






YOLOv8目标检测创新改进与实战案例专栏
专栏目录: YOLOv8有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLOv8基础解析+创新改进+实战案例
介绍

摘要
视觉Transformer由于其强大的模型能力,已经展示了巨大的成功。然而,其显著的性能伴随着高计算成本,这使得它们不适合实时应用。在本文中,我们提出了一系列高速视觉Transformer,命名为EfficientViT。我们发现现有Transformer模型的速度通常受限于内存效率低的操作,尤其是MHSA中的张量重塑和元素级函数。因此,我们设计了一个新的构建块,采用三明治布局,即在高效的FFN层之间使用单个内存绑定的MHSA,以提高内存效率同时增强通道通信。此外,我们发现注意力图在不同头部之间具有高度相似性,导致计算冗余。为了解决这一问题,我们提出了一个级联分组注意力模块,为不同的注意力头提供完整特征的不同拆分,这不仅节省了计算成本,还提高了注意力的多样性。全面的实验表明,EfficientViT在速度和准确性之间取得了良好的平衡,优于现有的高效模型。例如,我们的EfficientViT-M5在准确性上超过了MobileNetV3-Large 1.9%,同时在Nvidia V100 GPU和Intel Xeon CPU上的吞吐量分别提高了40.4%和45.2%。与最近的高效模型MobileViT-XXS相比,EfficientViT-M2的准确性高出1.8%,在GPU/CPU上的运行速度分别快5.8倍/3.7倍,并且在转换为ONNX格式时速度快7.4倍。代码和模型可以在这里获取。
基本原理
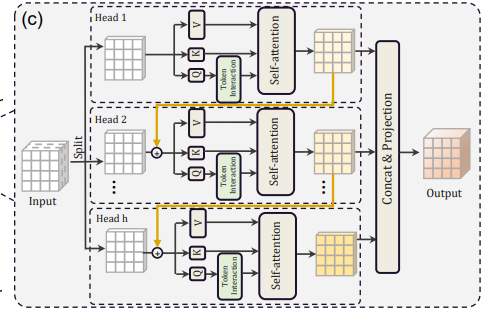
Cascaded Group Attention(CGA)是EfficientViT模型中引入的一种新型注意力模块,其灵感来自高效 CNN 中的组卷积。 在这种方法中,模型向各个头部提供完整特征的分割,因此将注意力计算明确地分解到各个头部。 分割特征而不是向每个头提供完整特征可以节省计算量,并使过程更加高效,并且模型通过鼓励各层学习具有更丰富信息的特征的投影,继续致力于提高准确性和容量。
-
CGA的动机:
- 传统的自注意力机制在Transformer中使用相同的特征集合供所有注意力头使用,导致计算冗余。
- CGA通过为每个注意力头提供不同的输入拆分来解决这个问题,从而增加注意力的多样性并减少计算冗余 。
-
CGA的设计:
- CGA通过在不同的注意力头之间级联输出特征来运行,从而更有效地利用参数并增强模型容量 。
- CGA中每个头中的注意力图计算使用较小的QK通道维度,仅产生轻微的延迟开销,同时增加网络深度 。
-
CGA的优势:
- 改进的注意力多样性:通过为每个头提供不同的特征拆分,CGA增强了注意力图的多样性,有助于更好地学习表示 ]。
- 计算效率:类似于组卷积,CGA通过减少QKV层中的输入和输出通道来节省计算资源和参数 。
- 增加模型容量:CGA的级联设计允许增加网络深度而不引入额外参数,从而提高模型的容量 。
核心代码
class CascadedGroupAttention(torch.nn.Module):
r""" Cascaded Group Attention.
Args:
dim (int): 输入通道数。
key_dim (int): 查询和键的维度。
num_heads (int): 注意力头的数量。
attn_ratio (int): 值维度相对于查询维度的倍数。
resolution (int): 输入分辨率,对应窗口大小。
kernels (List[int]): 查询上深度卷积的内核大小。
"""
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
resolution=14,
kernels=[5, 5, 5, 5],):
super().__init__()
self.num_heads = num_heads # 初始化注意力头数量
self.scale = key_dim ** -0.5 # 初始化缩放因子
self.key_dim = key_dim # 初始化键的维度
self.d = int(attn_ratio * key_dim) # 计算值维度
self.attn_ratio = attn_ratio # 初始化注意力比率
qkvs = []
dws = []
for i in range(num_heads):
qkvs.append(Conv2d_BN(dim // (num_heads), self.key_dim * 2 + self.d, resolution=resolution)) # 初始化QKV卷积层
dws.append(Conv2d_BN(self.key_dim, self.key_dim, kernels[i], 1, kernels[i]//2, groups=self.key_dim, resolution=resolution)) # 初始化深度卷积层
self.qkvs = torch.nn.ModuleList(qkvs) # 将QKV卷积层添加到模块列表中
self.dws = torch.nn.ModuleList(dws) # 将深度卷积层添加到模块列表中
self.proj = torch.nn.Sequential(torch.nn.ReLU(), Conv2d_BN(
self.d * num_heads, dim, bn_weight_init=0, resolution=resolution)) # 初始化投影层
task与yaml配置
详见: https://blog.csdn.net/shangyanaf/article/details/140138885















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









