






【yolo12】使用自己的数据集训练目标检测模型
一、anaconda安装
直接参考这篇博客:
https://blog.csdn.net/m0_71523511/article/details/136546588
pycharm开发环境参考:
https://www.bilibili.com/video/BV1Cr4y1u76N/?p=3&spm_id_from=pageDriver&vd_source=2a10d30b8351190ea06d85c5d0bfcb2a
二、环境配置
打开anaconda命令行:

conda create -n yolov12 python=3.9
conda activate yolov12
#注意这里要在windows下跑,就不能下载txt中的whl文件,所以删除flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
pip install -r requirements.txt
pip install -e .
这里需要将ultralytics/nn/modules/block.py里面的第1160-1164行注释,然后将1219行的# if x.is_cuda:改成# if False。
这样才可以不使用flash_attn_func加速计算,使用下面的分支效果是一样的,只是慢一点。
三、数据集制作
1、labelimg的安装
首先打开cmd命令行(快捷键:win+R)。进入cmd命令行控制台。输入如下的命令:`
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple
2、使用labelimg`
①搜索labelimg

②设置

格式选择yolo,然后点击open dir,选择存放待打标图片的文件夹,点击change save dir来更改保存标签的文件夹。
③打标
常用快捷键如下:
A:切换到上一张图片
D:切换到下一张图片
W:调出标注十字架
del :删除标注框框
Ctrl+u:选择标注的图片文件夹
Ctrl+r:选择标注好的label标签存在的文件夹

这样标注完之后可以在保存标签的目录看到yolo格式的标签,它会自己生成一个类别文件:

四、正片
1、下载yolo12源码
https://github.com/sunsmarterjie/yolov12
解压后目录如下:
2、数据集目录
将前面打标好的数据集以下面这种目录格式放置,并新建data.yaml文件:
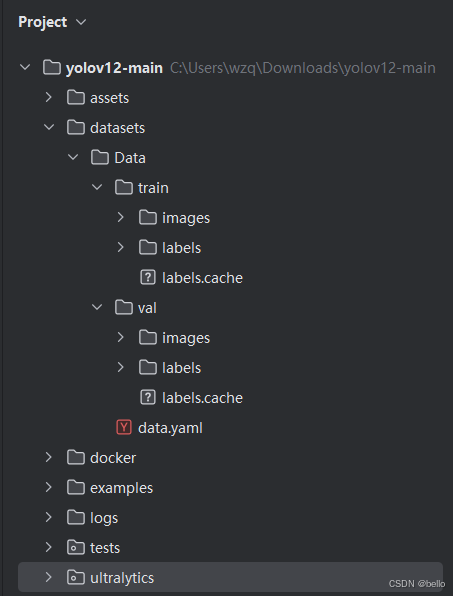
data.yaml文件如下:
names根据自己数据集的标签来,train和val就是训练集和验证集的图片路径
train: C:/new_pycharm_project/yolo12-main/datasets/Data/train/images
val: C:/new_pycharm_project/yolo12-main/datasets/Data/val/images
# Classes
nc: 3 # number of classes
names: ['person', 'hat', 'one'] # class names
3、训练
在数据集的同级目录下新建一个train.py文件:
from ultralytics import YOLO
model = YOLO('./ultralytics/cfg/models/v12/yolov12.yaml')
# Train the model
results = model.train(
data='./datasets/Data/data.yaml',
epochs=600,
batch=4,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device="cpu",
)
右击开始训练:
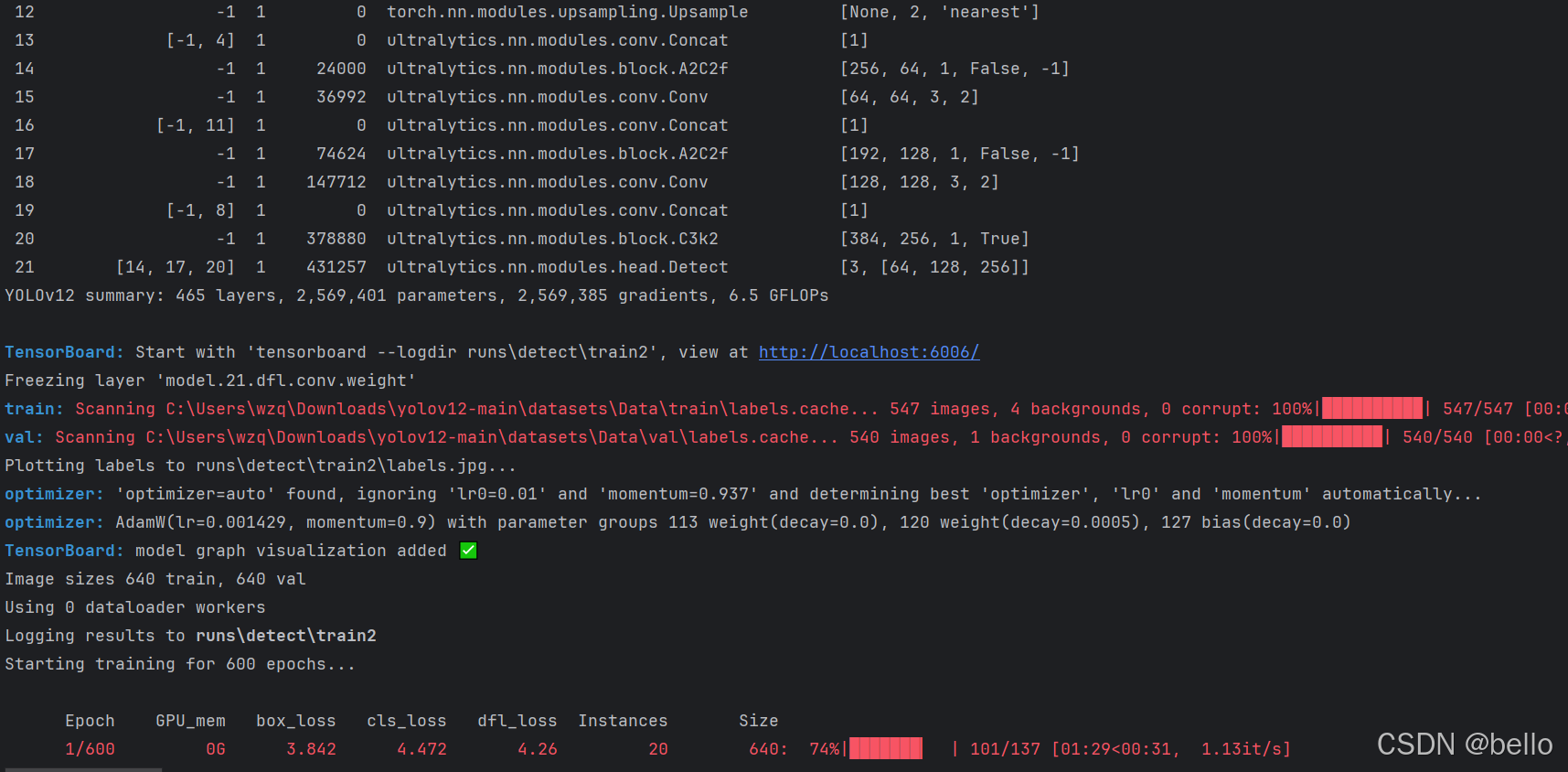
等待训练结束之后可以在runs目录下找到权重文件。
4、推理
在数据集的同级目录下新建一个infer.py文件,并放置一张待检测的图片名字为infer.jpg:
from ultralytics import YOLO
model = YOLO('yolov12{n/s/m/l/x}.pt')
model.predict()
运行结果如下:



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









