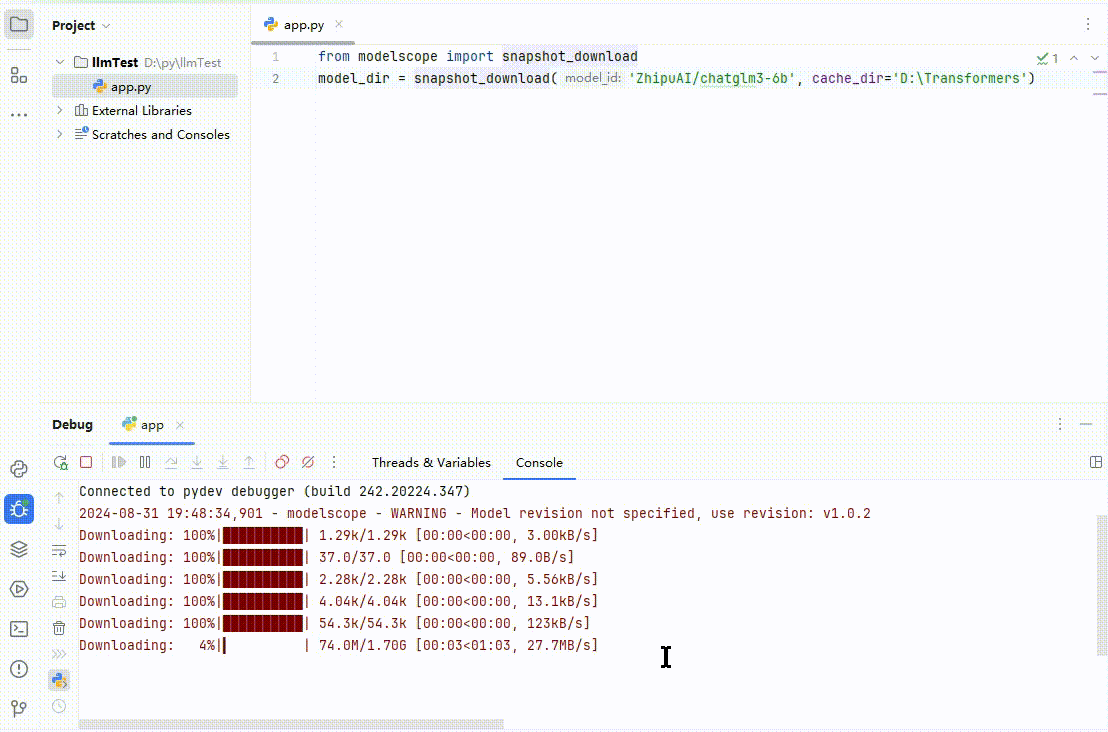
(图 3)
总共有 15 个 G 左右,需要等一段时间。至此一个大模型顺利下载完毕,它的结构如下图所示,别问我里面是啥,我也看不懂:
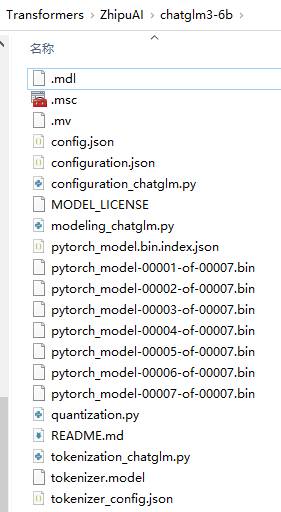
(图 4)
模型使用
以上算是完成了全部的准备工作,作为一个有效率的打工人,马上迫不及待地想看效果了。立马码字:
from modelscope import AutoTokenizer, AutoModel, snapshot_downloadmodel_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='D:\Transformers')# model_dir ='D:\Transformers\ZhipuAI\chatglm3-6b';tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cpu() # 权重和计算从 32 位浮点数转换为16位model = model.eval()response, history = model.chat(tokenizer, '你好', history=[])print(response)
复制代码
这段代码意图无比清晰,启动刚刚下载的 chatglm3-6b 模型,和它打个招呼,羞涩地问下:“你好”。先别急着运行,因为你运行肯定会报错(多么痛地领悟,该踩的坑我都踩完了😂)。先参考图 2,在 pycharm 命令终端依次执行以下安装命令,保证安装模型运行所需要的包:
conda install pytorch torchvision torchaudio cpuonly -c pytorchpip install transformers==4.40.0pip install sentencepiece
复制代码
全部安装完毕后,点击 Debug 尝试运行:
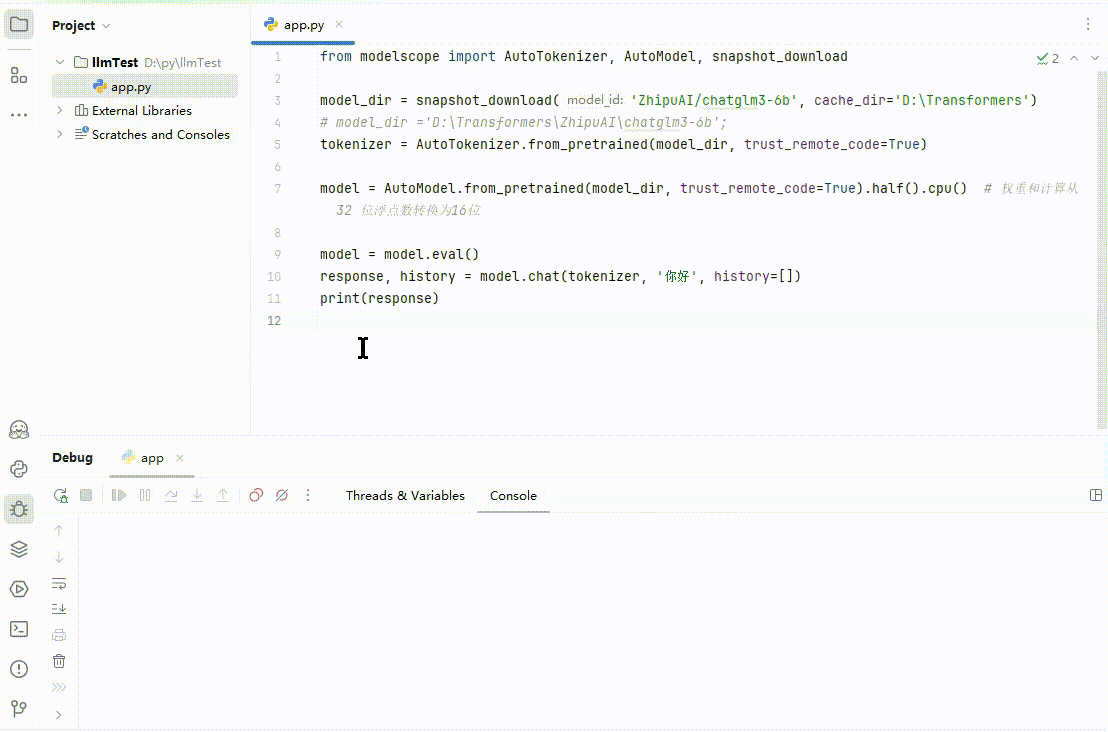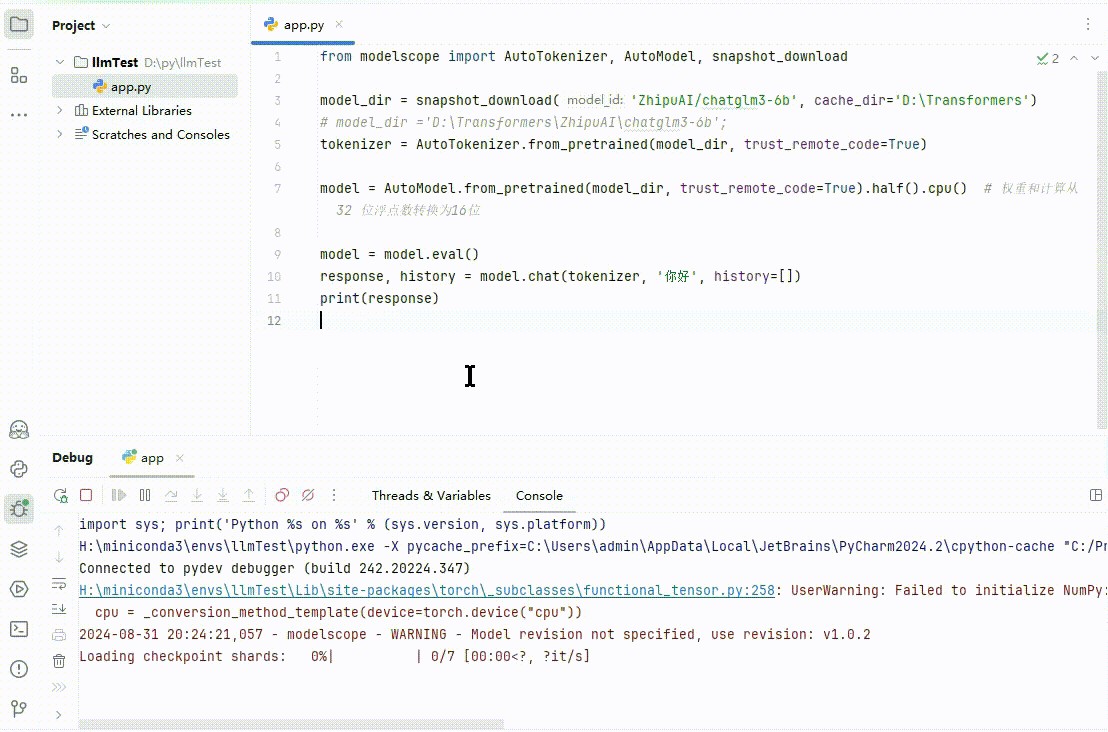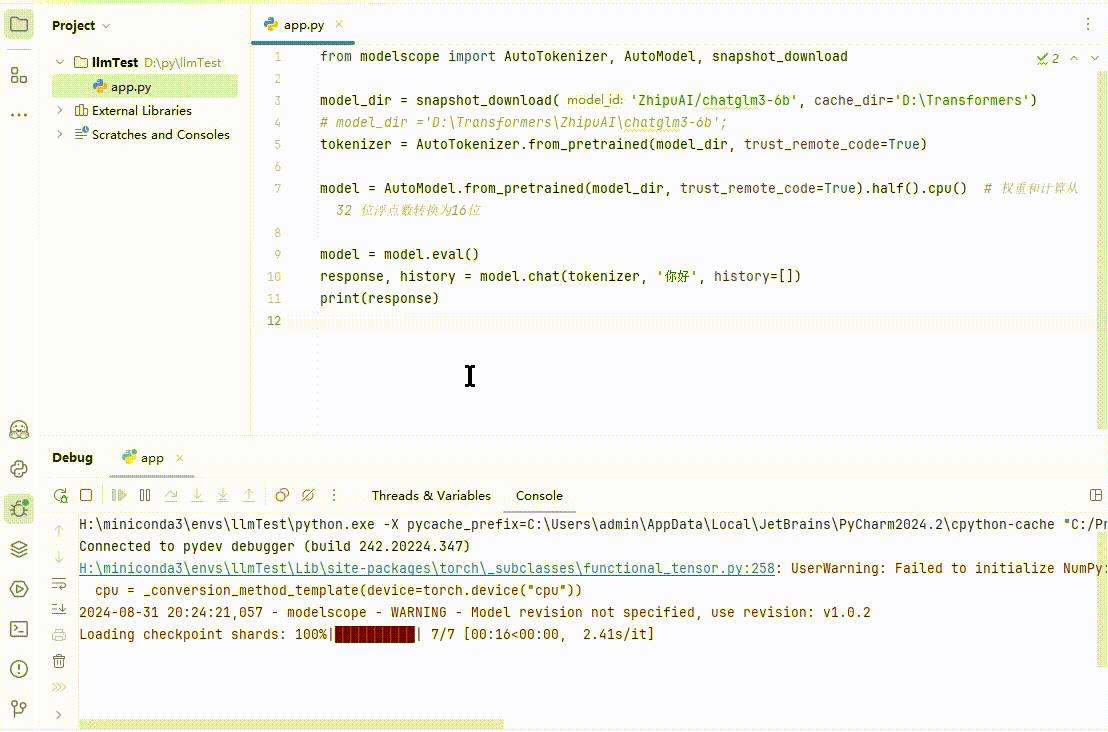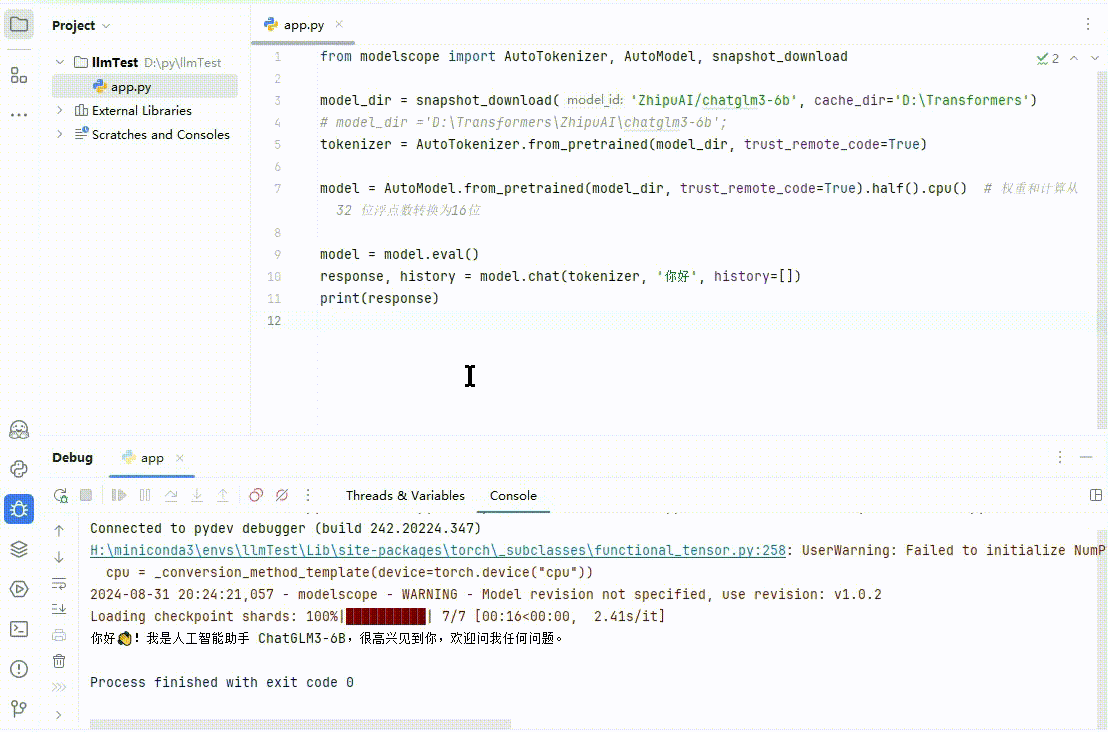
(图 5)
ChatGLM 会输出类似“你好!我是人工智能助手 ChatGLM3-6B,很高兴见到你,欢迎问我任何问题。”这样的回答。当然,就像文章开始说的结果不确定,你的结果和上面不一定相同。
视频我剪辑过,在我的电脑上,实际运行时间 5 分钟左右😂。至此最简单的模型应用开发完毕。
提供 API 支持
上面最简单的 Hello world 写完了,接下来就要为各种客户端提供接口服务了。.Net 有 WebAPI + IIS,java 有 spring boot+tomcat,大模型有 FastAPI+Uvicorn:FastAPI 用于构建应用的业务逻辑,Uvicorn 是运行这些应用的服务器。参考图 2,在 pycharm 命令终端依次执行以下安装命令:
pip install uvicornpip install fastapi
复制代码
把上面的代码微调一下:
import uvicornfrom fastapi import FastAPI,Bodyfrom fastapi.responses import JSONResponsefrom typing import Dictapp = FastAPI()from modelscope import AutoTokenizer, AutoModel, snapshot_downloadmodel_dir = snapshot_download('ZhipuAI/chatglm3-6b', cache_dir='D:\Transformers')tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cpu() # 权重和计算从 32 位浮点数转换为16位@app.post("/chat")def chat(data: Dict):query = data['query']history = data['history']if history== "":history = []response, history = model.chat(tokenizer, query, history=history, top_p=0.95, temperature=0.95)response = {'response':response,'history':history}return JSONResponse(content=response)if __name__ == '__main__':uvicorn.run(app, host="127.0.0.1", port=7866)
复制代码
点击 Debug 尝试运行,即可启动一个 7866 端口的 API 服务。
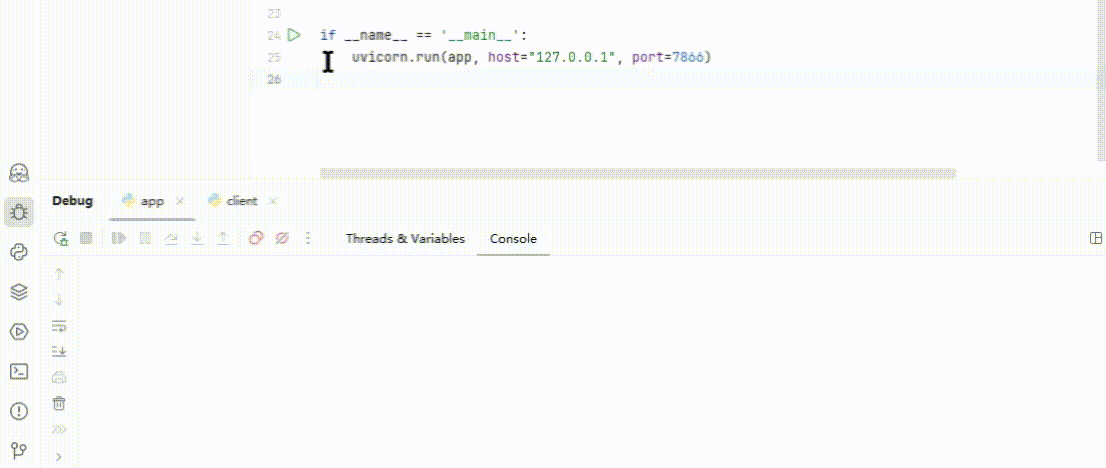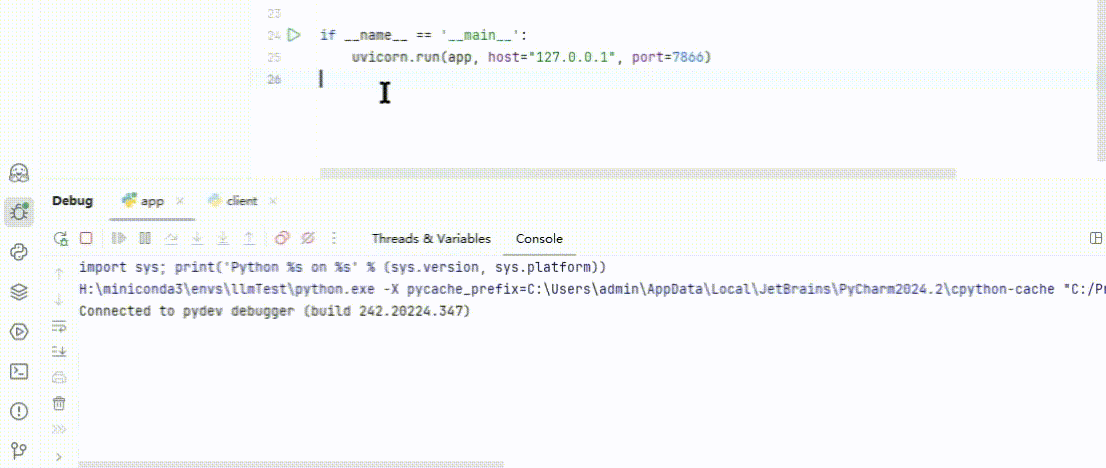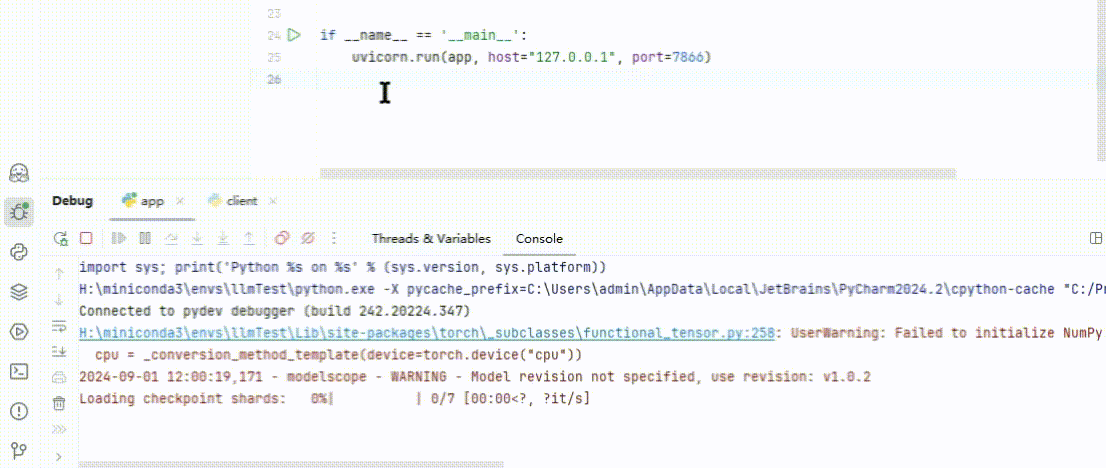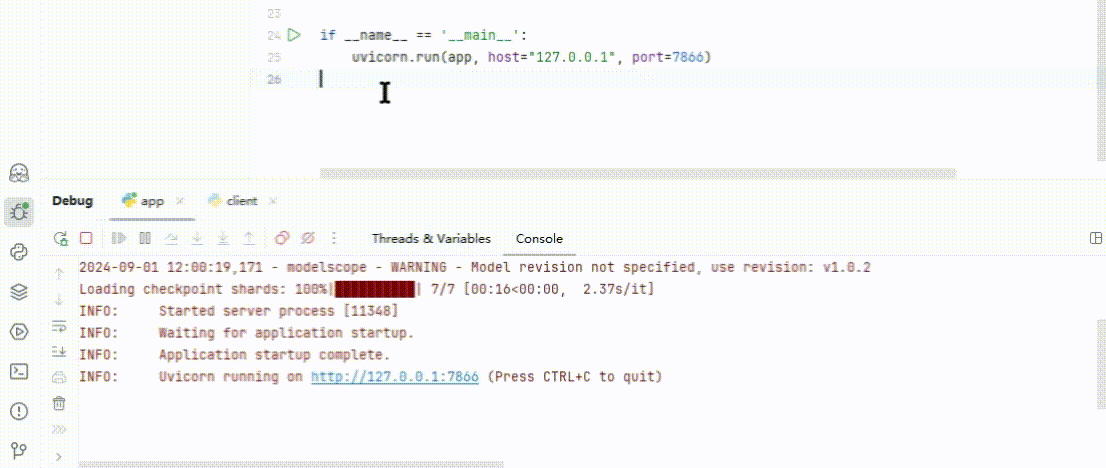
(图 6)
我们用 postman 等客户端工具测试一下:
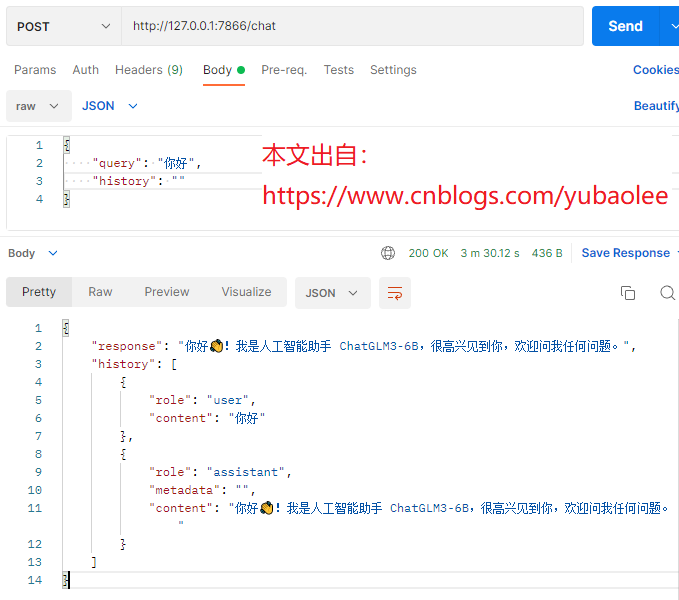
(图 7)
编写客户端
服务端有了,当然要做个漂亮的客户端,总不能一直用 postman。不得不吐槽下,大模型也搞前后端分离这套🤮!.net java 有 httprequest,js 有 jquery、axios,大模型也有个出名的库 langchain,官方的解释它提供了“链”的概念,允许开发者将多个语言模型调用、API 请求、数据处理等操作链接起来,以创建更复杂的应用流程。这里你就当它是个用来封装 http 请求的客户端吧!还是按图 2 的方式先安装:
pip install langchainpip install langchain-community
复制代码
在工程里面新建一个文件 client.py。编写客户端代码:
import requestsimport loggingfrom typing import Optional, List, Dict, Mapping, Anyimport langchainfrom langchain.llms.base import LLMfrom langchain.cache import InMemoryCachelogging.basicConfig(level=logging.INFO)langchain.llm_cache = InMemoryCache()class ChatLLM(LLM):url = "http://127.0.0.1:7866/chat"history = [];@propertydef _llm_type(self) -> str:return "chatglm"def _construct_query(self, prompt: str) -> Dict:query = {"history": self.history,"query": prompt}import jsonquery = json.dumps(query)return query@classmethoddef _post(self, url: str, query: Dict) -> Any:response = requests.post(url, data=query).json()return responsedef _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:query = self._construct_query(prompt=prompt)response = self._post(url=self.url, query=query)response_chat = response['response']self.history = response['history']return response_chat@propertydef _identifying_params(self) -> Mapping[str, Any]:_param_dict = {"url": self.url}return _param_dictif __name__ == "__main__":llm = ChatLLM()while True:user_input = input("我: ")response = llm(user_input)print(f"ChatGLM: {response}")
复制代码
执行一下,和它说个‘你好’,再问下它是谁,效果如下(再次友情提示:视频剪辑过,肯定没有这么快😀!!!):
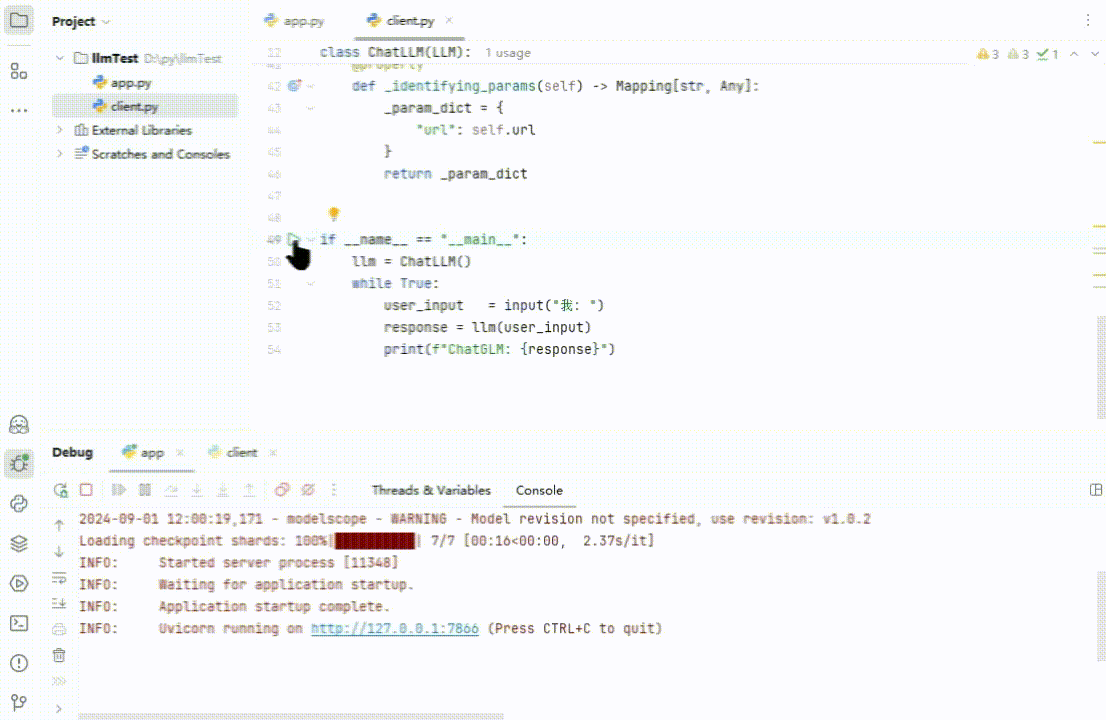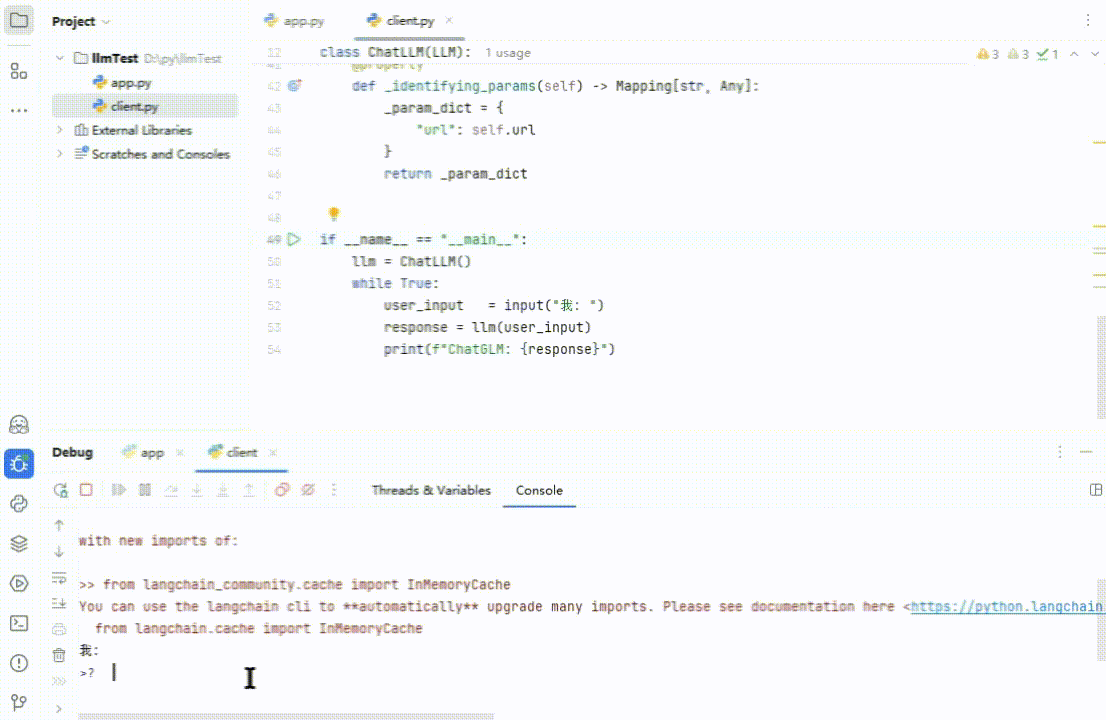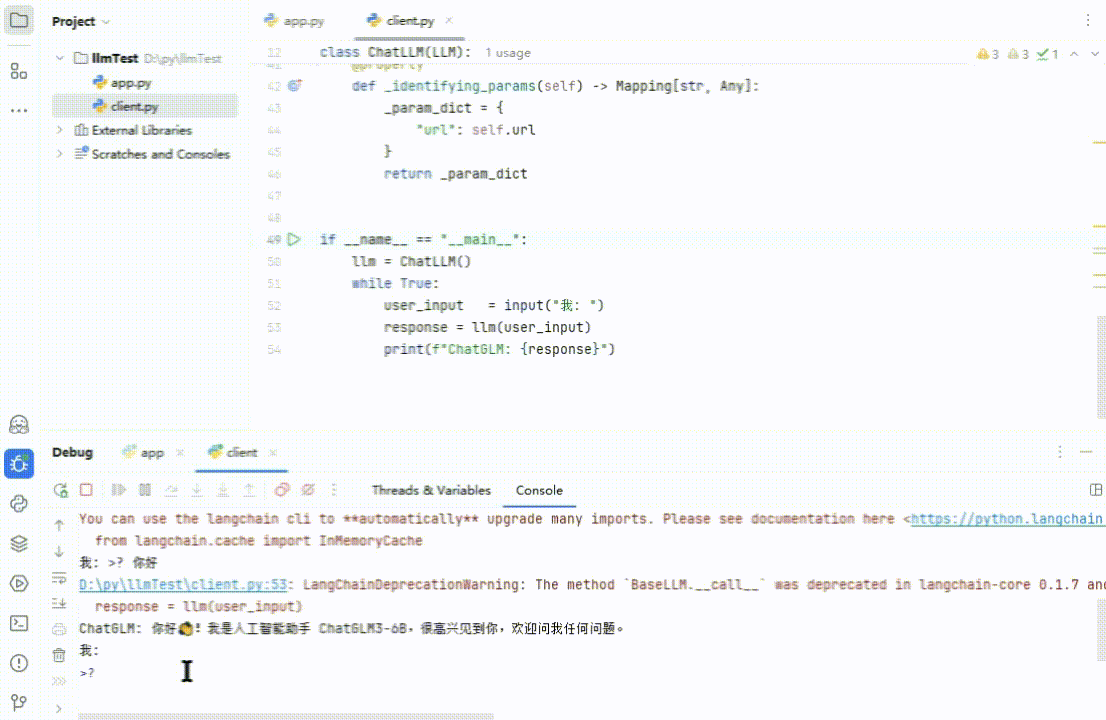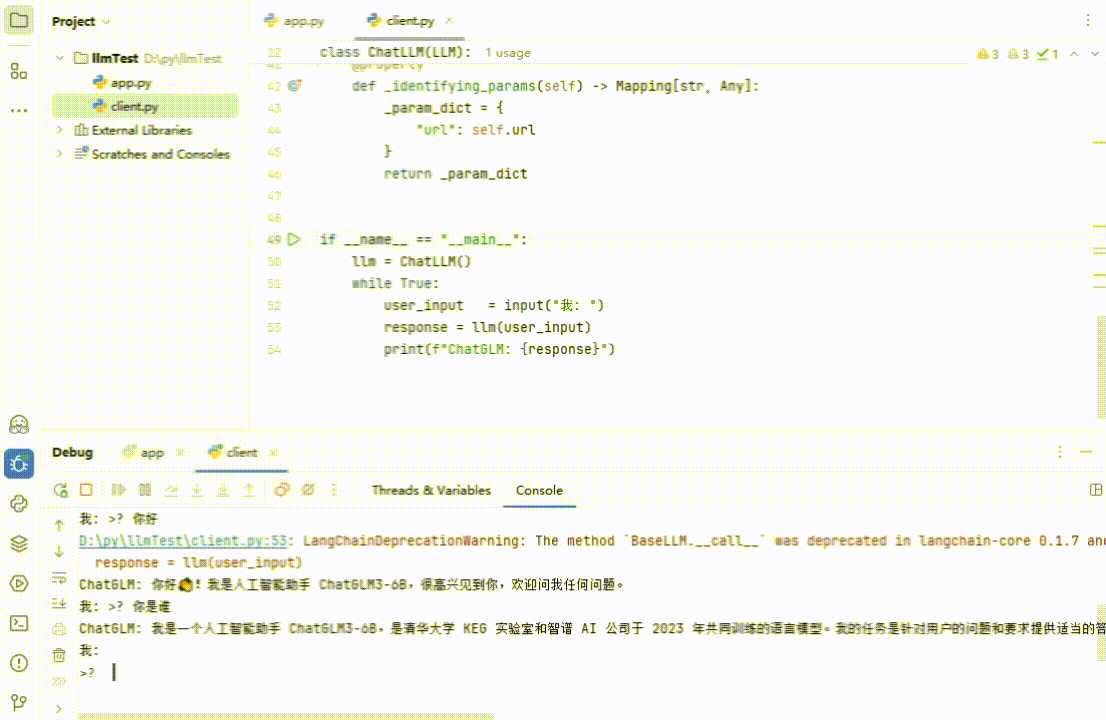
(图 8)
等等,这好像还是算不上客户端!怎么着也得个应用程序 APP 之类,再不济也得有个 Web 吧!好吧,安排!为了搞大模型的人能安心研究模型,不用花精力在界面上。市场上就出现了 2 个常用的大模型 web 界面框架 Gradio 和 Streamlit,不用去研究哪个更好,顺手就行!类似 ElementUI、AntDesign 没必要非争个你死我活的!我这里以 Gradio 为例,先安装:
pip install gradio#如果安装gradio后ImportError: DLL load failed while importing _multiarray_umath: 找不到指定的模块。执行下面:pip install numpy==1.25.2
复制代码
在工程里面新建一个文件 webclient.py。编写网页代码:
import gradio as grfrom client import ChatLLM #引用client.py里面我们定义的ChatLLMllm = ChatLLM()# 流式处理def stream_translate(text):response = llm(text)for chunk in response.split():yield chunk + " "demo = gr.Interface(fn=stream_translate, inputs="text", outputs="text", title="ChatGLM",description="A chatbot powered by ChatGLM.")demo.launch()
复制代码
执行一下:
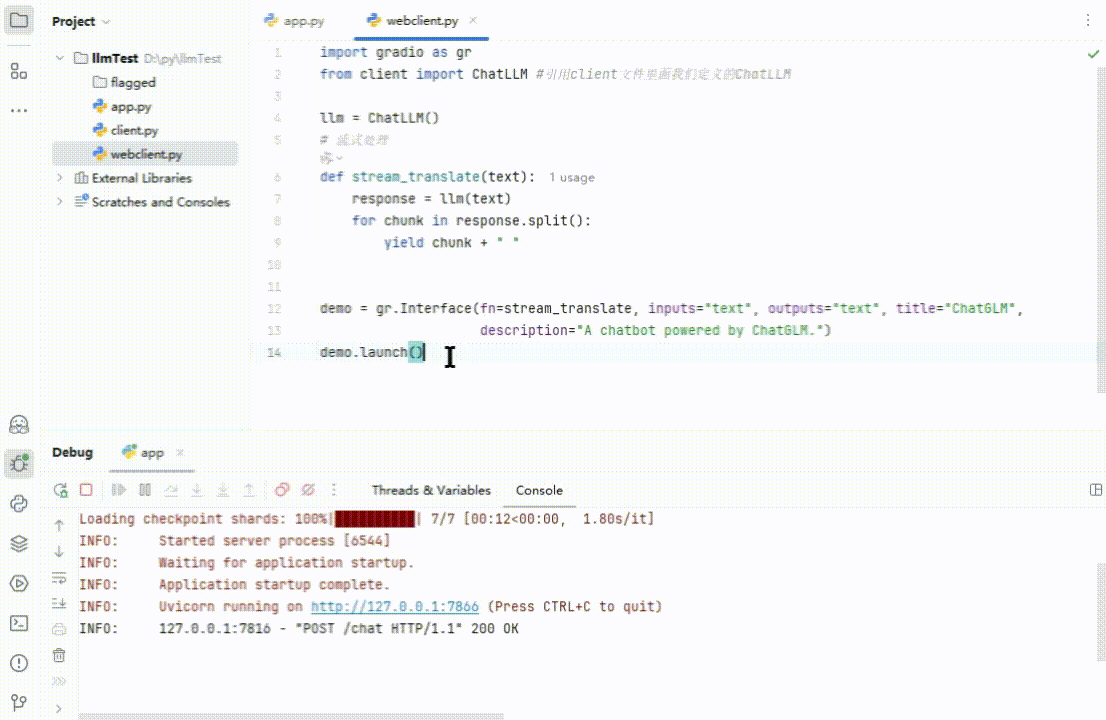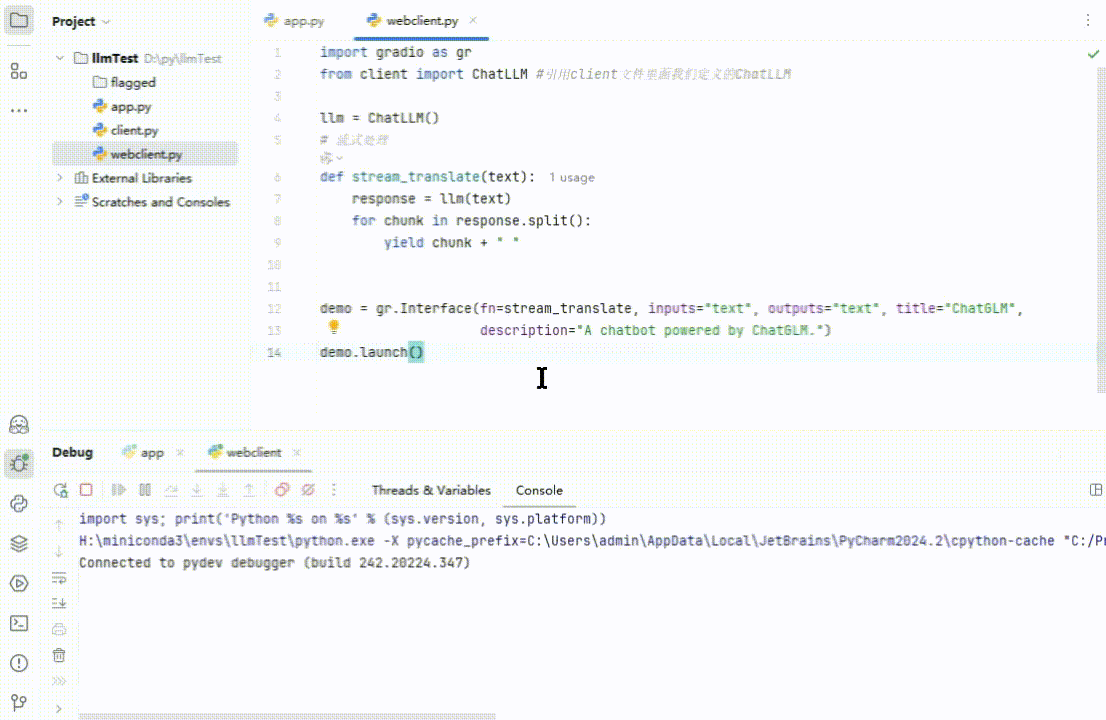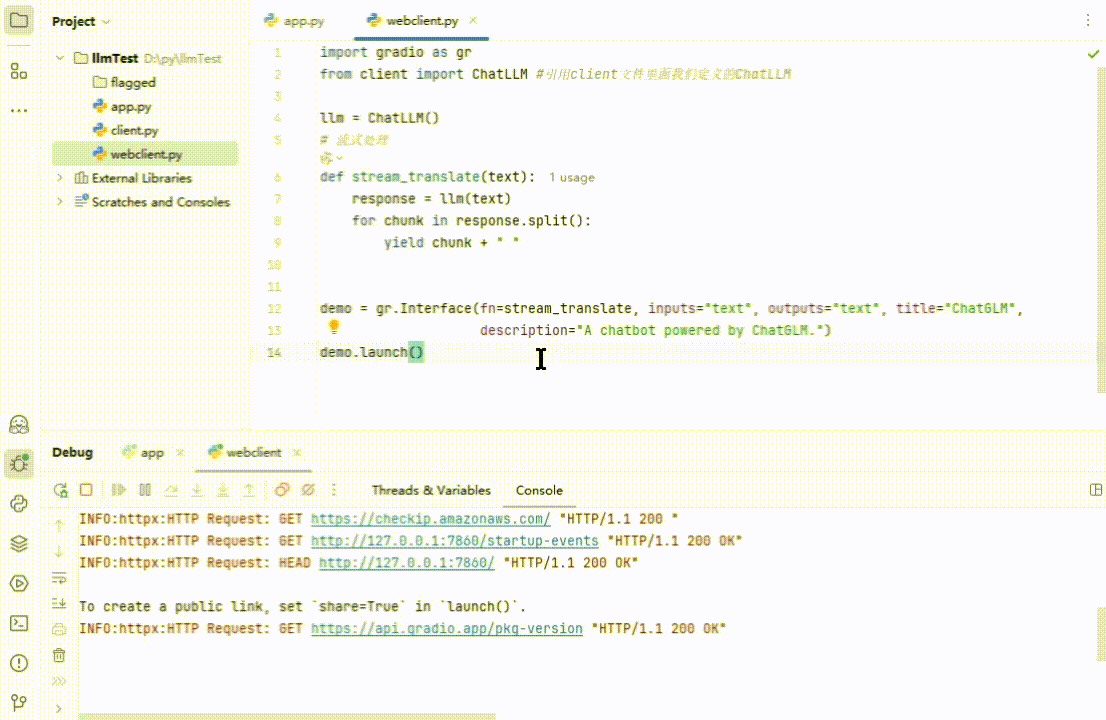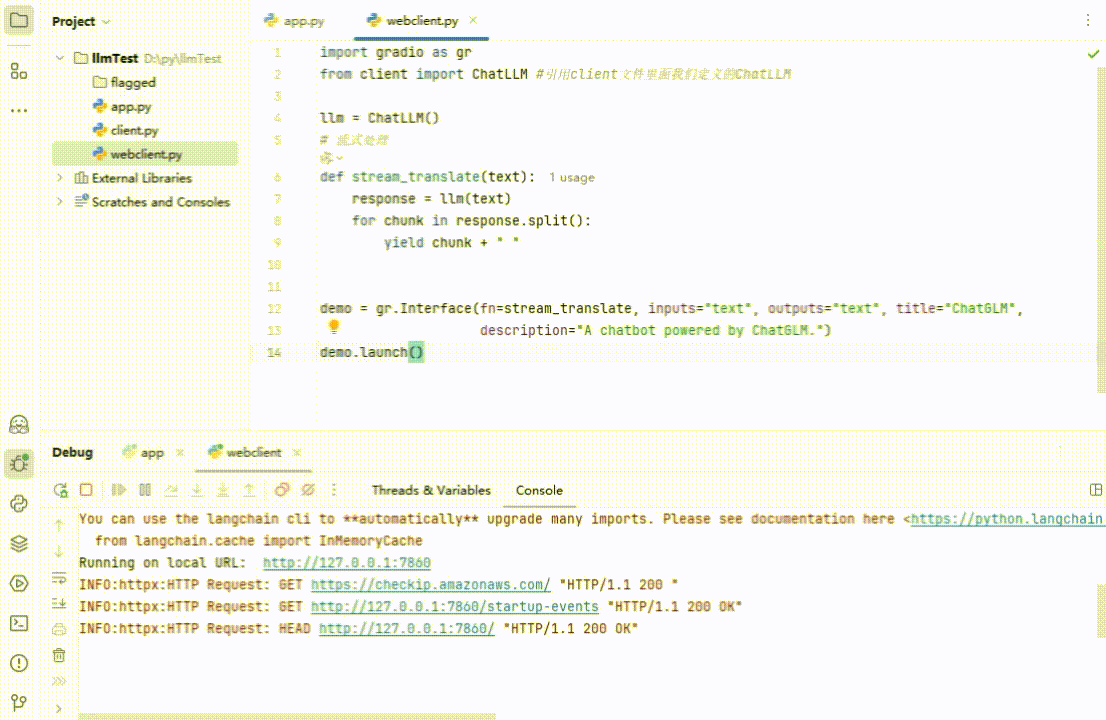
(图 9)
在浏览器里面打开:http://127.0.0.1:7860 就可以看到我们的客户端。这时随便问大模型几个问题吧(再次友情提示:视频剪辑过,后面那个问题 1500 多秒!):
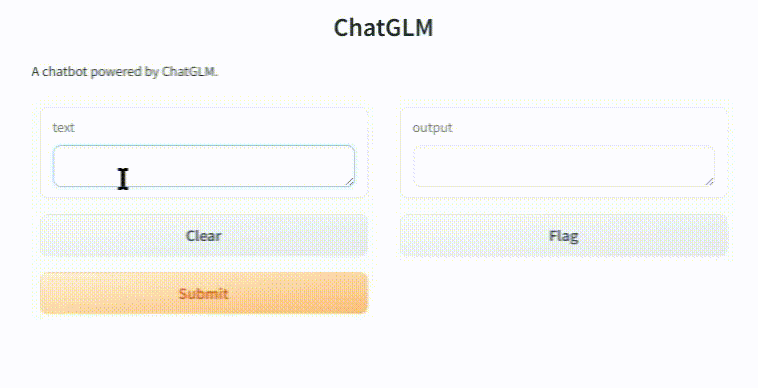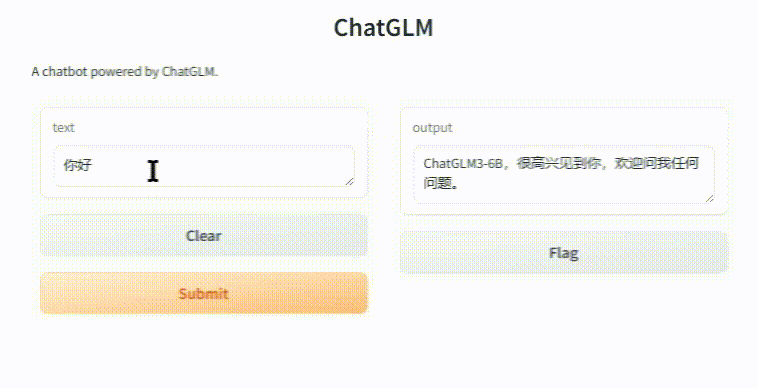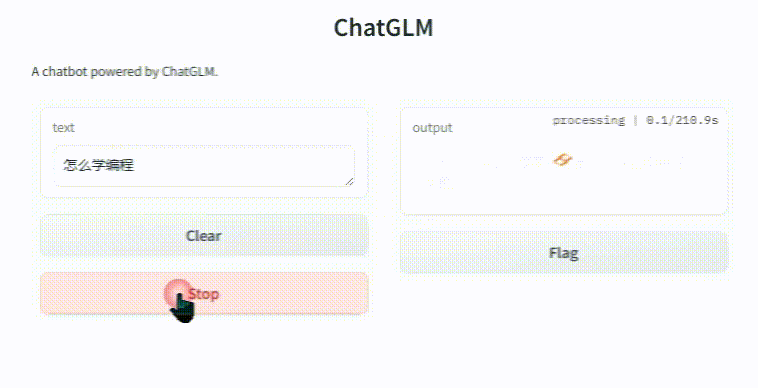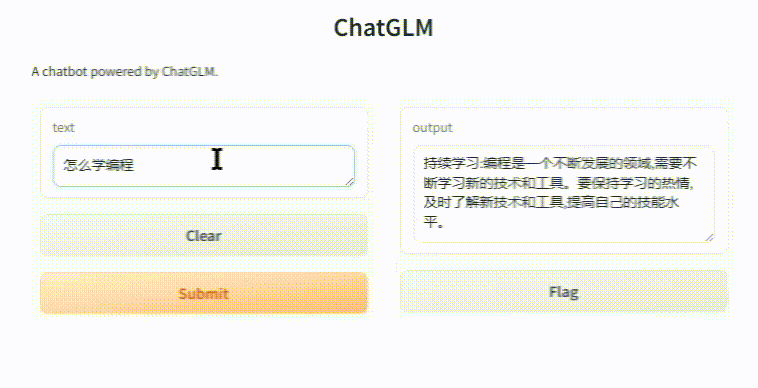
(图 10)
到这里,入门流程介绍完毕。看的人多的话,我会继续介绍模型微调和训练,希望大家喜欢!
最后

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









