







很多同学在学习深度学习算法过程中会遇到各种各样的问题,本博文对大家普遍存在的问题进行答疑,包括写论文常需要的指标FPS如何计算得到,怎么判断模型是否收敛等问题。如有问题可通过以下方式联系我。
八、置信度框粗细等改变。这类问题比较简单,在yolov8代码中default.yaml有参数可以直接进行修改。如下所示。其中,line_width就是修改置信度框粗细的。show_conf就是设置框有无置信度的,可以看到默认是True的,当设置为False时候,就是不显示置信度。
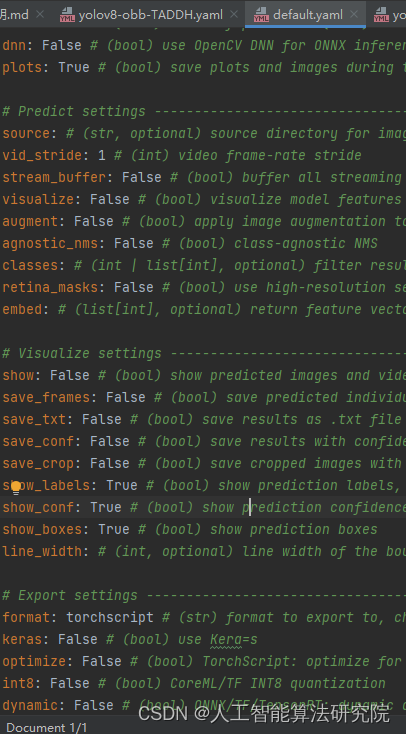
show: False # (bool) show predicted images and videos if environment allows
save_frames: False # (bool) save predicted individual video frames
save_txt: False # (bool) save results as .txt file
save_conf: False # (bool) save results with confidence scores
save_crop: False # (bool) save cropped images with results
show_labels: True # (bool) show prediction labels, i.e. 'person'
show_conf: True # (bool) show prediction confidence, i.e. '0.99'
show_boxes: True # (bool) show prediction boxes
line_width: # (int, optional) line width of the bounding boxes. Scaled to image size if None.
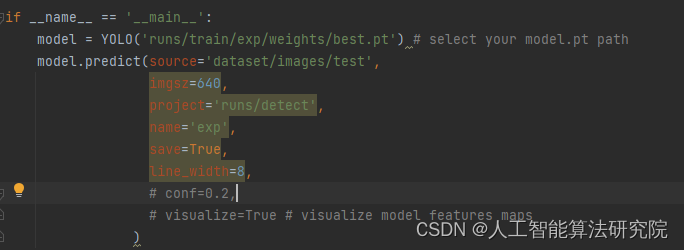
也可以直接在detect.py程序中直接设置参数。L类似这种可以将线粗调整为8.
一、Fuse指的是什么 Fuse是指模型的一些模块进行融合,最常见的就是conv和bn层进行融合,在训练的时候模型是存在conv和bn的,但在推理的过程中,模型在初始化的时候会进行模型fuse,把其中的conv和bn进行融合,通过一些数学转换把bn层融合到conv里面,还有一些例如DBB,RepVGG等等模块支持融合的,这些在fuse阶段都会进行融合,融合后可以一般都可以得到比融合前更快的推理速度,而且基本不影响精度。
二、FPS如何计算? 1. 在运行val.py后最后会出来Speed: 0.1ms preprocess, 5.4ms inference, 0.0ms loss, 0.4ms postprocess per image这行输出,这行输出就代表了每张图的前处理,推理,loss,后处理的时间,当然在val.py过程中是不需要计算loss的,所以为0,FPS最严谨来说就是1000(1s)/(preprocess+inference+postprocess),没那么严谨的话就是只除以inference的时间,还有一个问题就是batchsize应该设置为多少,其实这行输出就已经是每张图的时间了,但是batchsize还是会对这个时间有所影响,主要是关于并行处理的问题,GPU中可以一次处理多个batch的数据,也可以只处理一个数据,但是处理多batch的数据比处理一个数据的时候整体速度要快,举个例子,比如我有1000张图,我分别设置batchsize为32和batchsize为1,整体运行的时间百分之99都是batchsize为32的快,因此这就导致不同batch输出的时间不同,至于该设置多少来计算FPS,貌似众说纷纭,所以这里我也不好给意见. 附上yolov5作者对于FPS和Batch的一个实验链接: https://github.com/ultralytics/yolov5/discussions/6649 2. 项目中的get_FPS.py是只算推理时间. 3. batch问题,比如你设置为16,那所有对比的模型都在同一个batch来计算即可. 4. 小模型尽量要大bs(16,32)测.
三、训练的时候出现两次结构打印是什么情况? 第一次打印的和第二次打印的主要不同地方就是类别数,第一次打印的是yaml配置文件中的nc参数的类别数的结构,第二次打印的是你实际数据集类别数的结构,其差异就在类别数,实际使用的是第二次打印的结构.
四、保存的模型存储大小问题. 在训练图中看保存的模型大小是会比训练结束后的偏大,因为其会保存一些过程中的一些其他信息,但这些不会影响原本模型的参数量和计算量,等训练结束后,其会自己读取清除额外的信息.
五、怎么指定使用哪一种大小的模型呢? 假设我选择的配置文件是yolov8.yaml,我想选择m大小的模型,则train.py中的指定为ultralytics/cfg/models/v8/yolov8m.yaml即可,同理,如果我想指定s大小的模型,则指定为ultralytics/cfg/models/v8/yolov8s.yaml即可,如果直接设置为ultralytics/cfg/models/v8/yolov8.yaml,则默认使用n大小模型,又或者我需要使用ultralytics/cfg/models/v8/yolov8-bifpn.yaml,我需要设定为s模型,则应该为ultralytics/cfg/models/v8/yolov8s-bifpn.yaml.(V5同理)
六、怎么判断模型收敛了?模型会不会过拟合? 1. 主要看训练结束后的result.png中的精度曲线,精度曲线收敛了就可以了. 2. 很多场景的数据下在曲线上都会呈现像过拟合的趋势,但是代码中已经会自动保存best.pt,用best.pt可以避免训练后期过拟合导致的精度下降等等影响,简单来说就是只需要用best.pt即可,不需要理会过拟合的问题.
七、曲线震荡问题. 这类问题都不好解决,如果基础模型就震荡很厉害,基本都是跟数据集有关系,如果改进后的模型后出现,基本都是改进模型不合适的问题.

















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











