







💡💡💡本文原创自研创新改进:SPPF_improve利用全局平均池化层和全局最大池化层,加入一些全局背景信息和边缘信息,从而获取全局视角信息并减轻不同尺度大小所带来的影响
强烈推荐,适合直接使用,paper创新级别
💡💡💡 在多个数据集验证涨点,尤其对存在多个尺度的数据集涨点明显
💡💡💡本文内容:通过 SPPF创新结构提升YOLO11-pose的关键点检测能力,
Pose mAP50 有原先的 0.871 提升至 0.883
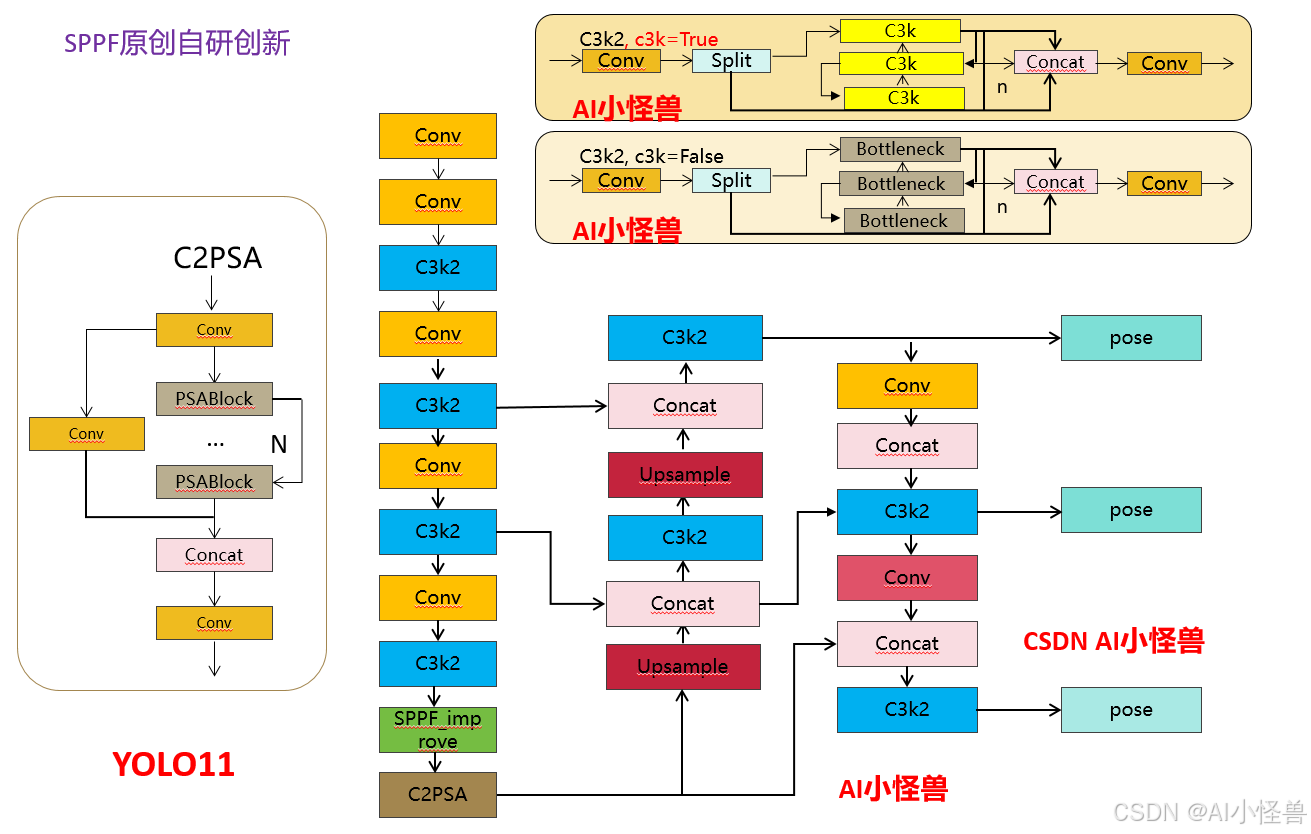
《YOLOv11魔术师专栏》将从以下各个方向进行创新:
【原创自研模块】【多组合点优化】【注意力机制】【卷积魔改】【block&多尺度融合结合】【损失&IOU优化】【上下采样优化 】【小目标性能提升】【前沿论文分享】【训练实战篇】
定期向订阅者提供源码工程,配合博客使用。
订阅者可以申请发票,便于报销
💡💡💡为本专栏订阅者提供创新点改进代码,改进网络结构图,方便paper写作!!!
💡💡💡适用场景:红外、小目标检测、工业缺陷检测、医学影像、遥感目标检测、低对比度场景
💡💡💡适用任务:所有改进点适用【检测】、【分割】、【pose】、【分类】等
💡💡💡全网独家首发创新,【自研多个自研模块】,【多创新点组合适合paper 】!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
🚀🚀🚀 本项目持续更新 | 更新完结保底≥80+ ,冲刺100+ 🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
⭐⭐⭐专栏涨价趋势 159 ->199->259->299,越早订阅越划算⭐⭐⭐
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8、Yolov9等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
1.YOLO11介绍
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。


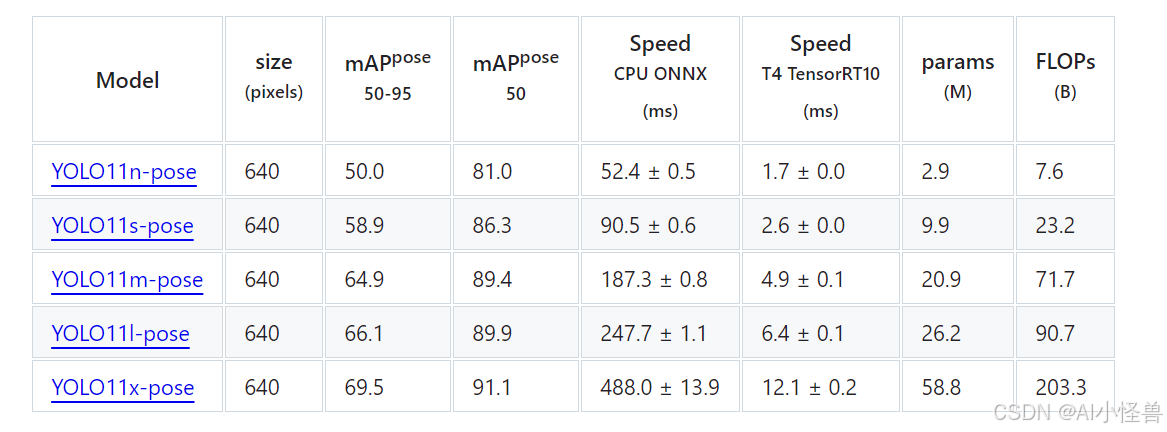
pose官方在COCO数据集上做了更多测试:
2. 手势关键点数据集介绍
2.1数据集介绍
数据集大小300张:训练集236张,验证集64张
关键点共21个
# 关键点的类别
keypoint_class = ['Ulna', 'Radius', 'FMCP','FPIP', 'FDIP', 'MCP5','MCP4', 'MCP3', 'MCP2','PIP5', 'PIP4', 'PIP3'
,'PIP2', 'MIP5', 'MIP4','MIP3', 'MIP2', 'DIP5','DIP4', 'DIP3', 'DIP2']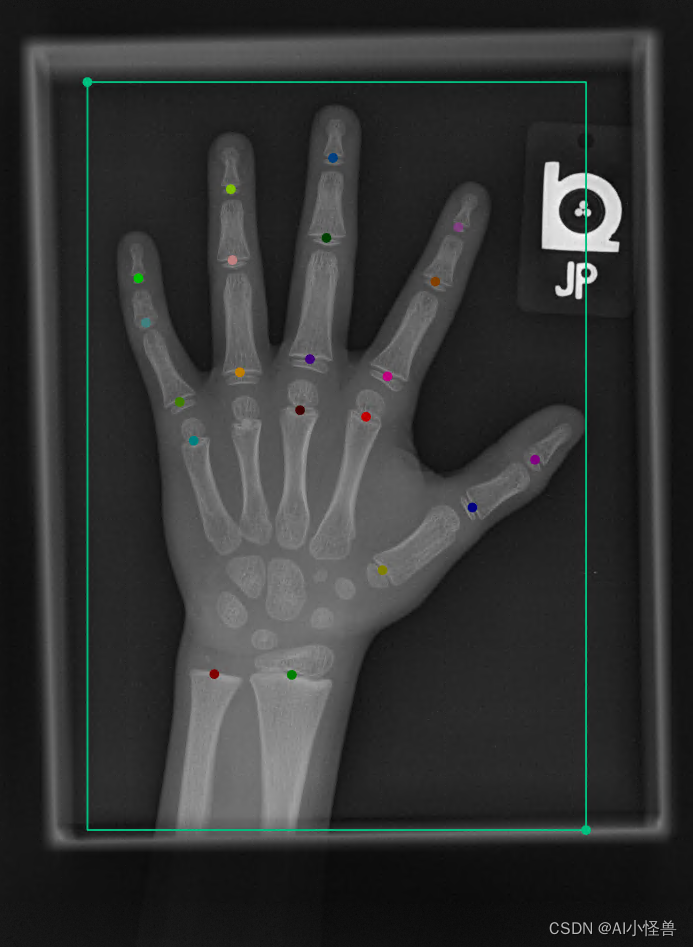
标记后的数据格式如下:一张图片对应一个json文件
labelme2yolo-keypoint
源码见博客:
YOLO11-pose关键点检测:训练实战篇 | 自己数据集从labelme标注到生成yolo格式的关键点数据以及训练教程-CSDN博客
生成的txt内容如下:
0 0.48481 0.47896 0.70079 0.77886 0.31308 0.70597 2 0.42206 0.70695 2 0.54954 0.59785 2 0.67569 0.53278 2 0.76420 0.48288 2 0.28402 0.46282 2 0.35865 0.44521 2 0.43395 0.43102 2 0.52642 0.43836 2 0.26486 0.42270 2 0.34941 0.39188 2 0.44782 0.37818 2 0.55680 0.39628 2 0.21731 0.34051 2 0.33884 0.27495 2 0.47094 0.25196 2 0.62351 0.29746 2 0.20674 0.29403 2 0.33620 0.20108 2 0.48018 0.16879 2 0.65654 0.24070 2
讲解:
第一个0代表:框的类别,因为只有hand一类,所以为0
0.48481 0.47896 0.70079 0.77886 代表:归一化后的 框的中心点横纵坐标、宽、高
0.31308 0.70597 2代表:归一化后的 第一个关键点的横纵坐标、关键点可见性
关键点可见性理解:0代表不可见、1代表遮挡、2代表可见
2.1 生成的yolo数据集如下
hand_keypoint:
-images:
--train: png图片
--val:png图片
-labels:
--train: txt文件
--val:txt文件3.SPP &SPPF原理介绍
YOLOv5最初采用SPP结构在v6.0版本(repo)后开始使用SPPF,主要目的是融合更大尺度(全局)信息,对每个特征图,使用三种不同尺寸(5×5、9×9、13×13)的池化核进行最大池化,分别得到预设的特征图尺寸,最后将所有特征图展开为特征向量并融合,过程如下图所示。
YOLOV8使用SPPF
SPPF顾名思义,就是为了保证准确率相似的条件下,减少计算量,以提高速度,使用3个5×5的最大池化,代替原来v5之前的5×5、9×9、13×13最大池化。使用SPPF的目的是为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度。
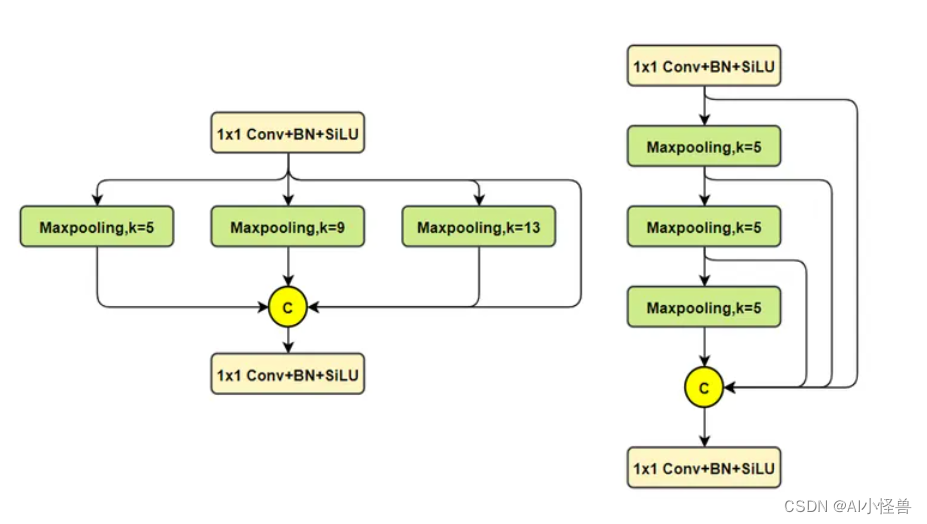 左边是SPP,右边是SPPF。
左边是SPP,右边是SPPF。
SPPF源代码
class SPPF(nn.Module):
"""Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher."""
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
"""Forward pass through Ghost Convolution block."""
x = self.cv1(x)
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))3.1 如何创新优化SPPF
分析SPPF的问题点,只关注边缘信息而忽略背景信息
如何改进:
我们在SPPF模块的基础上,利用全局平均池化层和全局最大池化层,加入一些全局背景信息和边缘信息,帮助网络更好的做出判断。
获取全局视角信息并减轻不同尺度大小所带来的影响
改进1)输入加入全局平均池化层和全局最大池化层,最后通过Concat连接
代码:
YOLO11涨点优化:SPPF原创自研创新 | SPPF创新结构,重新设计全局平均池化层和全局最大池化层,增强全局视角信息和不同尺度大小的特征-CSDN博客
4.YOLO11-pose魔改提升精度
4.1原始结果
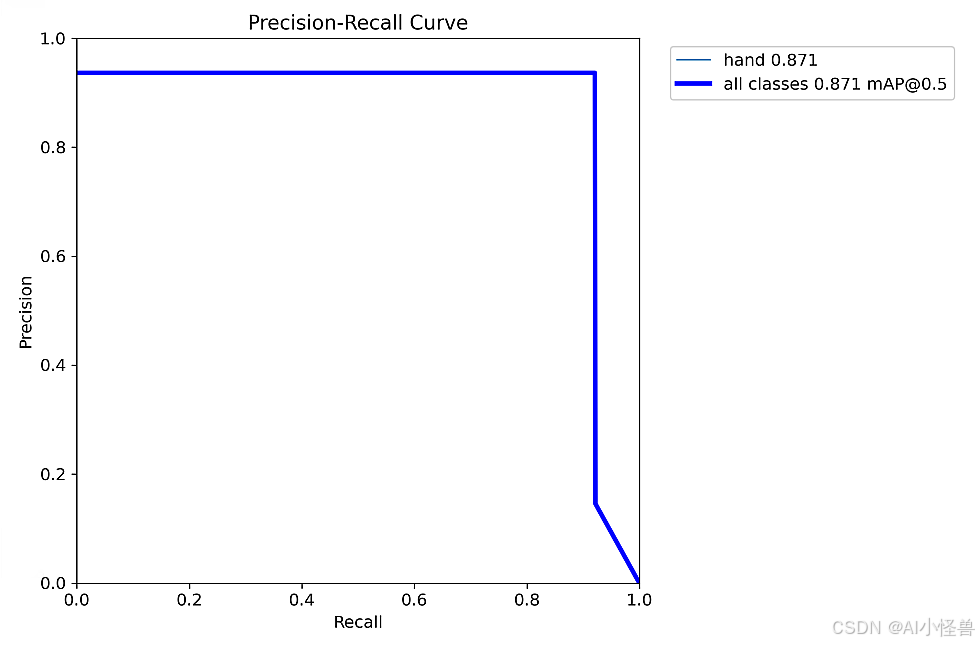
Pose mAP50 为 0.871
YOLO11-pose summary (fused): 300 layers, 3,199,712 parameters, 0 gradients, 7.8 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:04<00:00, 1.23s/it]
all 64 64 0.999 1 0.995 0.668 0.922 0.922 0.871 0.638
PosePR_curve.png
4.2 SPPF原创自研创新
Pose mAP50 有原先的 0.871 提升至 0.883
YOLO11-pose-SPPF_improve summary (fused): 306 layers, 3,265,632 parameters, 0 gradients, 7.8 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95) Pose(P R mAP50 mAP50-95): 100%|██████████| 4/4 [00:04<00:00, 1.03s/it]
all 64 64 0.999 1 0.995 0.679 0.924 0.922 0.883 0.7115.系列篇
1.训练实战篇 | 自己数据集从labelme标注到生成yolo格式的关键点数据以及训练教程
2. 具有切片操作的SimAM注意力,魔改SimAM助力pose关键点检测能力
4. SPPF原创自研创新 | SPPF创新结构,增强全局视角信息和不同尺度大小的特征
5. 自研独家创新DSAM注意力 ,助力pose关键点检测能力
6. 可变形双级路由注意力(DBRA),魔改动态稀疏注意力的双层路由方法BRA
7. 独家创新(SC_C_11Detect)检测头结构创新,助力手势pose关键点检测


















 7853
7853

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











