







损失函数介绍
在深度学习中,损失函数(Loss Function)是用来衡量模型预测结果与真实标签之间的差异或误差的函数。通过最小化损失函数,可以使模型在训练过程中逐渐优化参数,提高模型的预测准确性。
以下是深度学习中常用的损失函数及其简要介绍:
1.均方误差损失函数(Mean Squared Error, MSE):
- MSE损失函数是用来评估模型预测值与真实值之间的平均平方差。适用于回归问题,通常用于连续数值的预测任务。
2.交叉熵损失函数(Cross Entropy Loss):
- 交叉熵损失函数常用于分类问题,特别是多类别分类。它衡量了模型输出的概率分布与真实标签的差异,通过最小化交叉熵损失可以提高分类模型的准确性。
3.对数损失函数(Log Loss):
- 对数损失函数也常用于二分类或多分类问题,特别是在逻辑回归或softmax分类器中。它衡量了模型输出的概率与真实标签之间的差异。
4.Hinge损失函数:
- Hinge损失函数通常用于支持向量机(SVM)中,特别是在二分类问题中。它可以帮助模型找到最大间隔分类超平面。
5.Huber损失函数:
- Huber损失函数是一种平滑的损失函数,可以降低对异常值的敏感度。适用于回归问题,结合了均方误差和绝对误差。
6.Dice损失函数:
- Dice损失函数常用于图像分割任务中,用于衡量模型生成的分割结果与真实分割之间的重叠程度。
以上是深度学习中常用的损失函数,不同的任务和模型可能适合不同的损失函数,选择合适的损失函数对模型的训练和性能影响很大。在实际应用中,根据具体的问题和数据特点选择适合的损失函数是很重要的。
yolov8损失函数介绍
YOLOv8官方将各类任务(目标检测,关键点检测,实例分割,旋转目标框检测,图像分类)的损失函数封装了在ultralytics\utils\loss.py中,本文主要梳理一下目标检测任务Loss的大致组成,不涉及到具体的原理。
Loss 计算包括 2 个分支:分类和回归分支,没有了之前的 objectness 分支。
目标检测任务中函数定义在class v8DetectionLoss中,代码如下所示:
class v8DetectionLoss:"""Criterion class for computing training losses."""def __init__(self, model): # model must be de-paralleled"""Initializes v8DetectionLoss with the model, defining model-related properties and BCE loss function."""device = next(model.parameters()).device # get model deviceh = model.args # hyperparametersm = model.model[-1] # Detect() moduleself.bce = nn.BCEWithLogitsLoss(reduction='none')self.hyp = hself.stride = m.stride # model stridesself.nc = m.nc # number of classesself.no = m.noself.reg_max = m.reg_maxself.device = deviceself.use_dfl = m.reg_max > 1self.assigner = TaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)def preprocess(self, targets, batch_size, scale_tensor):"""Preprocesses the target counts and matches with the input batch size to output a tensor."""if targets.shape[0] == 0:out = torch.zeros(batch_size, 0, 5, device=self.device)else:i = targets[:, 0] # image index_, counts = i.unique(return_counts=True)counts = counts.to(dtype=torch.int32)out = torch.zeros(batch_size, counts.max(), 5, device=self.device)for j in range(batch_size):matches = i == jn = matches.sum()if n:out[j, :n] = targets[matches, 1:]out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))return outdef bbox_decode(self, anchor_points, pred_dist):"""Decode predicted object bounding box coordinates from anchor points and distribution."""if self.use_dfl:b, a, c = pred_dist.shape # batch, anchors, channelspred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)return dist2bbox(pred_dist, anchor_points, xywh=False)def __call__(self, preds, batch):"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""loss = torch.zeros(3, device=self.device) # box, cls, dflfeats = preds[1] if isinstance(preds, tuple) else predspred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split((self.reg_max * 4, self.nc), 1)pred_scores = pred_scores.permute(0, 2, 1).contiguous()pred_distri = pred_distri.permute(0, 2, 1).contiguous()dtype = pred_scores.dtypebatch_size = pred_scores.shape[0]imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)# Targetstargets = torch.cat((batch['batch_idx'].view(-1, 1), batch['cls'].view(-1, 1), batch['bboxes']), 1)targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxymask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)# Pboxespred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)_, target_bboxes, target_scores, fg_mask, _ = self.assigner(pred_scores.detach().sigmoid(), (pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor, gt_labels, gt_bboxes, mask_gt)target_scores_sum = max(target_scores.sum(), 1)# Cls loss# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL wayloss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE# Bbox lossif fg_mask.sum():target_bboxes /= stride_tensorloss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,target_scores_sum, fg_mask)loss[0] *= self.hyp.box # box gainloss[1] *= self.hyp.cls # cls gainloss[2] *= self.hyp.dfl # dfl gainreturn loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
YOLOv8损失函数使用了分类BCE、回归CIOU + VFL(新增项目)的组合。
分类损失
YOLOv8用的多分类损失是N个目标的二元交叉熵损失,而不是一般我们认为的多目标的softmax交叉熵损失。这里的BECWithLogitsLoss=BCELoss(二元交叉熵)+Sigmoid(激活函数)
self.bce = nn.BCEWithLogitsLoss(reduction='none')这里的分类损失是把N个目标的二元交叉熵损失求和,再取平均
#分类损失loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum
边界框回归损失
YOLOv8用的矩形框损失主要由iou loss和DFL loss组成。
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)# 边界框回归损失if fg_mask.sum():target_bboxes /= stride_tensorloss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores,target_scores_sum, fg_mask)
iou损失
iou loss有CIoU,DIoU,GIoU 三种loss可选择。在ultralytics\utils\metrics.py中可查看,定义在下面的代码中:
iou = inter / unionif CIoU or DIoU or GIoU:cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) widthch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex heightif CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squaredrho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)with torch.no_grad():alpha = v / (v - iou + (1 + eps))return iou - (rho2 / c2 + v * alpha) # CIoUreturn iou - rho2 / c2 # DIoUc_area = cw * ch + eps # convex areareturn iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdfreturn iou # IoU
DFL损失
论文:https://ieeexplore.ieee.org/document/9792391
Distribution Focal Loss (DFL) 是在 Generalized Focal Loss(GLF)中提出,用来让网络快速聚焦到标签附近的数值,使标签处的概率密度尽量大。思想是使用交叉熵函数,来优化标签y附近左右两个位置的概率,使网络分布聚焦到标签值附近。
在ultralytics\utils\loss.py中可查看,定义在下面代码中:
#target左右两侧之和@staticmethoddef _df_loss(pred_dist, target):"""Return sum of left and right DFL losses."""# Distribution Focal Loss (DFL) proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391tl = target.long() # target lefttr = tl + 1 # target rightwl = tr - target # weight leftwr = 1 - wl # weight rightreturn (F.cross_entropy(pred_dist, tl.view(-1), reduction='none').view(tl.shape) * wl +F.cross_entropy(pred_dist, tr.view(-1), reduction='none').view(tl.shape) * wr).mean(-1, keepdim=True)
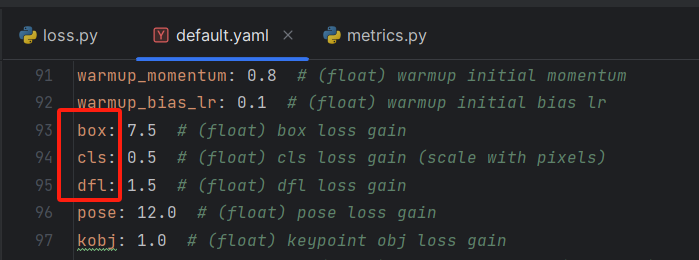
损失加权
loss[0] *= self.hyp.box # box gain 7.5loss[1] *= self.hyp.cls # cls gain 0.5loss[2] *= self.hyp.dfl # dfl gain 1.5return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
损失函数的意义
在YOLOv8中,常用的损失函数是组合了多个部分的综合损失函数,包括目标检测损失、目标分类损失和目标定位损失。这些损失函数的意义如下:
1.目标检测损失:
- 目标检测损失用来衡量模型对目标是否存在的预测结果与真实标签之间的差异,通常使用二分类损失函数(如交叉熵损失)来计算。该损失函数帮助模型确定图像中是否存在目标物体。
2.目标分类损失:
- 目标分类损失用来衡量模型对目标类别的预测结果与真实标签之间的差异,通常使用交叉熵损失函数来计算。该损失函数帮助模型对检测到的目标进行分类。
3.目标定位损失:
- 目标定位损失用来衡量模型对目标位置的预测结果与真实标签之间的差异,通常使用均方误差损失函数来计算。该损失函数帮助模型准确定位目标的位置。
综合以上损失函数,YOLOv8的综合损失函数通常是以上三种损失函数的加权和,通过最小化综合损失函数,可以使模型在训练过程中逐渐优化参数,提高目标检测的准确性和稳定性


















 3739
3739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











