






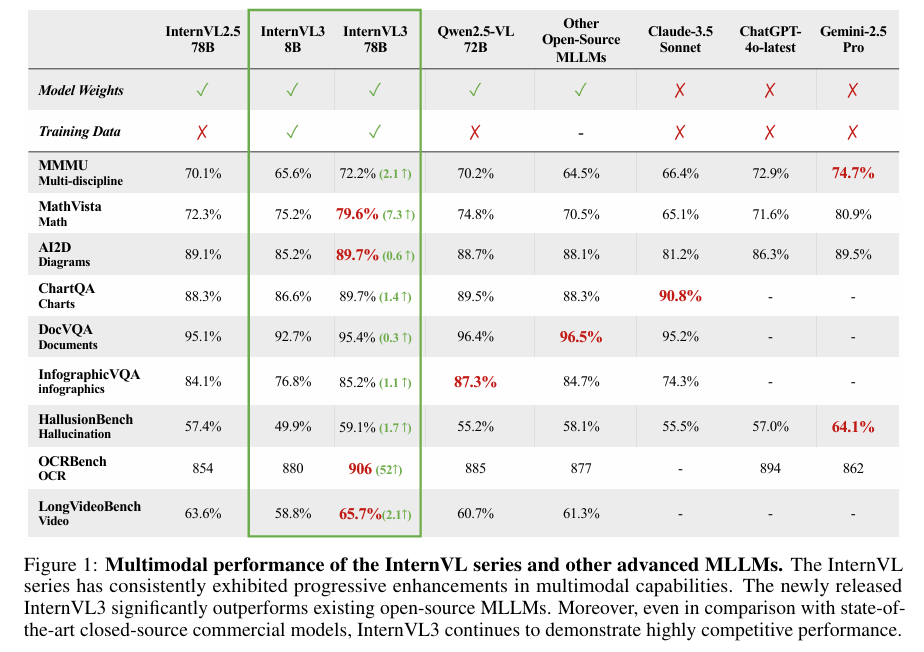
摘要:我们推出了InternVL3,这是InternVL系列的一项重大进步,具有本地多模态预训练范式。 InternVL3不是将纯文本的大型语言模型(LLM)改编成支持视觉输入的多模态大型语言模型(MLLM),而是在单个预训练阶段从不同的多模态数据和纯文本语料库中共同获取多模态和语言能力。 这种统一的训练范式有效地解决了在传统的MLLM事后训练管道中常见的复杂性和对齐挑战。 为了进一步提高性能和可扩展性,InternVL3采用了可变视觉位置编码(V2PE)来支持扩展的多模态上下文,采用了先进的训练后技术,如监督微调(SFT)和混合偏好优化(MPO),并采用了测试时间缩放策略以及优化的训练基础设施。 广泛的实证评估表明,InternVL3在各种多模态任务中提供了卓越的性能。 特别是,InternVL3-78B在MMMU基准测试中获得了72.2分,在开源MLL中创造了新的技术状态。 它的能力仍然与领先的专有模型(包括ChatGPT-4o、Claude 3.5 Sonnet和Gemini 2.5 Pro)具有很强的竞争力,同时也保持了强大的纯语言能力。 为了遵循开放科学原则,我们将公开发布训练数据和模型权重,以促进下一代MLLM的进一步研究和开发。Huggingface链接:Paper page,论文链接:2504.10479
研究背景和目的
研究背景
随着人工智能技术的飞速发展,多模态大型语言模型(MLLMs)在广泛的任务中取得了显著进展,甚至在某些任务上达到了或超越了人类水平。这些模型不仅能够处理文本数据,还能整合视觉、音频等多种模态的信息,为实现人工智能通用智能(AGI)迈出了重要一步。然而,当前大多数领先的MLLMs,无论是开源还是闭源,都面临着一些共同挑战。传统的MLLM训练方法通常先训练一个纯文本的大型语言模型(LLM),然后再通过多模态对齐来支持视觉等输入。这种方法往往会导致训练过程的复杂性增加,并且在对齐不同模态时面临挑战。此外,随着模型规模的扩大,如何有效地扩展模型的能力、提高性能和可扩展性也成为了亟待解决的问题。
研究目的
本研究旨在推出InternVL3,作为InternVL系列的一项重大进步,通过引入本地多模态预训练范式来解决上述问题。InternVL3旨在通过在一个统一的预训练阶段中,从不同的多模态数据和纯文本语料库中共同获取多模态和语言能力,从而简化训练流程并提高模型性能。此外,研究还旨在通过引入可变视觉位置编码(V2PE)、监督微调(SFT)、混合偏好优化(MPO)等高级训练技术,以及测试时间缩放策略,来进一步提升模型的性能和可扩展性。最终,研究希望通过公开训练数据和模型权重,促进下一代MLLM的进一步研究和开发。
研究方法
模型架构
InternVL3的模型架构遵循“ViT-MLP-LLM”范式,即使用视觉转换器(ViT)作为视觉编码器,多层感知器(MLP)作为中间层,以及大型语言模型(LLM)作为语言解码器。视觉编码器提供两种配置:InternViT-300M和InternViT-6B,而语言模型则利用预训练的LLM,如Qwen2.5系列和InternLM3-8B。此外,模型还采用了像素解交织操作,以增强处理高分辨率图像的可扩展性。
本地多模态预训练
InternVL3的核心在于其本地多模态预训练范式。该范式将语言预训练和多模态对齐训练整合到一个单一的预训练阶段中。通过在大规模文本语料库和多模态数据(如图像-文本对、视频-文本对等)之间交替训练,模型能够同时学习语言和多模态表示。这种联合优化策略确保了文本表示和视觉特征在训练过程中的协调对齐,从而避免了传统方法中可能出现的模态间隙问题。
可变视觉位置编码(V2PE)
为了支持扩展的多模态上下文,InternVL3引入了可变视觉位置编码(V2PE)。与传统的位置编码不同,V2PE为视觉令牌使用模态特定的递归函数来计算位置索引,从而减少了视觉令牌位置索引的增长率(δ<1),而文本令牌则保持标准的位置索引增长率(δ=1)。这种设计使得模型能够更有效地处理长序列的多模态数据。
高级训练后技术和测试时间缩放策略
为了进一步提高性能,InternVL3采用了监督微调(SFT)和混合偏好优化(MPO)等高级训练后技术。SFT通过模仿高质量响应来训练模型,而MPO则通过引入正面和负面样本的额外监督来对齐模型响应分布与真实分布。此外,研究还采用了测试时间缩放策略,如Best-of-N评估策略,以提高模型的推理能力。
优化训练基础设施
为了支持大规模模型训练,研究扩展了InternEVO框架,以优化Zero Redundancy Optimizer(ZeRO)在大规模LLM训练中的应用。该框架引入了灵活的解耦分片策略,显著提高了训练效率,并支持多种并行策略,如数据并行、张量并行、序列并行和管道并行。此外,研究还开发了一系列技术来动态平衡不同模块之间的计算负载,以克服多模态数据中视觉和文本令牌比例不均导致的效率问题。
研究结果
总体性能比较
在广泛的多模态基准测试中,InternVL3表现出了显著的性能优势。特别是在MMMU基准测试中,InternVL3-78B获得了72.2分,创下了开源MLLMs中的新纪录。与之前的InternVL系列模型相比,InternVL3在多种任务上均取得了显著的性能提升。此外,与领先的专有模型(如ChatGPT-4o、Claude 3.5 Sonnet和Gemini 2.5 Pro)相比,InternVL3也展现出了高度的竞争力。
多模态推理和数学能力
在多模态推理和数学基准测试中,InternVL3同样表现出了卓越的性能。例如,在MathVista基准测试中,InternVL3-78B获得了接近79.0的分数;在MathVision和MathVerse基准测试中,InternVL3也取得了具有竞争力的结果。这些结果表明,InternVL3在多模态推理和数学问题解决方面具有很强的能力。
OCR、图表和文档理解
在OCR、图表和文档理解任务中,InternVL3也展现出了出色的性能。在多个基准测试中,InternVL3不仅保持了稳健的性能表现,而且在与开源和闭源模型的比较中展现出了竞争力或优势。特别是在OCRBench和VCR等基准测试中,InternVL3-78B取得了显著的高分。
多图像理解和现实世界理解
在多图像理解和现实世界理解基准测试中,InternVL3同样表现出了卓越的性能。随着模型规模的扩大,InternVL3在多图像关系感知和理解方面的能力得到了显著提升。在现实世界理解任务中,InternVL3也展现出了强大的能力,能够在复杂的现实场景中提供准确的响应。
视觉接地和多模态幻觉评估
在视觉接地和多模态幻觉评估基准测试中,InternVL3也表现出了令人印象深刻的性能。特别是在视觉接地任务中,InternVL3能够在给定文本描述的情况下准确地定位图像中的目标对象。在多模态幻觉评估中,InternVL3也展现出了处理幻觉挑战的能力。
多模态多语言理解和视频理解
在多模态多语言理解和视频理解基准测试中,InternVL3同样取得了优异的成绩。特别是在视频理解任务中,InternVL3能够捕捉视频中的时空和多模态线索,从而提供准确的响应。这些结果表明,InternVL3在多模态多语言理解和视频理解方面具有很强的能力。
研究局限
尽管InternVL3在多模态任务中取得了显著的性能提升,但仍存在一些局限性和挑战。首先,尽管InternVL3采用了先进的训练技术和策略来提高性能和可扩展性,但模型规模的扩大仍然带来了计算资源和时间的巨大需求。其次,尽管InternVL3在多种基准测试中表现出了卓越的性能,但在某些特定任务上仍可能存在性能瓶颈或不足。此外,随着多模态数据的不断增加和复杂性的提高,如何更有效地整合和利用这些数据来训练模型仍然是一个挑战。
未来研究方向
针对上述局限性和挑战,未来研究可以从以下几个方面进行探索和改进:
-
优化模型架构和训练算法:继续优化InternVL3的模型架构和训练算法,以提高模型的性能和可扩展性。特别是针对大规模模型训练中的计算效率和资源利用问题,可以进一步探索分布式训练、模型压缩和量化等技术。
-
扩展多模态数据类型和来源:继续扩展InternVL3所支持的多模态数据类型和来源,以涵盖更广泛的任务和场景。特别是针对现实世界中的复杂场景和任务,可以进一步整合和利用来自不同领域和来源的多模态数据。
-
增强模型的泛化能力和鲁棒性:通过引入更多的正则化技术和数据增强策略来增强InternVL3的泛化能力和鲁棒性。特别是针对模型在特定任务或数据上的过拟合问题,可以进一步探索交叉验证、数据增强和对抗性训练等技术。
-
探索新的应用场景和任务:继续探索InternVL3在新应用场景和任务中的潜力。特别是针对那些需要高度多模态理解和推理能力的任务(如自动驾驶、机器人交互等),可以进一步开发和应用InternVL3的相关技术和算法。
-
推动开源社区的发展和合作:继续推动开源社区的发展和合作,以促进InternVL3的进一步研究和开发。通过公开训练数据和模型权重、举办相关的竞赛和挑战赛等活动,可以吸引更多的研究者和开发者参与到InternVL3的研究和应用中来。
综上所述,InternVL3作为InternVL系列的一项重大进步,在多模态任务中表现出了卓越的性能和可扩展性。然而,为了进一步提高模型的性能和应用范围,未来研究仍需在模型架构、训练算法、数据类型和来源、泛化能力和鲁棒性等方面进行持续的探索和改进。

















 1622
1622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









