






摘要:大型推理模型(LRM)的最新进展表明,通过基于简单规则的奖励的强化学习(RL),可以出现多步推理和自我反思等复杂行为。 然而,现有的零RL方法本质上是“按策略”的,将学习限制在模型自身的输出上,无法获得超出其初始能力的推理能力。 我们引入了 LUFFY(在非政策指导下学习推理),这是一个用非政策推理痕迹增强零强化学习的框架。 在训练过程中,鲁夫通过将非策略演示与策略演示相结合,动态平衡了模仿和探索。 值得注意的是,我们建议通过正则化重要性抽样来塑造政策,以避免在混合政策训练过程中出现肤浅和僵化的模仿。 值得注意的是,LUFFY在六个数学基准测试中取得了超过+7.0的平均增益,在分布外任务中取得了超过+6.2点的优势。 它也大大超过了基于模仿的监督微调(SFT),特别是在泛化方面。 分析表明,LUFFY 不仅有效地模仿,而且超越了演示,提供了一条可扩展的路径,可以在非策略指导下训练可泛化的推理模型。Huggingface链接:Paper page,论文链接:2504.14945
研究背景和目的
研究背景
随着大型语言模型(LLMs)和大型推理模型(LRMs)的快速发展,这些模型在复杂推理任务中展现出了令人瞩目的能力。特别是通过强化学习(RL)结合简单的基于规则的奖励机制,模型能够学会生成长链推理(Chain-of-Thought, CoT)响应,并展现出自我反思和自我纠正等高级行为。然而,当前的零RL方法(即直接在基础语言模型上应用RL)存在固有局限性。这些方法本质上是“按策略”(on-policy)的,意味着学习仅限于模型自身生成的输出,难以获得超出其初始能力的推理能力。此外,尽管通过模仿学习(如监督微调SFT)可以引入外部强大策略的指导,但这种方法往往导致模型陷入表面和僵化的模仿,限制了其泛化能力。
研究目的
针对上述问题,本研究旨在提出一种新的框架——LUFFY(Learning to reason Under oFF-policY guidance),以在非策略指导下增强零RL的学习效果。LUFFY通过结合非策略推理痕迹(如来自更强大推理模型的演示)和策略演示,动态平衡模仿和探索,从而帮助模型在保持自我探索能力的同时,从高质量的外部推理痕迹中学习。本研究的主要目的是展示LUFFY在提高模型推理能力和泛化性能方面的有效性,并探索一种可扩展的路径来训练具有更强泛化能力的推理模型。
研究方法
基础RL算法
本研究基于传统的零RL方法,如GRPO(Generalized Proximal Policy Optimization)。GRPO使用查询生成的N个解决方案的奖励分数来估计优势,从而无需额外的价值模型。其目标函数定义为:
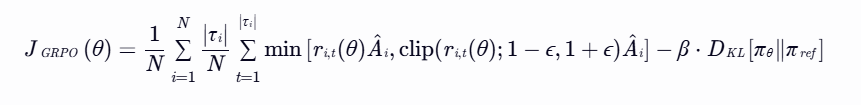
其中,![]() 是重要性采样比,
是重要性采样比,![]() 是优势估计,
是优势估计,![]() 是KL散度。
是KL散度。
混合策略GRPO
为了引入非策略指导,本研究将非策略演示直接添加到模型自身生成的策略演示组中,从而影响优势计算。然而,这种简单的混合策略会导致策略梯度估计的偏差。为了校正这种偏差,本研究使用了重要性采样:
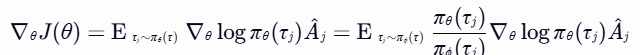
其中,![]() 是非策略分布。
是非策略分布。
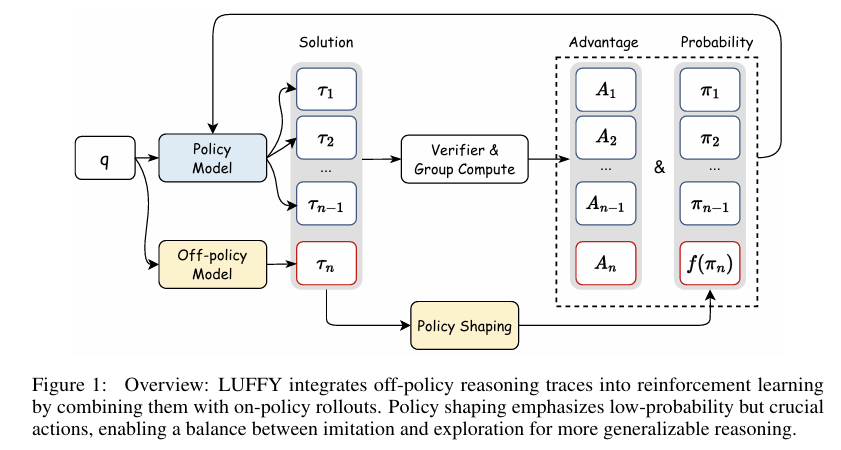
LUFFY框架
LUFFY框架通过正则化重要性抽样来塑造政策,以避免在混合策略训练中出现肤浅和僵化的模仿。具体来说,LUFFY使用了一个变换函数f(⋅)来重新加权非策略分布的梯度,从而增强对模型标准分布中低概率但关键动作的学习。LUFFY的损失函数定义为:
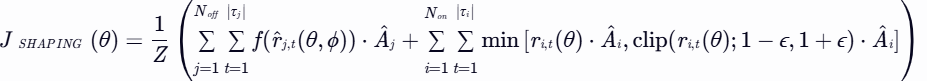
其中,f(⋅)是塑造函数,本研究中采用![]() 的形式。
的形式。
研究结果
性能提升
在六个具有挑战性的数学基准测试(包括AIME 2024、AIME 2025、AMC、MATH-500、Minerva Math和OlympiadBench)上,LUFFY的平均得分达到了49.6,相比现有的零RL方法取得了超过+7.0的平均增益。特别是在新发布的AIME 2025测试集上,LUFFY的优势达到了+8.2,显示出其在内化非策略痕迹中的微妙推理行为方面的泛化能力。
泛化能力
在三个分布外基准测试(包括ARC-C、GPQA-diamond和MMLU-Pro)上,LUFFY也展现出了强大的泛化能力。尽管SFT在数学推理任务上取得了竞争性的结果,但它在与训练分布差异显著的领域中的泛化能力较差。相比之下,LUFFY在MMLU-Pro基准测试上显著优于SFT和On-Policy RL,显示出其在面对新领域和任务时的鲁棒性。
训练动态
在训练过程中,LUFFY最初主要通过模仿非策略痕迹来学习,随着训练的进行,策略演示逐渐占据主导地位,促进了模型在自身采样空间内的独立探索。这种动态平衡使得LUFFY能够在保持高熵的同时提高训练奖励,从而避免了在混合策略训练中出现的熵崩溃问题。此外,通过分析模型输出与非策略痕迹的相似性,本研究发现LUFFY能够选择性地内化有用的推理模式,而SFT则往往陷入对非策略演示的表面模仿。
研究局限
尽管LUFFY在多个基准测试上取得了显著的性能提升和泛化能力,但本研究仍存在一些局限性。首先,LUFFY的性能提升部分依赖于高质量的非策略推理痕迹,这些痕迹可能难以在所有领域和任务中获得。其次,虽然LUFFY通过正则化重要性抽样来塑造政策以避免肤浅模仿,但这种方法可能需要针对不同的任务和领域进行精细调整。最后,本研究主要集中在数学推理任务上,LUFFY在其他类型推理任务(如常识推理、自然语言推理等)上的表现尚需进一步验证。
未来研究方向
针对上述局限性,未来的研究可以从以下几个方面展开:
-
拓展非策略痕迹的来源:探索从多种来源(包括人类专家、其他先进模型等)获取高质量非策略推理痕迹的方法,以提高LUFFY的适用性和性能。
-
自适应政策塑造:开发能够根据不同任务和领域自动调整塑造函数的方法,以减少对人工干预的依赖并提高LUFFY的泛化能力。
-
多领域验证:将LUFFY应用于更多类型的推理任务(如常识推理、自然语言推理等),以验证其在不同领域和任务上的有效性和泛化能力。
-
结合其他技术:探索将LUFFY与其他先进技术(如课程学习、数据增强等)相结合的方法,以进一步提升模型的推理能力和泛化性能。
-
理论分析:加强对LUFFY框架的理论分析,包括其收敛性、样本复杂度等方面的研究,以提供更坚实的理论基础支持。
综上所述,LUFFY框架为在非策略指导下增强零RL的学习效果提供了一种新的思路和方法。通过结合非策略推理痕迹和策略演示,并动态平衡模仿和探索,LUFFY在提高模型推理能力和泛化性能方面展现出了显著的优势。然而,未来的研究仍需进一步探索和完善LUFFY框架,以应对更广泛的任务和挑战。

















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









