








若您对大模型的名称后缀比如7b/-instruct…还不太明确,推荐您先阅读LLM模型名称解读
大模型显存需求计算
这里推荐一个在线的"大模型显存计算器",可以准确计算选用的模型在不同使用场景下的显存需求。
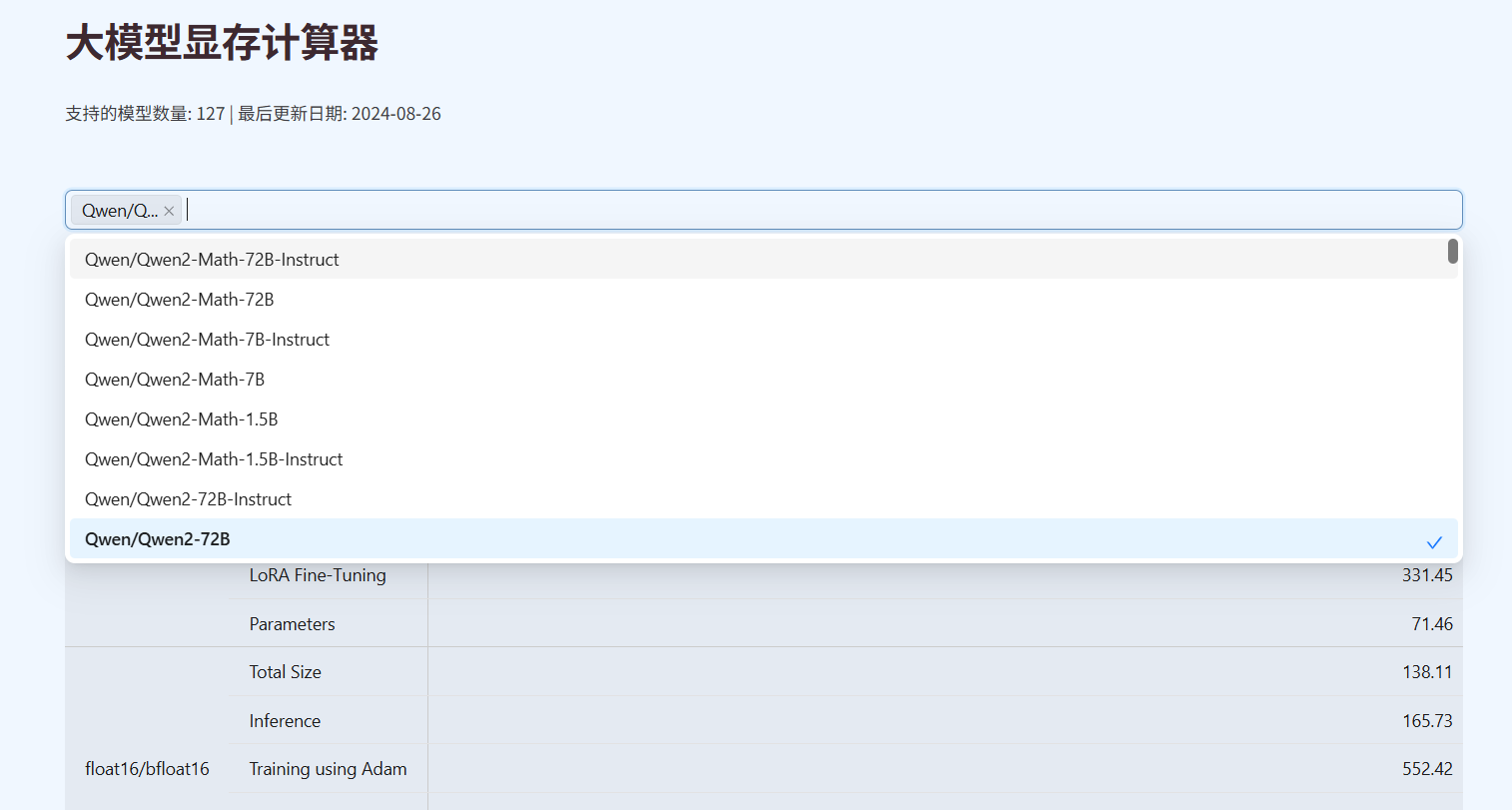
对于一个大模型来说,显存需求主要分为三种情况:
- 推理(Inference)时的显存需求:模型用于生成回答时需要的显存
- 全参数微调(Fine-tuning)时的显存需求:对模型所有参数进行调整时需要的显存,很少用一般不关注
- 部分参数微调(LORA等)时的显存需求:只更新部分参数时需要的显存
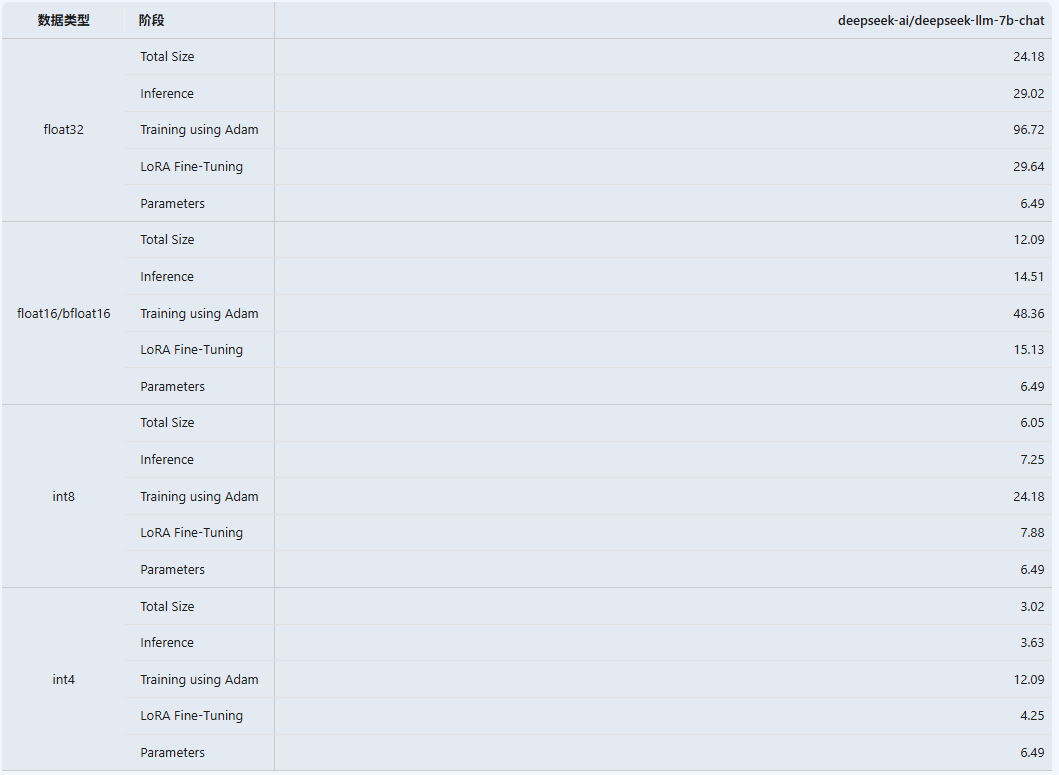
以DeepSeek 7B模型(70亿参数)为例如下图,在FP16精度(每个参数占用16位或2个字节)下:
- 推理时需要约14.5GB显存
- 全参数微调时需要约48GB显存
- 部分参数微调时需要约15GB显存
综上我们如果选用deepseek7b大约需要14~15G显存。
📋另外有个小技巧,内存需求经验法则:拥有X B参数的模型通常需要约2X GB的显存。比如这里的7B一般就是占用7*2G显存。
这些相对于原来模型小的模型不是从零开始训练的,而是通过对更大模型进行优化和降维得到的。这些模型是通过知识蒸馏、量化等技术从更大的预训练模型中"压缩"得到的。
大模型显存需求计算方法
对于大模型的显存需求,我们可以用一个简单的经验法则来估算:拥有X B参数的模型在FP16(半精度)格式下通常需要约2X GB的显存进行推理。例如:
- 0.5B参数模型在FP16下需要约1GB显存
- 7B参数模型在FP16下需要约14GB显存
- 70B参数模型在FP16下需要约140GB显存
当然,这只是基本的参数存储需求,实际运行时还需要考虑额外的缓存、激活值和其他临时变量的存储空间。这就是为什么即使是7B模型,在推理时实际也常常需要15GB以上的显存。
利用量化技术(如4-bit量化),可以进一步降低显存需求,使更大的模型能够在普通硬件上运行。例如,一个7B模型经过4-bit量化后,理论上只需要约4GB的显存就能进行推理。
这种通过蒸馏和量化得到的小型模型,虽然与原始大模型相比有一定的性能损失,但在许多场景下仍然能够提供令人满意的结果,同时大大降低了硬件要求,使AI技术更加平民化,这也是目前大模型发展的一个重要方向。
如何选择合适的模型规模
根据你的硬件条件选择合适的模型规模是非常重要的。一般推荐选择占用机器显存的2/3内。例如:
- 如果你使用的是RTX 4090显卡(24GB显存),可以轻松部署7B级别的模型进行推理或部分参数微调
- 如果你拥有两张RTX 4090(总共48GB显存),甚至可以进行7B模型的全参数微调
对于更大规模的模型,如DeepSeek 67B模型,推理时需要约148GB的显存。如果是满血版的DeepSeek 671B,显存需求将是前者的十倍,高达1480GB!这就需要多张高端GPU,比如10-15张NVIDIA H200(每张96GB显存)才能满足需求。


















 3648
3648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











