






摘要:数据质量和多样性是构建有效教学调整数据集的关键。 随着开源指令调优数据集可用性的增加,从大量数据中自动选择高质量和多样化的子集是有利的。 现有方法通常优先考虑实例质量,并使用启发式规则来保持多样性。 然而,缺乏对整个集合的全面了解往往会导致次优结果。 此外,启发式规则通常关注嵌入空间内的距离或聚类,这无法准确捕捉语义空间中复杂指令的意图。 为了弥合这一差距,我们提出了一种统一的方法来量化数据集的信息内容。 该方法通过构建标签图来对语义空间进行建模,并根据图中的信息分布来量化多样性。 基于这样的测量,我们进一步引入了一种有效的采样方法,该方法迭代地选择数据样本,以最大化语义空间中的信息增益(MIG)。 在各种数据集和基础模型上的实验表明,MIG始终优于最先进的方法。 值得注意的是,使用MIG采集的5% Tulu3数据微调的模型实现了与在完整数据集上训练的官方SFT模型相当的性能,在AlpacaEval上提高了+5.73%,在Wildbench上提高了+6.89%。Huggingface链接:Paper page,论文链接:2504.13835
研究背景和目的
研究背景
近年来,大型语言模型(LLMs)在遵循人类指令完成各种任务方面展现出了卓越的能力。这些模型通常首先通过大规模预训练获得一般知识,然后通过指令调优(instruction tuning)来更好地对齐多样化的人类意图。指令调优利用指令-响应对来指导基础模型生成更准确和上下文适当的响应。然而,数据工程在指令调优中起着至关重要的作用,其中数据质量和多样性被视为关键要素。尽管高质量、人工策划的指令数据集可以显著提升模型性能,但手动构建此类数据集既耗时又费力。
随着开源指令调优数据集的日益丰富,如何从庞大的数据池中自动选择高质量和多样化的子集成为了一个亟待解决的问题。现有的数据选择方法大多侧重于实例质量,并使用启发式规则来维持多样性。然而,这些方法往往缺乏对整个数据集的全面理解,导致次优结果。此外,启发式规则通常关注于嵌入空间内的距离或聚类,这无法准确捕捉语义空间中复杂指令的意图。
研究目的
针对上述问题,本研究旨在提出一种统一的方法来量化指令调优数据集的信息内容,并通过最大化语义空间中的信息增益来自动选择高质量和多样化的数据子集。具体目标包括:
- 构建语义空间模型:通过构建标签图来建模语义空间,其中节点代表标签,边捕获语义关系。
- 量化数据集信息:基于标签图中的信息分布来量化数据集的多样性和质量。
- 开发高效采样方法:引入一种迭代选择数据样本的方法,以最大化语义空间中的信息增益(MIG)。
- 验证方法有效性:通过在不同数据集和基础模型上的实验,验证MIG方法相比现有方法的优势。
研究方法
信息测量
- 标签图构建:首先,使用标签器和评分器对原始数据池进行标注。然后,基于标签集构建标签图,其中节点代表标签,边代表标签之间的语义关系,边的权重由标签相似性决定。
- 数据点信息:每个数据点的信息分布在其关联的标签上,并与质量分数成正比。通过信息传播,可以更准确地建模语义空间中的信息分布。
- 数据集信息:应用一个单调递增但边际递减的信息得分函数来计算标签信息,以平衡质量和多样性。数据集信息是所有标签信息的总和。
MIG采样
基于信息测量的子模性,提出一种贪婪策略,迭代地选择能最大化信息增益的数据样本。具体过程如下:
- 初始化:创建一个空的选择子集和一个传播矩阵。
- 迭代选择:在每次迭代中,计算每个候选数据样本的信息增益,并选择增益最大的样本加入选择子集。
- 更新:更新传播矩阵和选择子集,并从候选池中移除已选择的样本。
- 终止:重复上述过程,直到达到预定的样本预算。
研究结果
主要结果
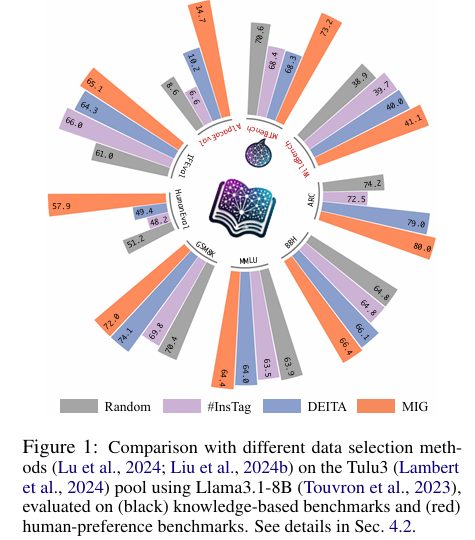
在不同数据集(如Tulu3、Openhermes2.5和X sota)和基础模型(如Llama3.1-8B、Mistral-7B-v0.3和Qwen2.5-7B)上的实验结果表明,MIG方法始终优于现有最先进的数据选择方法。具体发现包括:
- 性能提升:在Tulu3数据集上,MIG方法在知识基准测试和人类偏好基准测试上的平均得分分别比第二好的方法高出1.49%和1.96%。
- 高效采样:MIG方法显著提高了采样效率,与基于嵌入的方法相比,采样时间减少了100倍以上。
- 数据效率:使用MIG采集的5% Tulu3数据微调的模型,在AlpacaEval上提高了+5.73%,在Wildbench上提高了+6.89%,性能与在完整数据集上训练的官方SFT模型相当。
详细分析
- 信息得分函数:实验表明,信息得分函数Φ(x) = x^0.8在平衡质量和多样性方面表现最佳。
- 质量指标:DEITA得分在知识基准测试和人类偏好基准测试上均优于其他质量指标。
- 标签图参数:通过网格搜索发现,对于Tulu3数据集,最佳标签图具有4531个节点和0.9的边相似性阈值。
- 信息传播:适当的信息传播强度(α=1.0)有助于更准确地建模语义空间中的信息分布,从而提高性能。
研究局限
尽管MIG方法在许多方面都表现出了优越性,但仍存在一些局限性:
- 参数敏感性:MIG方法中的参数(如信息得分函数、标签图参数和信息传播强度)是通过网格搜索确定的,这限制了方法的灵活性和可扩展性。
- 数据依赖:MIG方法的性能可能依赖于特定数据集的特性,对于其他类型的数据集可能需要进行额外的调整。
- 计算成本:尽管MIG方法提高了采样效率,但在处理超大规模数据集时,构建标签图和计算信息增益仍可能带来一定的计算成本。
未来研究方向
针对上述局限,未来的研究可以从以下几个方面展开:
- 自动参数确定:开发方法来自动确定MIG方法中的参数,如为每个标签定制信息得分函数,以提高方法的灵活性和可扩展性。
- 跨数据集泛化:探索如何使MIG方法更好地泛化到不同类型的数据集上,减少对特定数据集的依赖。
- 计算优化:进一步优化MIG方法的计算过程,如通过近似算法或并行计算来降低处理超大规模数据集时的计算成本。
- 综合数据集评估:结合其他数据集评估指标(如数据分布、噪声水平等),为MIG方法提供更全面的数据集评估框架。
综上所述,本研究提出的MIG方法为指令调优数据集的自动选择提供了一种新的视角和方法,通过最大化语义空间中的信息增益来实现高质量和多样化的数据子集选择。未来的研究将进一步探索如何克服现有局限,提高方法的实用性和泛化能力。

















 11
11

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









