







写在前面
自然语言处理是人工智能领域的一个重要分支,旨在使计算机能够理解、处理和生成人类语言。随着信息技术的飞速发展,全球范围内的文本数据呈指数级增长,如何高效地处理和分析这些海量语言信息成为了一个亟待解决的问题。NLP的研究不仅涉及语言学、计算机科学、认知科学等多个学科的交叉,还在机器翻译、信息检索、自动文摘、问答系统等实际应用中展现出巨大的潜力。然而,自然语言的复杂性、歧义性以及不断变化的语言现象也给NLP带来了诸多挑战。通过结合理性主义和经验主义的研究方法,NLP正在逐步突破技术瓶颈,为人类提供更加智能化的语言处理服务。
本系列文章是我的学习笔记,涵盖了入门的基础知识与模型以及对应的上机实验,截图截取自老师的课程ppt。
- 概论
- 词汇分析--词法分析和词性标注
- 句法分析
- 语篇分析
- 语义分析
- 语义计算
- 语言模型
- 文本摘要
- 情感分析
- 部分对应上机实验
目录
未登录词(Out-of-Vocabulary, OOV)识别
概述
词是自然语言中能够独立运用的最小单位,是自然语言处理的基本单位。
自动词法分析就是利用计算机对自然语言的形态 (morphology) 进行分析,判断词的结构和类别等。
- 曲折语(如,英语、德语、俄语等):用词的形态变化表示语法关系,一个形态成分可以表示若干种不同的语法意义,词根和词干与语词的附加成分结合紧密。
- 分析语(孤立语)(如:汉语):分词。
- 黏着语(如:日语等):分词+形态还原。
词性或称词类(Part-of-Speech, POS)是词汇最重要的特性,是连接词汇到句法的桥梁。
英语的形态分析
英语的形态分析的基本任务为:单词识别和形态还原。
英语中常见的特殊形式的单词识别整理
- (1) prof., Mr., Ms. Co., Oct. 等放入词典;
- (2) Let's / let's => let + us
- (3) I'm => I + am
- (4) {it, that, this, there, what, where}'s => {it, that, this, there, what, where} + is
- (5) can't => can + not; won't => will + not
- (6) {is, was, are, were, has, have, had}n't => {is, was, are, were, has, have, had} + not
- (7) X've => X + have; X'll=> X + will; X're => X + are
- (8) he's => he + is / has => ?; she's => she + is / has => ?
- (9) X'd Y => X + would (如果 Y 为单词原型) ;=> X + had (如果 Y 为过去分词)
英语单词的形态还原规则
有规律变化单词的形态还原
-
-ed结尾的动词过去时还原
- 规则:去掉
-ed或调整拼写。 - 例子:
worked → work(直接去掉-ed);believed → believe(去-ed加-e)。
- 规则:去掉
-
-ing结尾的现在分词还原
- 规则:去掉
-ing或调整拼写。 - 例子:
developing → develop(直接去掉-ing);saving → save(去-ing加-e)。
- 规则:去掉
-
-s结尾的动词单数第三人称还原
- 规则:去掉
-s或调整拼写。 - 例子:
works → work(直接去掉-s);studies → study(-ies变-y)。
- 规则:去掉
-
-ly结尾的副词还原
- 规则:去掉
-ly。 - 例子:
hardly → hard。
- 规则:去掉
-
-er/est结尾的形容词比较级/最高级还原
- 规则:去掉
-er或-est。 - 例子:
colder → cold;easier → easy(-ier变-y)。
- 规则:去掉
-
名词复数还原(-s/-es/-ies/-ves等)
- 规则:调整拼写。
- 例子:
bodies → body(-ies变-y);shelves → shelf(-ves变-f)。
-
名词所有格还原(X’s/Xs’)
- 规则:去掉所有格标记。
- 例子:
John’s → John。
不规则变化单词的形态还原
- 建立不规则变化词表,直接查表还原。
- 动词:
chose → choose;chosen → choose。 - 名词:
axes → axis。 - 形容词:
worst → bad。
- 动词:
数字、时间、货币等特殊形式的形态还原
- 年代还原:
1990s → 1990(标记为时间名词)。 - 序数词还原:
87th → 87(去掉-th并标记为序数词)。 - 货币还原:
$20 → 20(去掉$并标记为名词)。 - 百分数还原:
98.5% → 98.5%(整体作为数词保留)。
合成词的形态还原
- 总之就是去除连词符
- 分数词还原:
one-fourth → one fourth。 - 合成名词还原(名词+名词/形容词+名词等):
Human-computer → Human computer。 - 合成形容词还原(形容词+名词+ed/副词+分词等):
machine-readable → machine readable。 - 合成动词还原(名词+动词/副词+动词等):
job-hunt → job hunt。 - 其他带连字符的合成词:
co-operate → cooperate;text-to-speech → text to speech。
- 分数词还原:
英语的形态分析的一般方法
- 1) 查词典,如果词典中有该词,直接确定该词的原形;
- 2) 根据不同情况查找相应规则对单词进行还原处理,如果还原后在词典中找到该词,则得到该词的原形;如果找不到相应变换规则或者变换后词典中仍查不到该词,则作为未登录词处理;
- 3) 进入未登录词处理模块。
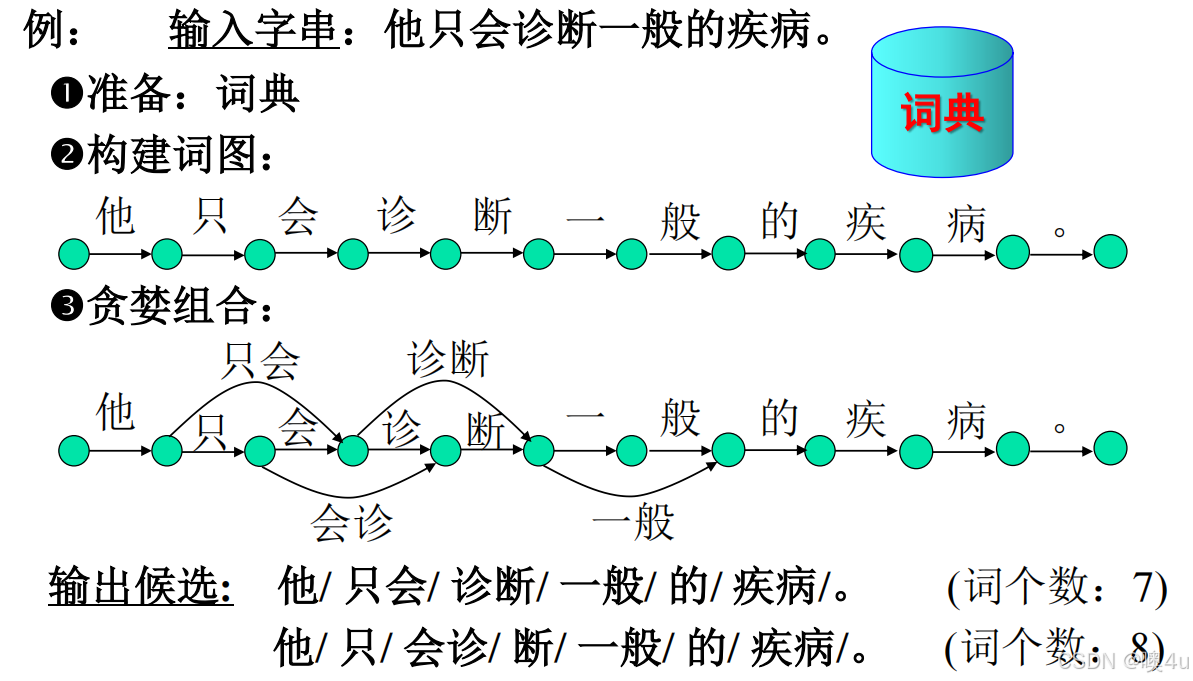
汉语的分词(概要)
汉语自动分词的重要性
- 基础作用:分词是汉语句子分析的基础。
- 应用广泛:用于词频统计、词典编纂、文章风格研究等。
- 文本处理:以词语作为文本特征。
- 辅助功能:用于文本校对、同音字识别、多音字辨识、简繁体转换等(“以词定字、以词定音”)。
汉语自动分词中的主要问题
汉语分词规范问题
-
国家标准:《信息处理用限定汉语分词规范(GB13715)》。
-
模糊边界:
-
单字词 vs. 词素(如:“新华社25日讯”中的“讯”是单字词还是词素?)。
-
词 vs. 短语(如:“花草”、“湖边”、“房顶”等是否应合并为一个词?)。
-
歧义切分字段处理
-
交集型歧义(链长≥2):
-
例:中国人为了实现自己的梦想” → 可切分为:
-
“中/国人/为了/实现/自己/的/梦想”
-
“中国人/为了/实现/自己/的/梦想”
-
-
其他例子:“研究生物”、“从小学起”、“为人民工作”。
-
链长定义:歧义字段的交集串个数(如“结合成分子”的链长为3,交集串={合, 成, 分})。
-
-
组合型歧义(同一字串可切分为不同词):
-
例:“门把手弄坏了” → 可切分为:
-
“门/把手/弄/坏/了”
-
“门/把/手/弄/坏/了”
-
-
其他例子:“将来”、“现在”、“才能”、“学生会”。
-
梁南元(1987)统计显示,中文文本中切分歧义的出现频度约为1.2次/100字,交集型歧义与组合型歧义的比例约为12:1。
-
未登录词的识别
-
命名实体:
- 人名(如:“盛中国”、“令计划”、“爱新觉罗·溥仪”)。
- 地名(如:“武夷山”、“米苏拉塔”)。
- 组织机构名(如:“大不列颠及北爱尔兰联合王国外交部”)。
-
新词/术语/俗语(如:“博客”、“非典”、“微信”、“给力”)。
-
统计结果(基于418个句子):
- 错误主要来自未登录词(占比约55%),其中:人名(25.83%)、地名(9.17%)、组织机构名(8.33%)、时间和数字(11.67%)。
- 普通生词(40%)和专业术语(3.33%)。
- 切分起义(1.67%)
汉语自动分词的基本原则
合并原则(应合并为一个分词单位的情况)
-
语义不可直接相加:
- 成语(如:“不管三七二十一”)。
- 副词短语(如:“或多或少”)。
- 定名结构(如:“六月”)。
- 定量结构(如:“下午/十三点”)。
- 重叠结构(如:“谈谈”、“辛辛苦苦”)。
- 合并结构(如:“进出口”)。
-
语法功能不符合组合规律:如:“好吃”、“好喝”、“游水”。
-
附着性语素合并:如:“吝”(不吝于)、“员”(邮递员)、“化”(现代化)。
-
高频共现字串:如:“进出”(动词并列)、“大笑”(动词偏正)、“关门”(动宾结构)、“象牙”(名词偏正)、“男女”(并列结构)、“暂不”(副词并列)。
-
双音节+单音节的偏正式名词:如:“分数线”、“领导权”、“垃圾车”、“着眼点”。
-
(双音节结构的偏正式动词)少数偏正式动词:如:“紧追其后”、“组建完成”。
切分原则(应切分的情况)
-
有明显分隔符:如:“上、下课” → “上/下课”。
-
内部结构复杂或冗长:如:“太空/计划/室”(词组带结尾词)、“看/清楚”(动词带双音节结果补语)、“自来水/公司”(复杂结构)、“喜欢/ 不/ 喜欢”(正反问句)、“写信/给”(动宾/述补结构带词缀)、“鲸鱼/ 的/ 生/ 与/ 死”(词组或句子的专名,多见于书面语,戏剧名、歌曲名等)、“胡/先生”、“京沪/铁路”(专名带普通名词)。
汉字自动分词的基本算法
最大匹配法(Maximum Matching, MM)
基本思想
-
机械切分:从句子的一端(正向/逆向)按词典中最长词的长度截取字串,匹配词典,若不匹配则减少长度继续尝试。
-
变种:
-
正向最大匹配(FMM):从左向右扫描。
-
逆向最大匹配(BMM):从右向左扫描。
-
双向最大匹配(Bi-MM):结合FMM和BMM,选择更合理的切分。
-
算法描述
-
初始化:词典
word_dict,最大词长max_len。 -
从句子起始位置截取
max_len个字符,检查是否在词典中。 -
若匹配,切分并移动指针;否则减少长度继续匹配。
-
单字直接切分(未登录词处理)。
优缺点
-
优点:仅需要很少的语言资源(词表),简单、速度快,仅需词典资源。
-
缺点:歧义消解能力差(如“研究生物”可能误切为“研究生/物”)。
def max_match(sentence, word_dict, max_len=5):
words = []
sentence_len = len(sentence)
idx = 0
while idx < sentence_len:
matched = False
for l in range(min(max_len, sentence_len - idx), 0, -1):
candidate = sentence[idx: idx+l]
if candidate in word_dict:
words.append(candidate)
idx += l
matched = True
break
if not matched: # 单字切分
words.append(sentence[idx])
idx += 1
return words
# 示例
word_dict = {"研究", "研究生", "生物", "化学", "中国", "人", "实现", "梦想"}
sentence = "中国人为了实现自己的梦想"
print("FMM:", max_match(sentence, word_dict)) # 输出:['中国', '人', '为了', '实现', '自己', '的', '梦想']最少分词法(最短路径法)
基本思想
-
动态规划:将句子视为有向无环图(DAG),节点为字边界,边为词典中的词,寻找最短路径(词数最少)。
算法描述
-
构建词图:遍历所有可能的词组合,形成边。
-
用Dijkstra算法求最短路径(词数最少)。
优缺点
-
优点:符合汉语“词数最少”的直觉。
-
缺点:无法解决多最短路径问题(如“他说的确实在理”可能切分为“他/ 说/ 的/ 确实/ 在理/。”或“他/ 说/ 的确/ 实在/ 理/ 。”)。
import networkx as nx
def shortest_path_seg(sentence, word_dict):
graph = nx.DiGraph()
n = len(sentence)
graph.add_nodes_from(range(n + 1)) # 节点0~n
# 添加边(词)
for i in range(n):
for j in range(i + 1, min(i + 5, n) + 1): # 假设最大词长5
if sentence[i:j] in word_dict:
graph.add_edge(i, j, word=sentence[i:j])
# 求最短路径
path = nx.shortest_path(graph, 0, n)
words = [graph.edges[path[i], path[i+1]]['word'] for i in range(len(path)-1)]
return words
# 示例
word_dict = {"他", "说", "的", "确实", "在理", "的确", "实在"}
sentence = "他说的确实在理"
print("最短路径分词:", shortest_path_seg(sentence, word_dict)) # 输出:['他', '说', '的', '确实', '在理']基于统计语言模型的分词方法
基本思想
-
概率最大化:选择使句子概率最大的分词方式,使用N-gram语言模型(如Bigram)。
算法描述
-
生成所有可能的分词组合。
-
计算每种组合的联合概率(如Bigram:
-
选择概率最高的分词结果。
优缺点
-
优点:能利用上下文信息,解决部分歧义。
-
缺点:依赖大规模训练语料,计算复杂度高。
from itertools import product
def generate_segments(sentence, word_dict, max_len=5):
n = len(sentence)
segments = [[] for _ in range(n + 1)]
for i in range(n):
for j in range(i + 1, min(i + max_len, n) + 1):
if sentence[i:j] in word_dict:
segments[j].append(sentence[i:j])
return segments
def lm_seg(sentence, word_dict, bigram_model):
segments = generate_segments(sentence, word_dict)
n = len(sentence)
dp = [{} for _ in range(n + 1)] # dp[i]: {word: (prob, prev)}
dp[0][""] = (1.0, None) # 初始状态
for i in range(1, n + 1):
for word in segments[i]:
for prev_word in dp[i - len(word)]:
prob = dp[i - len(word)][prev_word][0] * bigram_model.get((prev_word, word), 1e-10)
if word not in dp[i] or prob > dp[i][word][0]:
dp[i][word] = (prob, prev_word)
# 回溯最优路径
path = []
current_word = max(dp[n], key=lambda x: dp[n][x][0])
i = n
while i > 0:
path.append(current_word)
i -= len(current_word)
current_word = dp[i][current_word][1]
return list(reversed(path))
# 示例(简化版Bigram模型)
word_dict = {"中国", "人", "为了", "实现", "梦想"}
bigram_model = {("中国", "人"): 0.5, ("人", "为了"): 0.3, ("为了", "实现"): 0.4, ("实现", "梦想"): 0.6}
sentence = "中国人为了实现梦想"
print("语言模型分词:", lm_seg(sentence, word_dict, bigram_model)) # 输出:['中国', '人', '为了', '实现', '梦想']由字构词(基于字标注)的分词方法
基本思想
-
将分词过程看作是字的分类问题。该方法认为,每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位)。假定每个字只有4个词位:词首(B)、词中(M)、词尾(E)和单独成词(S),那么,每个字归属一特定的词位。
优缺点
-
该方法的重要优势在于,它能够平衡地看待词表词和未登录词的识别问题,文本中的词表词和未登录词都是用统一的字标注过程来实现的。在学习构架上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词识别模块,因此,大大地简化了分词系统的设计[黄昌宁,2006]
# 需安装sklearn-crfsuite:pip install sklearn-crfsuite
import sklearn_crfsuite
# 示例:CRF标注(简化版)
train_data = [
(["中", "国"], ["B", "E"]), # "中国" → B/E
(["研", "究", "生"], ["B", "M", "E"]), # "研究生" → B/M/E
]
X_train = [[{"char": c} for c in sent] for sent, _ in train_data]
y_train = [tags for _, tags in train_data]
crf = sklearn_crfsuite.CRF(algorithm="lbfgs")
crf.fit(X_train, y_train)
# 预测
test_sentence = ["研", "究", "生", "物"]
X_test = [[{"char": c} for c in test_sentence]]
pred_tags = crf.predict(X_test)[0]
print("CRF标注结果:", pred_tags) # 输出:['B', 'M', 'E', 'S'] → "研究生/物"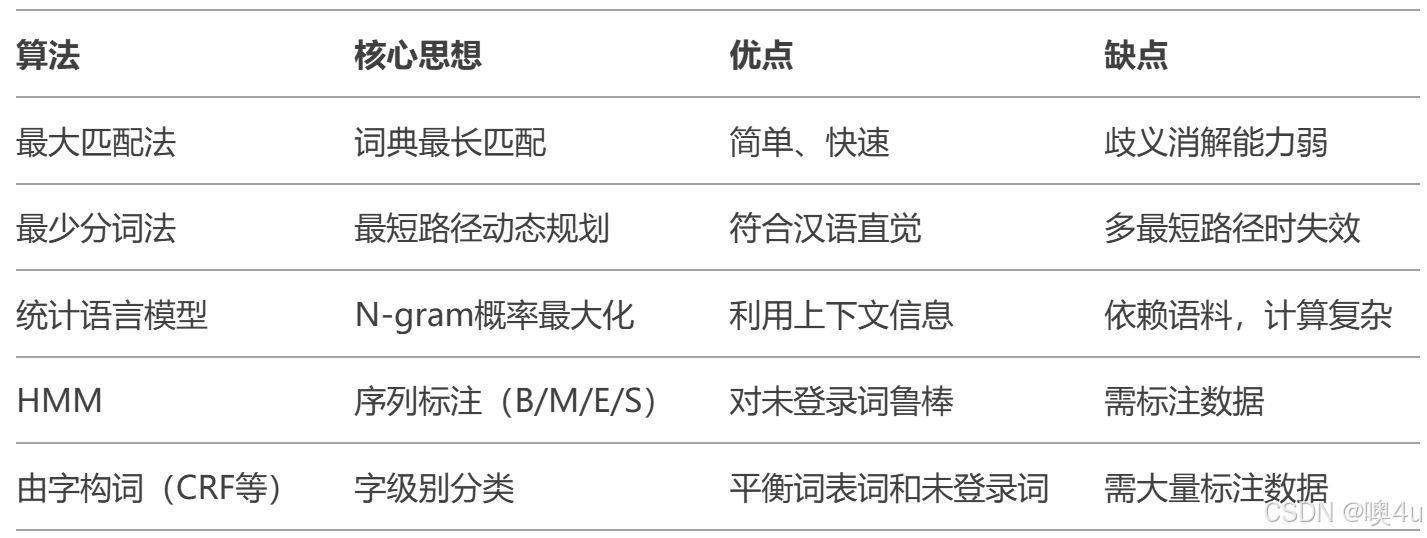
生成式方法与区分式方法的结合
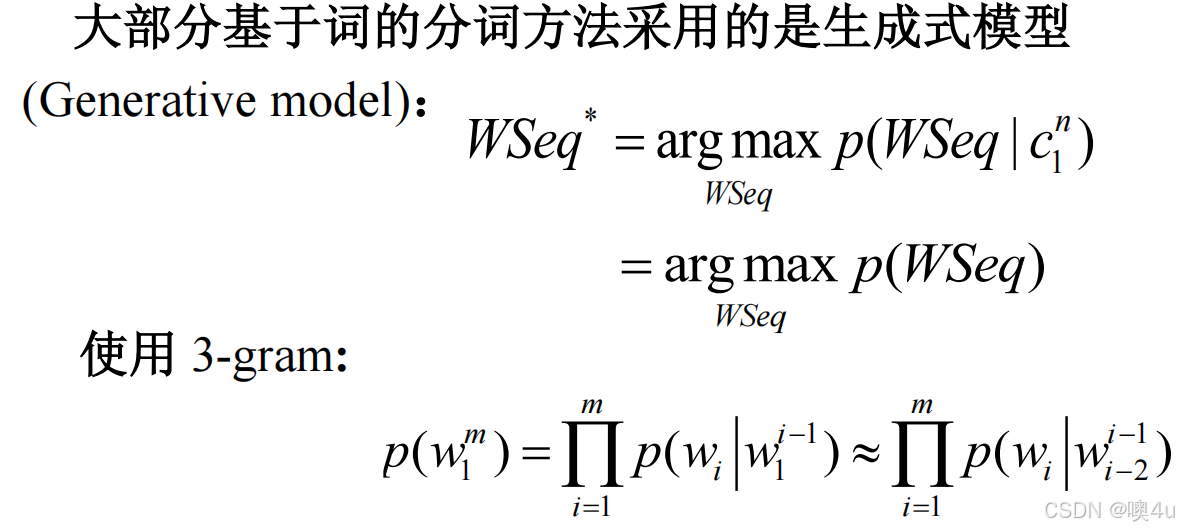
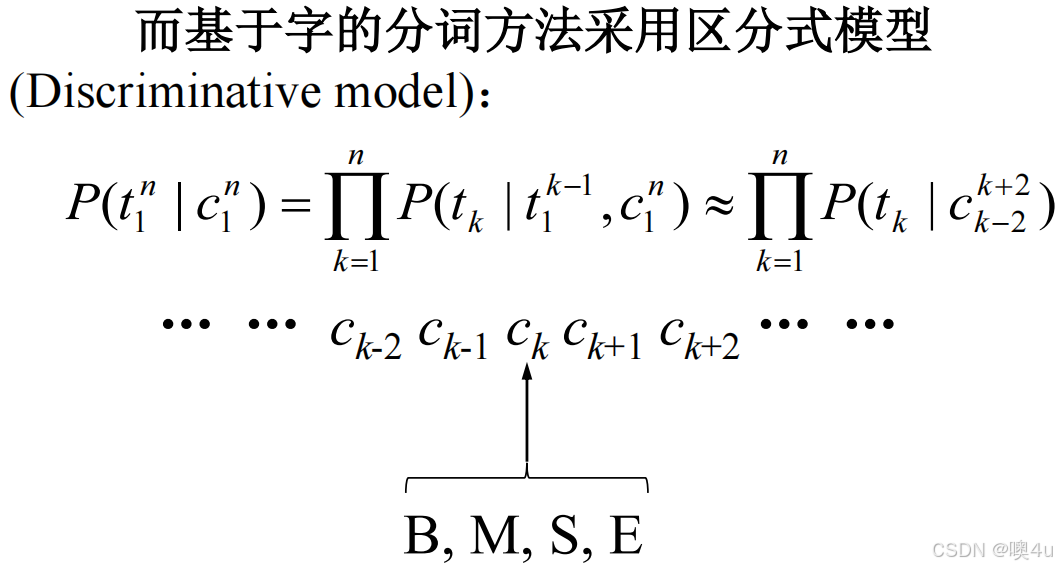
基于字的区分模型有利于处理集外词,而基于词的生成模型更多地考虑了词汇之间以及词汇内部字与字之间的依存关系。因此,可以将两者的优势结合起来。
- 结合方法1:将待切分字串的每个汉字用
替代,以
作为基元,利用语言模型选取全局最优(生成式模型)。

- 结合方法2:插值法把两种方法结合起来

其他分词方法
- 全切分方法
- 串频统计和词形匹配相结合的分词 方法
- 规则方法与统计方法相结合
- 多重扫描法
- .......
未登录词(Out-of-Vocabulary, OOV)识别
- 命名实体(Named Entity, NE)(专有名词)
- 人名(中国人名和外国译名)
- 中国目前仍使用的姓氏共 737 个,其中,单姓 729个,复姓 8 个
- 难点:
- 名字用字范围广,分布松散,规律不很明显。
- 姓氏和名字都可以单独使用用于特指某一人。
- 许多姓氏用字和名字用字(词)可以作为普通用字或词被使用,例如,姓氏为普通词:于(介词),张(量词),江(名词)等;名字为普通词:建国,国庆,胜利,文革,计划等,全名也是普通词汇,如:万里,温馨,高山,高升,高飞,周密,
江山,夏天等。 - 缺乏可利用的启发标记(“祝贺老总百战百胜。”)。
- 方法:
- 姓名库匹配,以姓氏作为触发信息,寻找潜在的名字。
- 计算潜在姓名的概率估值及相应姓氏的姓名阈值(threshold value),根据姓名概率评价函数和修饰规则对潜在的姓名进行筛选。





-
示例:输入句子:“詹祖里已被授权组建政府”
识别步骤:-
“詹”在姓氏库中 → 触发人名检测。
-
“祖里”作为名字计算概率 P(詹祖里)
-
概率超过阈值 → 输出
[詹祖里/PER]。
-
- 地名、组织机构名
- 难点:地名数量大,缺乏明确、规范的定义。《中华人民共和国地名录》(1994)收集88026个,不包括相当一部分街道、胡同、村庄等小地方的名称。真实语料中地名出现情况复杂。如地名简称、地名用词与其他普通词冲突、地名是其他专用名词的一部分,地名长度不一等。
- 方法:
- 统计模型
- 找到一机构称呼词,根据相应规则往前逐个检查名词作为修饰名词(形容词、名词)的合法性,直到发现非法词
- 通过训练语料选取阈值
- 地名初筛选
- 寻找可以利用的上下文信息
- 利用规则进一步确定地名
- 词法(偏正式(修饰格式)的复合词{名词|形容词|数量词|动词} + 名词)
- 句法(“定语+名词性中心语”型的名词短语(定名型短语))
- 中心语(机构称呼词,如:大学,学院,研究所,学会,公司等。)
-
地名示例:输入句子:“武夷山位于福建省”
识别步骤:-
“武夷山”在地名库中 → 直接匹配。(规则匹配)
-
“福建省”通过后缀“省”识别 → 输出
[武夷山/LOC] [福建省/LOC]。
-
-
机构名示例:输入句子:“赛福鼎·艾则孜访问北京大学”
识别步骤:-
“大学”为中心词 → 向左合并“北京”。(中心词检测)
-
输出
[赛福鼎·艾则孜/PER] [访问/V] [北京大学/ORG]。
-
-
-
采用双语联合识别方法校对错误的识别边界

-
基于神经网络的命名实体识别
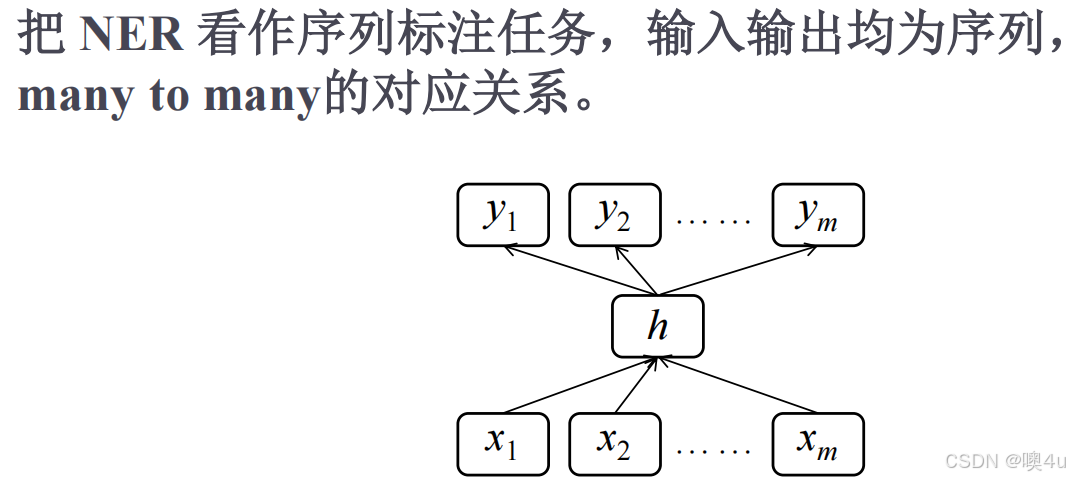
- 输入:字序列(如“詹祖里”)。
- 输出:B/M/E/S标签序列(如“B-PER E-PER”)。
- 常用模型:
- BiLSTM-CRF:结合上下文信息和标签约束。
# 需安装PyTorch和transformers import torch from transformers import BertTokenizer, BertForTokenClassification tokenizer = BertTokenizer.from_pretrained("bert-base-chinese") model = BertForTokenClassification.from_pretrained("bert-base-chinese", num_labels=4) # B/M/E/S inputs = tokenizer("詹祖里访问北京大学", return_tensors="pt") outputs = model(**inputs).logits pred_labels = torch.argmax(outputs, dim=-1)[0] # 预测标签 print("NER结果:", tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]), pred_labels) - Radical-LSTM:利用汉字偏旁特征(如“湖”的“氵”提示地名)。
- BiLSTM-CRF:结合上下文信息和标签约束。
- 统计模型
- 数字
- 日期
- 货币数量
- 人名(中国人名和外国译名)
- 其他新词
- 专业术语
- 新的普通词汇等。
词性标注
词性(part-of-speech, POS)标注(tagging)的主要任务是消除词性兼类歧义。在任何一种自然语言中,词性兼类问题都普遍存在。
- "Time flies like an arrow." → "flies"(动词) vs. "Flies"(名词,复数)。
- “会”:名词(“会议”) vs. 动词(“能够”)。
统计数据:
- 英语(Brown语料库):55%的词次存在兼类。
- 汉语(《现代汉语八百词》):22.5%的常用词兼类。
标注集一般原则:
- 标准性: 普遍使用和认可的分类标准和符号集;
- 兼容性: 与已有资源标记尽量一致,或可转换;
- 可扩展性:扩充或修改。
词性标注集的确定原则:
- 标准性:采用通用分类标准(如北大标注集、Penn Treebank)。
- 兼容性:与现有标注规范兼容(如ICTCLAS vs. LDC)。
- 可扩展性:支持新增标签(如社交媒体中的新兴词类)。
主流词性标注集:
-
UPenn Treebank(英语):
- 33类,如
NN(名词)、VB(动词)、JJ(形容词)。 - 特点:强调“可恢复性”(能从标注还原原句)。
- 33类,如
-
北大中文标注集(汉语):
-
26个基本类 + 74个扩展类(共106标签),如:
- 名词(
n)、时间词(t)、动词(v)、形容词(a)。 - 特殊类:成语(
i)、习用语(l)、非语素字(x)。
- 名词(
-
词性标注方法
基于规则的方法
手工规则消歧
-
TAGGIT系统(Brown University):
- 86种词性,3300条手工规则。
- 例子:若单词前有冠词(
a/an/the),则优先标注为名词。
-
山西大学系统:
-
规则类型:
-
并列鉴别:如“要求和愿望” → “要求”与“愿望”同词性(名词)。
-
区别词标记:如“大型调查” → “大型”(区别词)后接名词。
-
-
词缀与重叠规则
-
词缀规则:形容词后缀:
-茵茵(“绿油油”)、-化(“现代化”)。 -
重叠规则:
- 动词重叠:
看看(尝试态)、讨论讨论。 - 形容词重叠:
高高兴兴(加强语气)。
- 动词重叠:
基于统计的方法
隐马尔可夫模型(HMM)
-
基本思想:
- 将词性作为隐藏状态,词语作为观测序列。
- 通过Viterbi算法求解最优词性路径。
-
关键参数:
- 转移概率(词性A→词性B)。
- 发射概率(词性生成某词语的可能性)。
最大熵模型(ME)
- 特点:利用上下文特征(如前后词、前缀/后缀)进行概率建模。
- 例子:若当前词为“研究”,前词为“进行” → 标注为名词(
n)。
规则与统计结合的方法
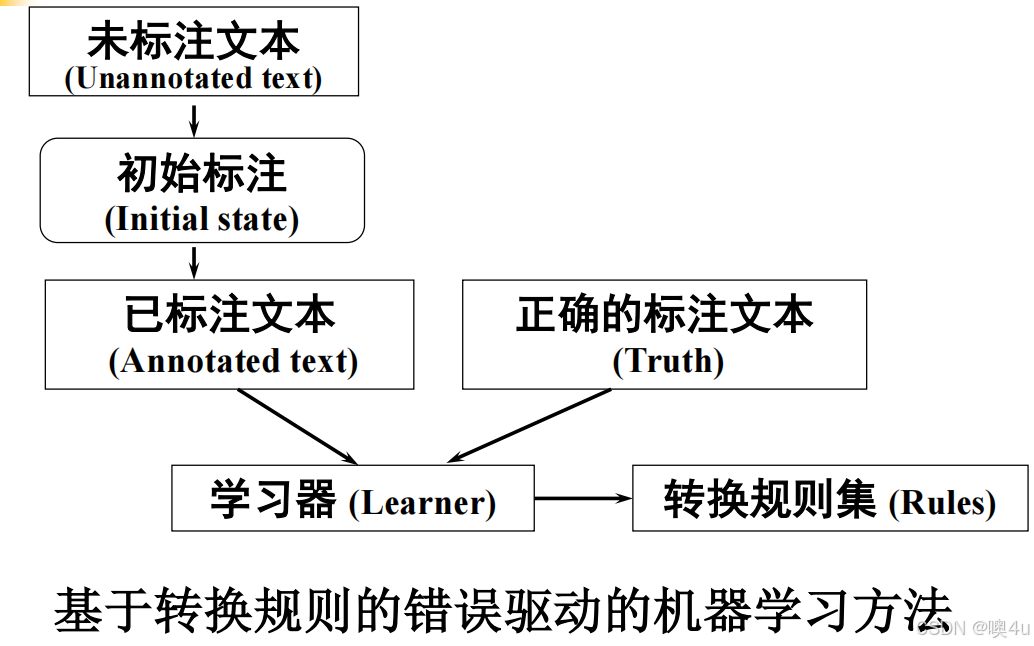
Brill标注器(错误驱动学习):
-
初始标注:用统计方法(如HMM)生成初始词性。
-
学习转换规则:对比正确标注,自动生成修正规则(如“若前词是冠词,且当前词以
-ing结尾,则改为名词”)。
混合策略:先用统计方法标注高频词,再用规则处理兼类词(如“教育”在“教育事业”中为名词,在“教育孩子”中为动词)。
基于神经网络的方法
BiLSTM-CRF模型:
- 输入:字或词向量。
- 输出:BIOES标签序列(如
B-N、I-V、E-A)。
预训练模型(如BERT):微调BERT的Token分类头,直接预测词性标签。
有限状态自动机(FSA)
- 应用场景:处理形态丰富的语言(如英语动词变位)。
-
例子:构建FSA规则:
run + -ing → running(动词→现在分词)。
分词与词性标注结果评价方法
两种测试
- 封闭测试 / 开放测试
- 专项测试 / 总体测试
评价指标
- 正确率(Correct ratio/Precision, P ): 测试结果中正确切分或标注的个数占系统所有输出结果的比例。假设系统输出N 个,其中,正确的结果为n个,那么,
- 召回率(找回率) (Recall ratio, R ): 测试结果中正确结果的个数占标准答案总数的比例。假设系统输出N个结果,其中,正确的结果为n个,而标准答案的个数为M个,那么,
- F-测度值(F-Measure): 正确率与找回率的综合值。计算公式为:
, 一般的,取
=1,

词汇分析实验(jieba库)
实验目的:
- 掌握中文分词方法;
- 掌握常用分词工具的使用;
实验要求:
- 使用任意分词方法编写算法实现汉语自动分词程序
- 编写直接调用分词工具(jieba分词,中科院分词等)进行分词的程序
- 分别计算出两种分词结果的正确率,给出计算依据
设计思路:
对于要求1,本文实现的是“最少分词(最短路径)法”。
首先设置词典,本文使用jieba内置词典“jieba.dt.FREQ.keys()”,将待分语句、词典、最长单词长度作为下一步的参数。实验用的待分语句截取自SIGHAN 2005-PKU简体中文分词数据集,约1500字长。
(点击数据集链接)
其次,分词函数将待分语句转换为有向图结构。具体实现分为三步:(1)初始化有向图并添加节点-字符位置;(2)通过双重循环遍历所有可能的词语组合,将词典中存在的作为边添加到图中,边的权重与词长成反比以优先选择更长的匹配;(3)使用Dijkstra算法寻找从起点到终点的最短路径,若图不连通则回退到单字切分。最长词长参数可以控制计算复杂度。下左图展示了一部分路径序列、右图展示了一部分分词结果。
对于要求2,直接使用“jieba.cut()”函数,设置精确模式“cut_all=False”。
经了解,jieba库分词的主要可理解为“规则与统计相结合的分词方法”,融合了“基于前缀词典的词图结构 + 动态规划 + HMM 隐马尔可夫模型 + 自定义词典”。首先根据前缀词典(词典中有哪些词),扫描句子构建一个“所有可能切词的位置”构成的词图;然后每条路径会根据词频概率(从词典统计来的 log(P(w)))计算总得分,DP选择得分最高的路径,即“最可能的分词组合”。jieba 内部同时训练了一个基于人民日报语料的 HMM 分词模型,用来识别未登录词进行字标注,使用4个状态标注:B(词头)、M(中间)、E(结尾)、S(单独词)。
对于要求3,使用“词边界匹配”的方式判断是否相同。将自动分词结果与人工标注的正确分词结果分别转换成“词边界索引对”。两个边界完全相同的词,才算一个“正确分词”。
主要用到三种评估指标:精确率(Precision)、召回率(Recall)和 F1 值。
实验分析:
本文同时简单的对比分析了两种分词方法与人工标注约15%的错误率的原因。错误的主要出处是(1)“阿拉伯数字组合成的数词”(如“1998”)、(2)“量词+名词”(如“一年”)和(3)“人名”。在PKU人工标注中,(1)都是一个词,而所选取的词典中只有单个的阿拉伯数字;在PKU人工标注中,(2)都被分开了,而所选取的词典中都是一个词;在PKU人工标注中,(3)都是“姓”与“名”分开的,而所选取的词典中都是一个词。这也体现了标注标准统一和质量的重要性。
代码附录:
import jieba
import networkx as nx
# === 读取人工分词标注的文本 ===
def read_annotated_sentence(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
annotated_line = f.read()
words = annotated_line.split() # 按空格分词
raw_sentence = ''.join(words) # 去掉空格得到原始句子
return raw_sentence, words
# === 生成词边界集合 ===
def get_word_boundaries(words):
boundaries = set()
start = 0
for word in words:
end = start + len(word)
boundaries.add((start, end))
start = end
return boundaries
# === 计算评估指标 ===
def evaluate(pred_words, gold_words):
pred_set = get_word_boundaries(pred_words)
gold_set = get_word_boundaries(gold_words)
correct = len(pred_set & gold_set)
precision = correct / len(pred_set) if pred_set else 0
recall = correct / len(gold_set) if gold_set else 0
f1 = 2 * precision * recall / (precision + recall) if (precision + recall) else 0
return precision, recall, f1
# === 词图 + 最短路径分词算法 ===
def shortest_path_seg(sentence, word_dict, max_word_len=5):
graph = nx.DiGraph()
n = len(sentence)
graph.add_nodes_from(range(n + 1))
# 构建图中边(表示词)
for i in range(n):
for j in range(i + 1, min(i + max_word_len, n) + 1):
seg = sentence[i:j]
if seg in word_dict:
# print(f"词图边:{i}->{j}:'{seg}'")
graph.add_edge(i, j, word=seg, weight=1 / (j - i))
# 若无法分出路径(比如图断了),返回单字分词
try:
path = nx.shortest_path(graph, 0, n, weight='weight')
print("\n=== 最短路径词语序列 ===")
for i in range(len(path) - 1):
edge = graph.edges[path[i], path[i+1]]
print(f"{path[i]}->{path[i+1]}:'{edge['word']}'(len={path[i+1]-path[i]})")
words = [graph.edges[path[i], path[i+1]]['word'] for i in range(len(path)-1)]
except nx.NetworkXNoPath:
print("图不连通,使用单字切分")
# 查找能从0出发走到的所有节点
reachable = nx.descendants(graph, 0)
reachable.add(0) # 自己能到自己
print(f"当前图中,从起点0能到达的节点数: {len(reachable)} / {n + 1}")
# 找出第一个无法到达的点
for i in range(n + 1):
if i not in reachable:
print(f"图从 0 无法到达位置 {i}(对应字符:'{sentence[i-1] if i > 0 else ''}')")
break
words = list(sentence)
return words
if __name__ == "__main__":
file_path = "pku_training.txt"
# 读取数据
raw_sentence, gold_words = read_annotated_sentence(file_path)
print("原始句子:", raw_sentence)
print("人工分词:", gold_words)
# jieba分词
jieba_pred_words = list(jieba.cut(raw_sentence, cut_all=False))
print("jieba分词:", jieba_pred_words)
jieba_precision, jieba_recall, jieba_f1 = evaluate(jieba_pred_words, gold_words)
print(f"\n[jieba评估结果]")
print(f"Precision: {jieba_precision:.4f}")
print(f"Recall: {jieba_recall:.4f}")
print(f"F1 Score: {jieba_f1:.4f}")
# 最短路径分词
jieba.initialize() # 强制加载默认词典
word_dict = set(jieba.dt.FREQ.keys()) # 使用jieba内置词典
punctuations = set(",。、:;!?“”‘’()《》【】—…-·")
word_dict.update(punctuations)
digits = set("0 1 2 3 4 5 6 7 8 9 1 2 9 8 7")
word_dict.update(digits)
# print(list(word_dict)[:20])
shortest_pred_words = shortest_path_seg(raw_sentence, word_dict)
print("\n最短路径分词:", shortest_pred_words)
sp_precision, sp_recall, sp_f1 = evaluate(shortest_pred_words, gold_words)
print(f"\n[最短路径分词评估结果]")
print(f"Precision: {sp_precision:.4f}")
print(f"Recall: {sp_recall:.4f}")
print(f"F1 Score: {sp_f1:.4f}")
# 保存jieba分词结果
with open("jieba_output.txt", "w", encoding="utf-8") as f:
f.write(" /".join(jieba_pred_words))
print("\njieba分词结果已保存至 jieba_output.txt")
# 保存最短路径分词结果
with open("shortest_path_output.txt", "w", encoding="utf-8") as f:
f.write(" /".join(shortest_pred_words))
print("最短路径分词结果已保存至 shortest_path_output.txt")总结
自然语言处理中的词法分析与词性标注是NLP的基础任务,其中词法分析包括英语的形态还原(处理规则/不规则变化、特殊形式和合成词)和中文分词(解决歧义切分和未登录词识别),主要采用最大匹配法、最短路径法和统计语言模型等方法;词性标注则针对词性兼类问题,结合规则(如词缀和上下文规则)、统计模型(HMM、ME)和深度学习方法(BiLSTM-CRF、BERT),并依赖标准标注集(如北大和Penn Treebank),其性能通过正确率、召回率和F值评估,这些技术为上层NLP应用提供了基础支撑。

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









