










目录
2.2、Dynamic Head: Unifying with Attentions
1、动机
在目标检测方法中,由于分类和定位组合的复杂性,产生了多种多样的算法。这些算法尝试在检测heads上提升性能,不过它们缺乏一种统一的视角来看待检测问题。基于此,本文提出了一个新颖的动态head框架,将注意力机制与目标检测Heads统一起来。
2、方法
2.1、整体描述
整体而言,该动态head框架的self-attention体现在三个方面:
- 在特征层级之间做尺度感知;
- 在空间位置之间做空间感知;
- 在输出通道之间做任务感知;
而传统目标检测head通常只解决上述之一。
在本文的动态head框架中,将backbone的输出,也即head部分的输入,视为一个三维的tensor: level × space ×channel,其中:level是特征层级、space是feature map的宽高乘积(HW)、channel是通道数。也即:四维形式的或者三维形式的
。
一种直觉上的解决方案是:对上述三维tensor进行直接的attention。不过,这种方式优化难度大,且计算量非常庞大。于是,作者提出了一种分离式的注意力机制,对feature map中每个独立的维度分别进行attention,分别描述如下:
- scale-aware attention(level-wise):尺度感知注意力,在level维度上执行,不同level的feature map对应了不同的目标尺度,在level层级增加注意力,可以增强目标检测的尺度感知能力;
- spatial-aware attention (spatial-wise):空间感知注意力,在spatial维度上执行,不同的空间位置对应了目标的几何变换,在spatial维度上增加注意力,可以增强目标检测器的空间位置感知能力;
- task-aware attention(channel-wise):任务感知注意力,在channel维度上执行,不同的通道对应了不同的任务,在channel维度上增加注意力,可以增强目标检测对不同任务的感知能力。
本文的主要贡献,就是将上述三种注意力统一到一个高效注意力学习问题中。
2.2、Dynamic Head: Unifying with Attentions
对于给定的特征tensor,其广义注意力可以描述为:
(1)
针对这种注意力,一种朴素的方法是直接使用全连接层,不过这样一来,计算量就急剧飙升,这种高维计算是不切实际的。
因此,作者将上述注意力形式进行了转换,变为三个序列化的注意力,每个注意力仅关注一个维度:
(2)
其中,分别表示L,S,C三个维度上的注意力。
Scale-aware Attention :尺度感知注意力模块,基于其语义重要性对不同尺度的特征进行融合:
(3)
其中,f(·)为线性函数,使用1*1卷积近似,为hard-sigmoid函数。
Spatial-aware Attention :空间感知注意力模块,聚焦于不同空间位置的判别能力;考虑到S的高纬度,需要对该模块进行解耦,分为两个步骤:首先使用可变性卷积学习稀疏化,然后在同一空间位置上夸level聚合特征:
(4)
其中,K为稀疏采样的位置数量,做了位置偏移以聚焦于有判别力的区域,
是一个关于位置
的可自学习的重要性度量因子。这些都是可以通过F中间层级的输入特征学习到的。
Task-aware Attention :为了能够进行联合学习与目标表示的泛化性,设计了一种任务感知注意力模块,其动态地开/关特征通道来选择不同的任务:
(5)
其中,是超函数,用于学习控制激活阈值;
的用法类似于Dynamic relu,首先在L × S的维度上执行全局池化,然后使用两个全连接层、一个归一化层,并最终使用shifted sigmoid函数归一化输出。
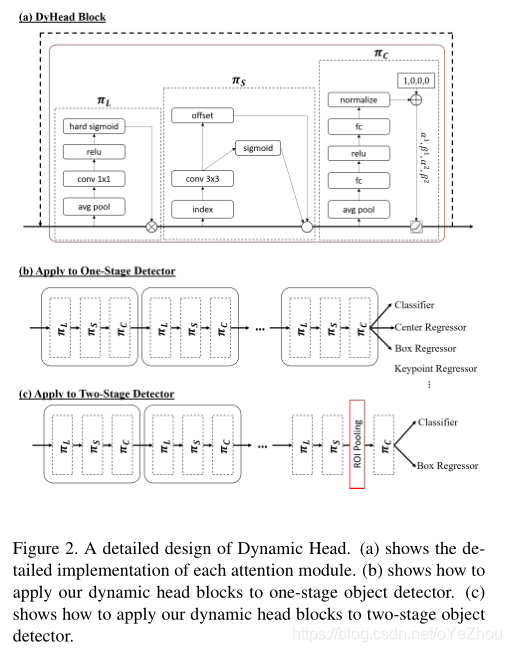
上面几种注意力方法,可以按照公式(2)的方式序列化堆叠多次。网络细节,见图2(a):
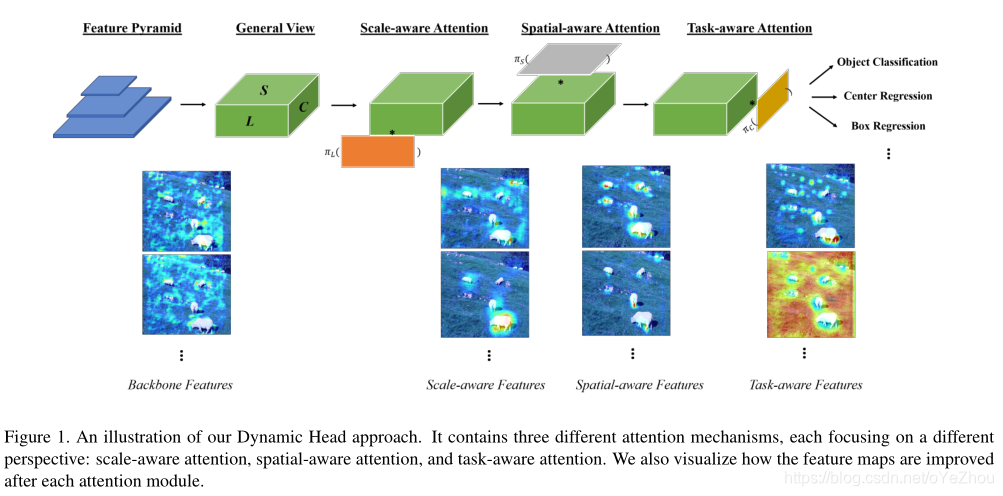
而整体的网络结构示意,如图1所示:首先,任何类型的backbone网络都可以用于提取特征金字塔,并进一步resize到相同尺度的3维tensor——,然后作为动态头的输入;接着,几个包含了尺度感知、空间感知、任务感知的DyHead块堆叠起来;最后,DyHead的输出可以用于不同的任务,如分类、中心/边框回归等。
图1的底部展示了每种注意力模块的输出,可以看出:
- 从backbone得到的初始feature map有很多噪声,这是由于从ImageNet预训练迁移过来时所带来的域差异;
- feature map通过尺度感知模块后,就变得对不同尺度的前景目标更为敏感;
- feature map再次通过空间感知注意力模块后,其变得更为稀疏,且聚焦于不同空间位置的前景目标;
- 最后,feature map通过任务感知模块后,其根据不同下游任务形成了不同的激活。
2.3、泛化到已有检测器
DyHead可以嵌入到已有的检测器中,以提升它们的性能。
One-stage Detector:一阶段检测器通过在feature map上密集采样来进行预测,这种方式简化了检测器的设计。经典的一阶段检测器(如:RetinaNet)由backbone网络+多种特定任务的子网络组成。正如Dynamic relu一文所提到的那样,目标分类子网络的行为与边框回归子网络有很大不同。不同于这种每种任务一个分支的设计,本文仅有一个预测分支。由于所提出的注意力模块,这个单一的分支能够处理多种不同的任务。按照这种方式,架构能够进一步简化,并提升效率。此外,Anchor_free的检测器通常将目标视为关键点或者中心点预测,其分支设计比较困难;而使用DyHead方法,仅需在head后面增加几种类型的预测即可,见图2(b)。
Two-stage Detector:两阶段检测器利用RPN和ROI Pooling从backbone网络输出的特征金字塔中提取中间表示。为了协同这种特性,作者首先使用尺度感知注意力和空间感知注意力对特征金字塔进行处理,然后再使用ROI Pooling,最后使用任务感知注意力替换原来的全连接层,如图2(c)所示。
2.4、与其他注意力机制的关系
Deformable:可变性卷积可用于backbone,显著提升特征表达能力。尽管其很少用于检测head,但我们可以将其视为DyHead中对S维度上的独立建模。在backbone中使用Deformable可以与所提出的DyHead互补。
Non-local:这是一个使用注意力模块增强检测性能的先驱工作。然而,其使用的是一种简单的点乘操作,通过融合其他位置的像素特征来增强某个像素特征,这种行为可以视为L×S维度上的建模。
Transformer:其提供了一种简单的解决方案,来学习交叉注意力通信,并通过多头全连接层从不同形式中进行特征融合。这种行为可以视为DyHead中S × C维度上的建模。
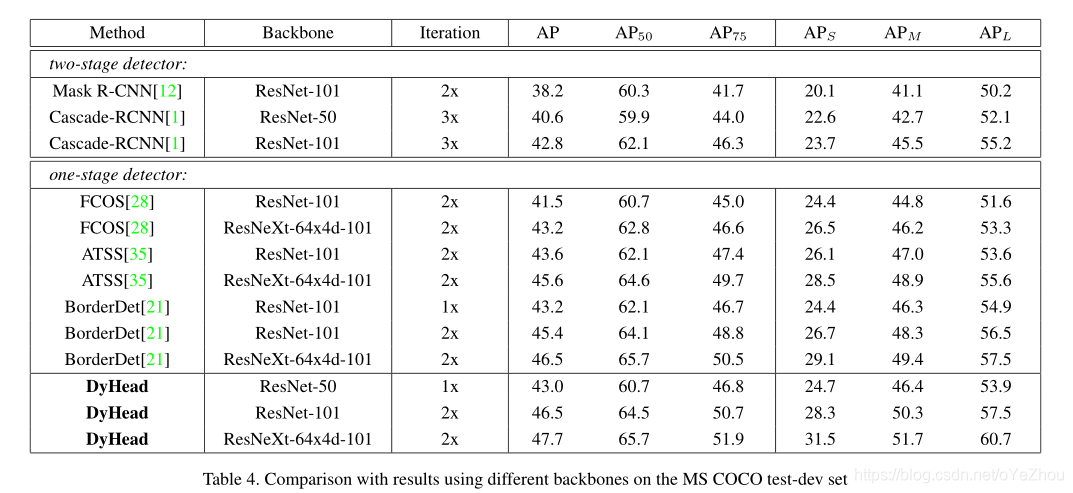
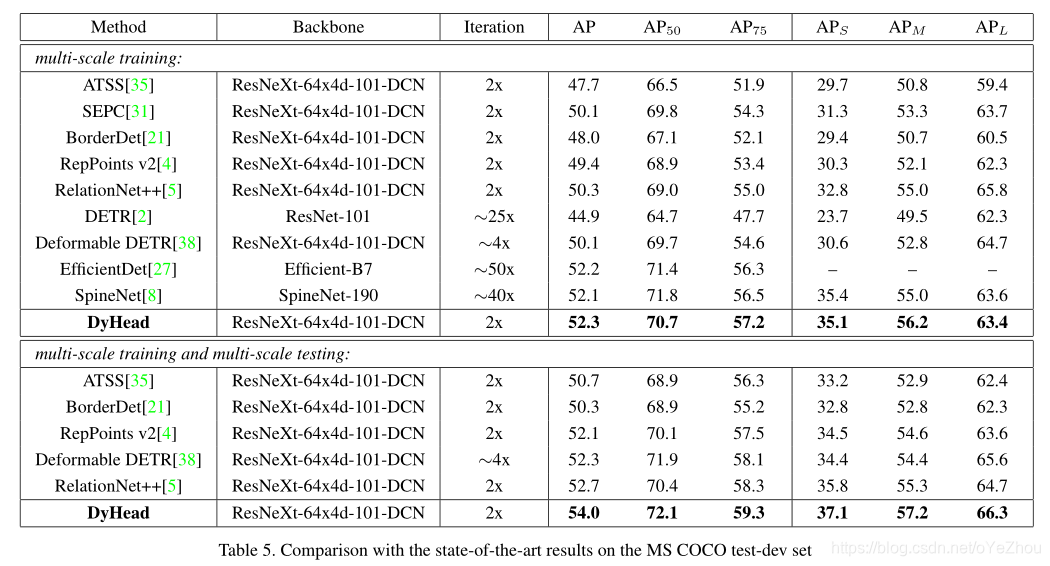
3、实验结果


















 5807
5807

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











