









参考代码:暂无
动机与出发点
在MapTR算法中对于地面元素的回归是直接采用回归的方式,但是这样回归的方式并不能很好反应地面元素的形态,也就是缺少全局观。这里对于局部的理解可以看作是地面元素中的点(文中描述为points-level),全局的理解可以看作是地面元素整体(通常理解为实例,文中描述为elements-level)。完全基于points-level的方式在之前一些方法中已经被证明效果不是很好,根本原因是对实例拟合能力不行(任务本身也难),表现形式是预测的点与实际的物体之间偏差比较大,对于车道线来讲就是横向误差、车道平行度无法保证。对应下图中第1格子的图。
对于回归任务较难的问题,自然想法就是引入其它信息,其实实例的几何信息也是很重要的,这个几何信息直观表现就是mask信息,而mask预测是一个分类任务天然就比回归任务容易学习。然而由分割任务基础上去预测points的回归也是很难的(没有很好学习point-level的信息),就如下面图中第2、3格子的图。

那么自然将mask和points结合的方式便能取长补短,使得地面元素输出的结果更加稳定。为了实现这个想法文章的将query构建方式进行修改,变为points-query+elements-query的组合(hybird query),在中间还增加两者信息的交互,还通过关联矩阵去强化points和query之间一致性,这样就极大提升了整体感知的稳定性了,也就是上图中第4格子的图。
方法设计
整体pipeline见下图所示:
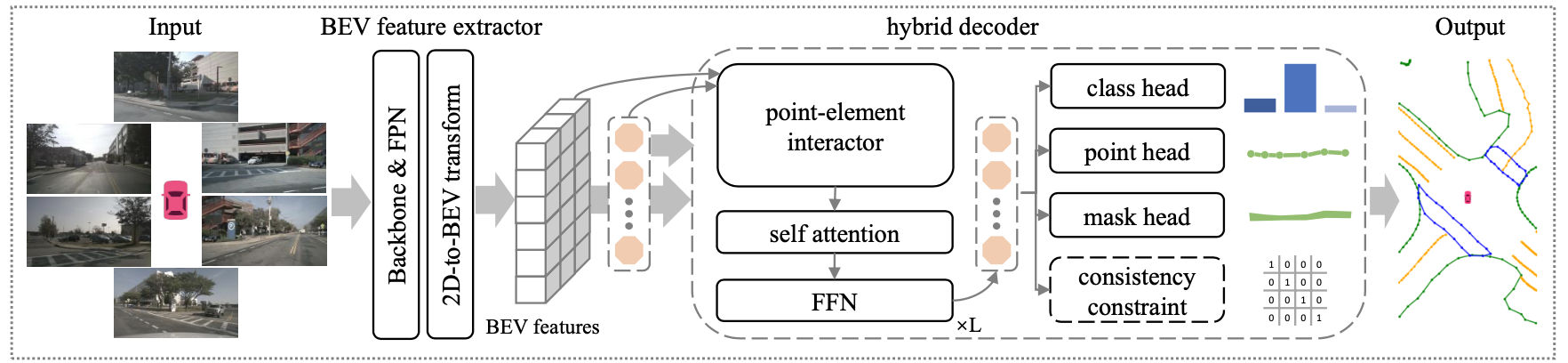
可以看到文章的改进点主要在transformer layer结构(query设置、信息流交互)和预测结果上,添加了实例mask和一致性约束(elements&points之间,infer的时候去掉)。
hybrid query设置
hybird query其实是包含两个维度信息的,其中points-level维度的query描述为
Q
i
p
∈
R
N
∗
P
∗
C
Q_i^p\in R^{N*P*C}
Qip∈RN∗P∗C,对应elements-level的query描述为
Q
i
e
∈
R
N
∗
C
Q_i^e\in R^{N*C}
Qie∈RN∗C,那么hybird query就是两者的组合
Q
i
h
∈
R
N
∗
(
P
+
1
)
∗
C
Q_i^h\in R^{N*(P+1)*C}
Qih∈RN∗(P+1)∗C。然后这俩个query会首先分别与BEV特征(
X
∈
R
H
∗
W
∗
C
X\in R^{H*W*C}
X∈RH∗W∗C)做cross-attn去更新自身,之后做points-level和elements-level信息的融合,整体流程见下图所示。

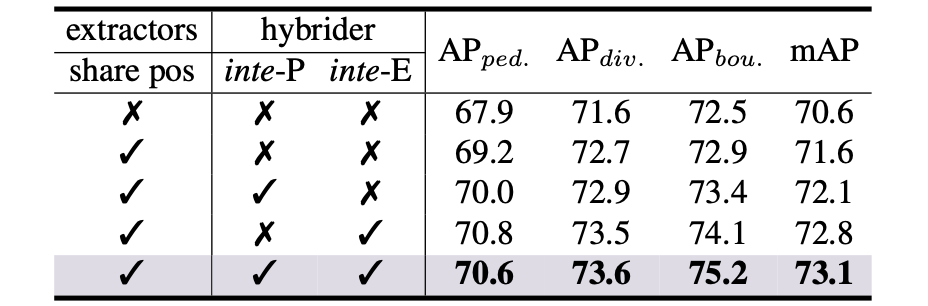
query中位置编码是否共享和两种query设置对性能带来的影响:
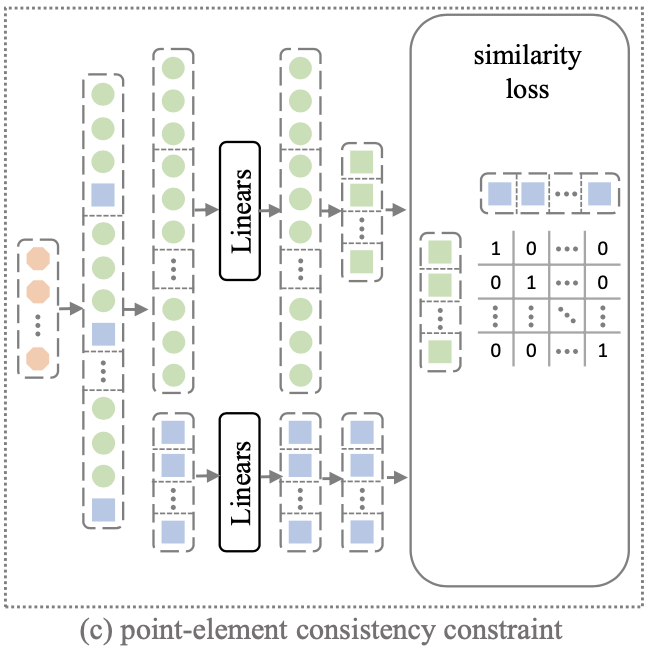
hybird query中的信息交互
在信息交互的流程中是由如下几个步骤的:
- 1)points-level特征更新:points query在与BEV特征做交互过程中使用到points的位置(静态元素位置)信息作为query_pos,然后使用类似deformable attn的方式与BEV特征交互(cross-attn)做更新,这一点问题不大
- 2)elements-level特征更新:elements query可以使用nn.embedding的方式初始化,但是它的pos信息如何来呢?这里直接使用了point-level中的位置信息,只不过这个位置信息会经过一个加权求和过程与elements-level所需的pos对齐,也就是维度变换关系为 R N ∗ P ∗ C → R N ∗ C R^{N*P*C}\rightarrow R^{N*C} RN∗P∗C→RN∗C。除此之外还引入前一层的mask预测结果作为mask来屏蔽掉不相关的区域,也就是对softmax之后的权重乘上前一层mask M i l − 1 ∈ { 0 , 1 } H W M_i^{l-1}\in\{0,1\}^{HW} Mil−1∈{0,1}HW(阈值设置为0.5),这样在添加pos和mask信息之后与BEV特征做交互(cross-attn)
- 3)points-level和elements-level特征交互:在进行交互之前各自的特征可以走一遍self-attn+FFN的流程来优化各自的特征表达。对于所说的融合,其实就是一句话各自维度匹配之后相加,前面points-level向elements-level通过加权求和实现了维度匹配,那么elements-level向points-level维度匹配的话就是unsqueeze()和broadcast实现了
points和elements之间的一致性约束
对于points-level和elements-level的query信息首先经过全连接层做隔离,然后points-level信息按照之前的套路得到维度压缩后的结果
Q
ˉ
i
p
,
l
∈
R
N
∗
C
\bar{Q}_i^{p,l}\in R^{N*C}
Qˉip,l∈RN∗C,那么再与原本的elements-level下的query做矩阵乘法消掉emb-dim维度,得到关联矩阵(单位阵)
A
e
,
l
∈
R
N
∗
N
A^{e,l}\in R^{N*N}
Ae,l∈RN∗N,然后用二值交叉墒损失函数去约束它,也就是建立它们的一致性约束
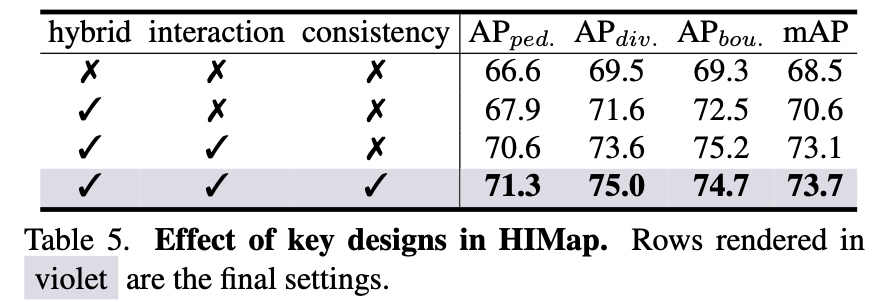
三个维度上的消融实验:上面提到的hybrid query、不同level之间是否交互、一致性约束对性能的影响:
实验结果
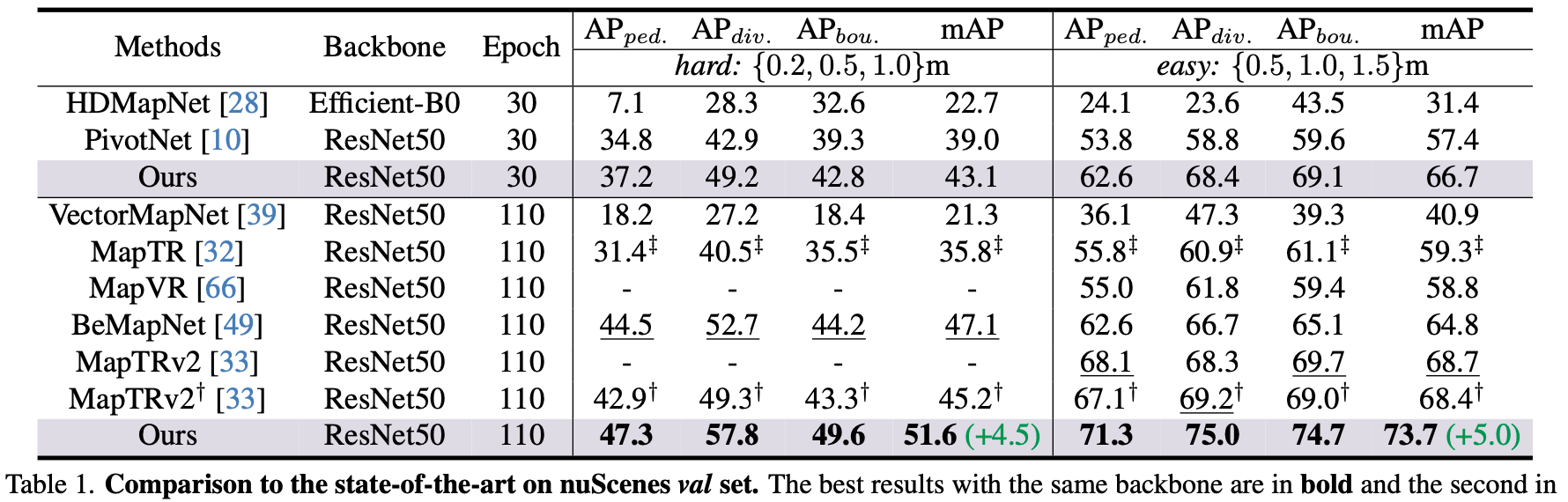
nuscnes val下的性能比较:
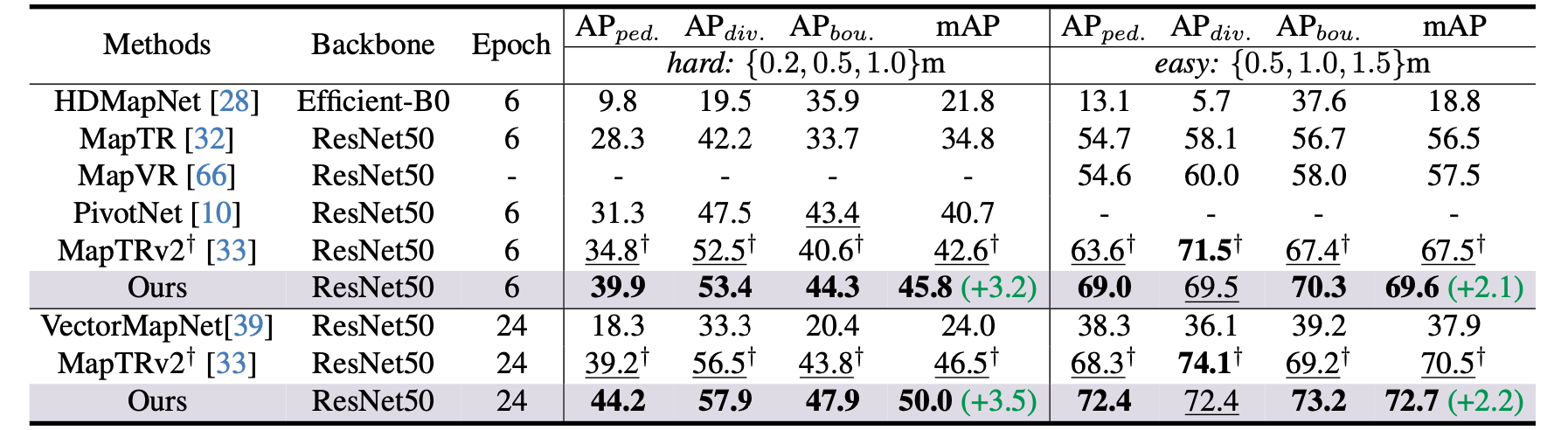
Argoverse2 val下的性能比较:















 57
57











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









