







 参考代码:CREStereo1. 概述介绍:双目立体匹配在像Middlebury数据上已经取得了不错的效果,但是将训练得到的匹配模型应用到实际场景下时输出效果会出现较大退化。这是因为实际运用场景情况会更加复杂,比如纤细物体的视差估计、图像矫正不够理想、双目相机的模型一致性存在问题以及多样的困难场景。这篇文章对于实际场景中存在的问题提出了一种合成数据、真实数据联合训练的多层次迭代优化双目视差估计算法加以解决,文章的主要贡献点可以总结为如下几点:网络结构上:提出AGCL(Adaptive Group
参考代码:CREStereo1. 概述介绍:双目立体匹配在像Middlebury数据上已经取得了不错的效果,但是将训练得到的匹配模型应用到实际场景下时输出效果会出现较大退化。这是因为实际运用场景情况会更加复杂,比如纤细物体的视差估计、图像矫正不够理想、双目相机的模型一致性存在问题以及多样的困难场景。这篇文章对于实际场景中存在的问题提出了一种合成数据、真实数据联合训练的多层次迭代优化双目视差估计算法加以解决,文章的主要贡献点可以总结为如下几点:网络结构上:提出AGCL(Adaptive Group
参考代码:CREStereo
1. 概述
介绍:双目立体匹配在像Middlebury数据上已经取得了不错的效果,但是将训练得到的匹配模型应用到实际场景下时输出效果会出现较大退化。这是因为实际运用场景情况会更加复杂,比如纤细物体的视差估计、图像矫正不够理想、双目相机的模型一致性存在问题以及多样的困难场景。这篇文章对于实际场景中存在的问题提出了一种合成数据、真实数据联合训练的多层次迭代优化双目视差估计算法加以解决,文章的主要贡献点可以总结为如下几点:
- 网络结构上:提出AGCL(Adaptive Group Correlation Layer),首先使用channel-group局部窗口计算local feature attention,之后在视差图解码预测的不同阶段上交替使用2D和1D的kernel实现局部搜索,此外通过学习的形式感知kernel的偏移offset实现更精准地搜索匹配;
- 参考RAFT中迭代优化的策略,这里文章也采用这种coarse-to-fine的迭代优化形式。除此,还可以通过在infer阶段建立图像金字塔实现级联优化,从而得到更准确的视差估计;
- 在现有合成数据集的基础上使用Blender针对复杂场景(如纤细物体、新的视差分布、图像光照变化等)进行仿真数据合成(数据量为20w),作为现有公开数据集数据的补充;
将文章代码中的eth3d上训练得到的模型实际进行测试也展示了其较好的泛化能力。下面是文章给出的该方法的一些效果图:

2. 方法设计
2.1 网络结构
文章设计的网络在训练和测试阶段其pipeline如下图所示:
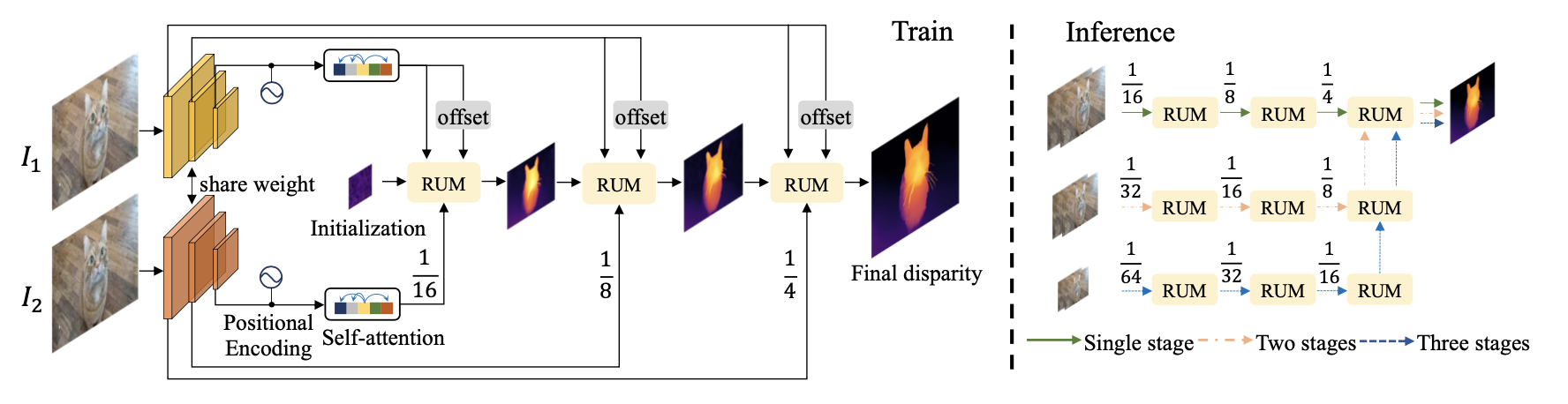
- 1)在训练中:首先通过一系列的attention和2D、1Dcorrelation操作refine特征,并级联优化输出视差估计结果,对应上图左边分别在 s t r i d e = { 1 16 , 1 8 , 1 4 } stride=\{\frac{1}{16},\frac{1}{8},\frac{1}{4}\} stride={ 161,81,41}处得到视差估计残差 Δ d i s p a r i t y \Delta_{disparity} Δdisparity;
- 2)在测试中:按照需求的不同会通过采样操作得到图像金字塔,然后将低分辨率的预测输出结果作为高分辨率的初始输入,从而达到级联优化的目的;
2.2 AGCL
实际场景下使用的双目系统可能会存在如极线未对齐、双目相机参数存在偏差等因素,从而导致与双目立体匹配的先验假设不符,自然导致实际运用存在限制。对此文章提出了AGCL(Adaptive Group Correlation Layer)模块去实现双目图像的特征关联。对于这个模块其结构为:
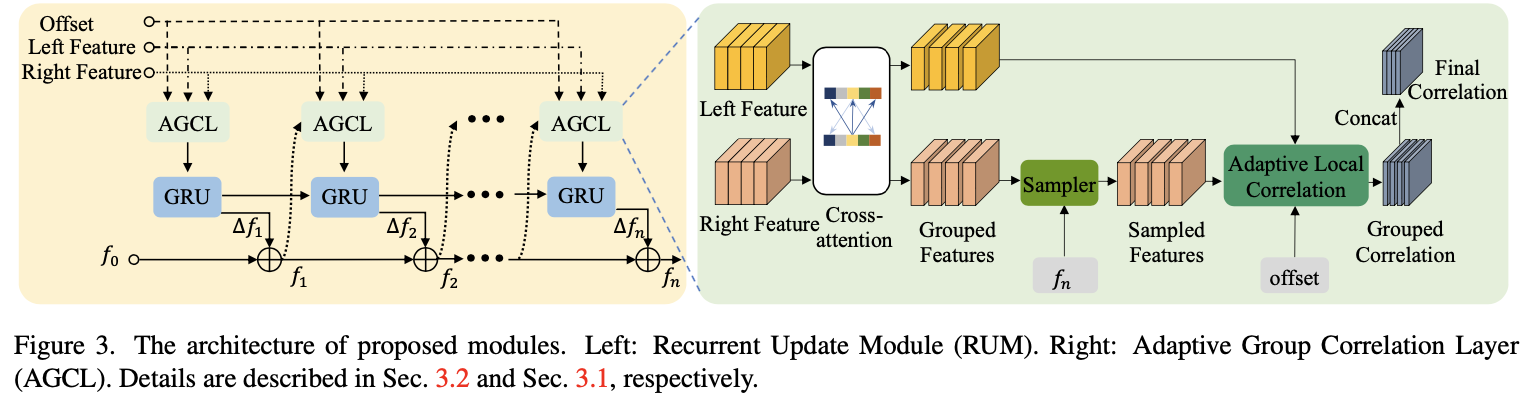
结合文章内容解码器部分主要包含这几个部分:基于channel-group局部特征attention模块(也就是文中的Local Feature Attention)、2D和1D维度的局部交替搜索模块。这里涉及到的模块多是采用分组的形式进行的,这样做的好处便是能够减少部分运算量。
channel-group局部特征attention:
这部分实现参考的是LoFTR论文中对与特征相关性的计算,并采用channel分组和位置编码的形式加速运算和优化特征表达。对于位置编码部分使用的是sin和cos进行编码,对于这部分可以参考:
# nets/attention/position_encoding.py#L6
class PositionEncodingSine(M.Module):
...
PS:这里的实现在其实是存在一些问题的,具体可以参考仓库的issue。
对于特征添加了位置编码之后便是计算特征之间相关性用于增强特征表达了,其核心代码为:
# nets/attention/linear_attention.py#L25
# [B, L, 8, 32, 1]*[B, L, 8, 1, 32]->[B,L,8,32,32]->[B,8,32,32]
KV = F.sum(F.expand_dims(K, -1 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









