






“多模态+注意力机制”是当前深度学习领域的热门研究方向,其组合优势显著。
多模态学习能够融合来自不同来源的信息,为模型提供更丰富、更全面的数据输入。注意力机制则能够从这些信息中筛选出关键内容,使模型更加专注于对任务有用的部分。两者的结合,让模型在处理复杂任务时能够展现出更高的准确性和鲁棒性。
我整理了9篇最新多模态+注意力机制的研究论文,需要的同学添加工中号【真AI至上】 回复 多模态注意 即可全部领取
ADAPTIVE AND EMBEDDED FUSION FOR EFFICIENT VISION-LANGUAGE TUNING
文章解析:
本文提出了一种高效的视觉-语言调优框架ADEM-VL,通过在预训练大语言模型(LLMs)的中间层采用无参数交叉注意力机制和多尺度特征生成方案,显著减少了可训练参数数量,加速了训练和推理速度。
此外,该框架还引入了自适应融合方案,动态地丢弃与文本令牌相关性较低的视觉信息,确保融合过程优先关注最相关的视觉特征。
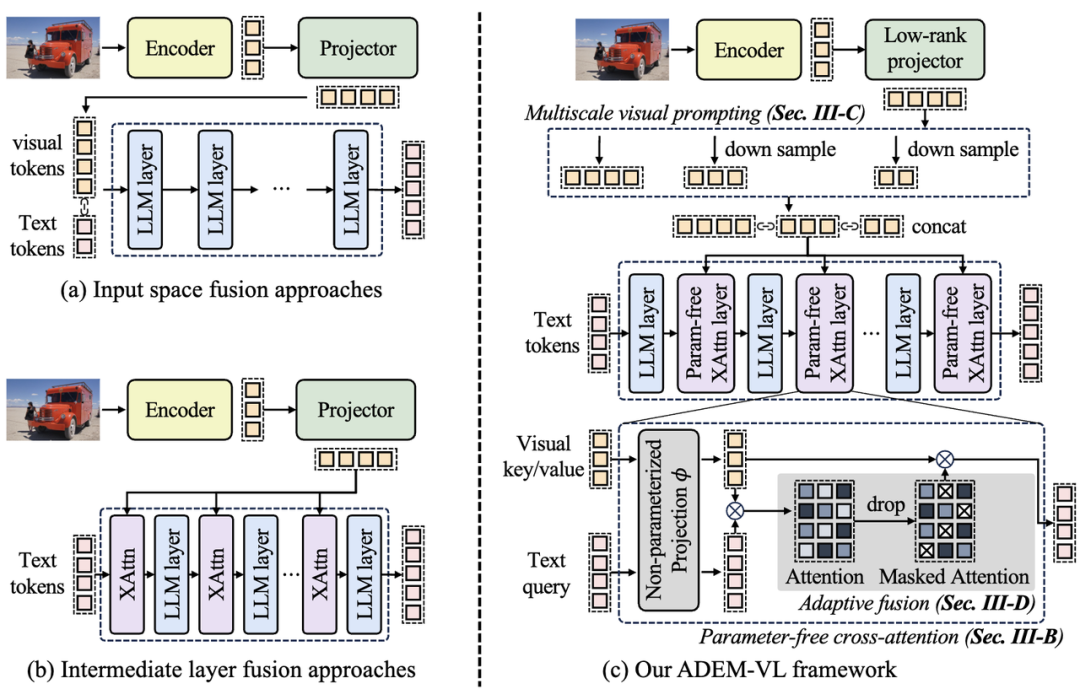
创新点:
1.提出了一种无参数交叉注意力机制,显著减少了可训练参数数量。
2.引入了多尺度特征生成方案,仅需一次前向传播即可生成多尺度视觉特征。
3.提出了自适应融合方案,动态地丢弃与文本令牌相关性较低的视觉信息。
4.在多个视觉-语言任务上取得了优于现有方法的性能,同时减少了训练和推理延迟。
CROC: PRETRAINING LARGE MULTIMODAL MODELS WITH CROSS-MODAL COMPREHENSION
文章解析:
本文提出了一种新的预训练范式,旨在通过引入跨模态理解阶段来增强大型语言模型(LLMs)的视觉理解能力。该方法设计了一个动态可学习的提示词池,并使用匈牙利算法选择性地替换部分原始视觉词元,同时提出了混合注意力机制和详细的图像描述生成任务,以进一步提高LLMs对视觉语义信息的理解。
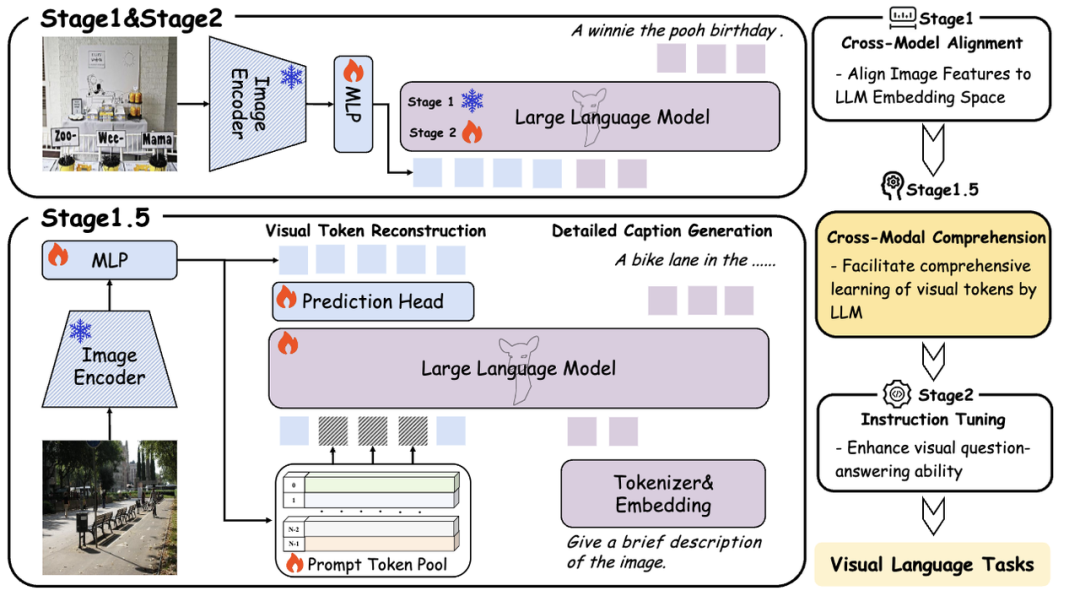
创新点:
1.引入了跨模态理解阶段,结合视觉词元重构和详细图像描述生成任务。
2.设计了一个动态可学习的提示词池,使用匈牙利算法选择性地替换部分原始图像词元。
3.提出了混合注意力机制,包括双向视觉注意力和单向文本注意力,以改善视觉词元的理解。
添加工中号【真AI至上】 回复 “多模态注意” 即可领取【多模态+注意力机制】系列论文
CROSS-GAiT: Cross-Attention-Based Multimodal Representation Fusion for Parametric Gait Adaptation in Complex Terrains
文章解析:
本文介绍了一种名为CROSS-GAiT的新算法,该算法通过交叉注意力机制融合视觉和时间序列输入(包括线性加速度、角速度和关节力)生成的地形表示,以动态调整四足机器人的步高和髋部张开度,从而在复杂地形中实现自适应步态。
实验结果表明,CROSS-GAiT在多种复杂地形中表现出色,显著提高了导航性能和稳定性。在四个复杂场景中的成功率提高了64.5%,到达目标的时间减少了4.91%。在地形分类任务上的表现比现有方法高出4.48%。
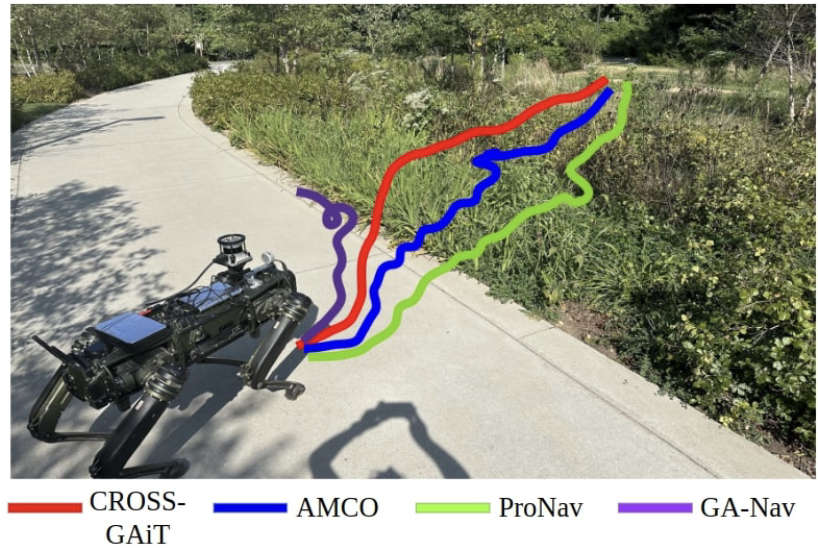
创新点:
1.提出了一种新的融合算法,通过交叉注意力机制将视觉数据与时间序列数据(线性加速度、角速度和本体感觉)的潜在表示进行融合,生成环境的综合潜在表示。
2.开发了一种参数化步态适应算法,通过调整步高和髋部张开度生成自定义步态,提高了稳定性和减少了关节努力。
3.实现了实时系统,在Intel NUC 11上以60 Hz运行,展示了在复杂地形中的优异性能。
MHS-STMA: Multimodal Hate Speech Detection via Scalable Transformer-Based Multilevel Attention Framework
文章解析:
本文提出了一种可扩展的多模态仇恨言论检测架构——基于Transformer的多层级注意力机制(STMA)。该架构通过结合文本和图像数据的多层级注意力机制,有效捕捉了文本和视觉特征之间的语义关联,并在多个数据集上验证了其优越性。

创新点:
1.提出了STMA框架,通过多层级注意力机制有效建模多模态数据中的文本和非文本特征交互。
2.引入了多头注意力(MHA)机制,整合不同注意力层级的数据,捕捉文本和非文本特征之间的多种交互。
3.通过三个公开数据集评估了方法的性能,并与现有最先进方法进行了对比,验证了模型的有效性。

















 8604
8604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









