






Jia, B., Chen, Y., Yu, H., Wang, Y., Niu, X., Liu, T., Li, Q., & Huang, S. (2024). SceneVerse: Scaling 3D Vision-Language Learning for Grounded Scene Understanding. In arXiv [cs.CV]. arXiv. http://arxiv.org/abs/2401.09340
SceneVerse: 为基于场景理解的3D视觉语言学习提供规模化支持
3D视觉语言对齐,侧重于将语言与3D物理环境相一致,是体验型智能体发展的基石。与2D领域的最新进展相比,将语言与3D场景相结合面临着几个重要挑战:(i)3D场景的固有复杂性,由于多样的物体配置、它们丰富的属性和复杂的关系;(ii)支持基于场景的学习的配对3D视觉语言数据的稀缺性;以及(iii)缺乏一个统一的学习框架,用于从基于场景的3D数据中提炼知识。在这项工作中,我们旨在通过系统地提升室内环境中的3D视觉语言学习来解决这三个主要挑战。我们引入了第一个百万规模的3D视觉语言数据集,SceneVerse,包括约68,000个3D室内场景,由人工标注和可扩展的基于场景图的生成方法产生的250万个视觉语言对组成。我们展示了这种扩展使得可以使用统一的预训练框架,名为场景基础预训练(GPS),用于3D视觉语言学习。通过广泛的实验,我们展示了GPS在所有现有的3D视觉对齐基准上取得的最先进性能。SceneVerse和GPS的广泛潜力通过在具有挑战性的3D视觉语言任务中进行零次迁移实验证明。项目网站:https://scene-verse.github.io。

图1. SCENEVERSE概览。这是一个规模达百万级的3D视觉语言数据集,包括超过68,000个不同的3D室内场景和250万对齐的场景语言对,以场景标题、物体标题和物体引用的形式呈现。
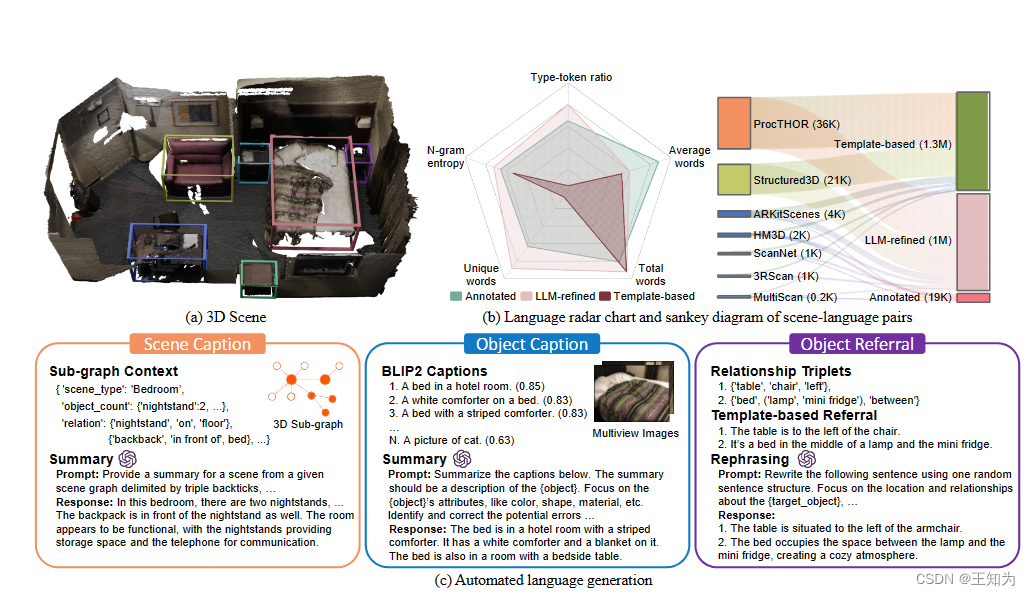
图2. SCENEVERSE的收集和统计。给定一个3D场景(a),我们的自动化流程(c)生成三种描述,包括场景标题、物体标题和物体引用。 (b) 不同语言来源和数据组成的比较。
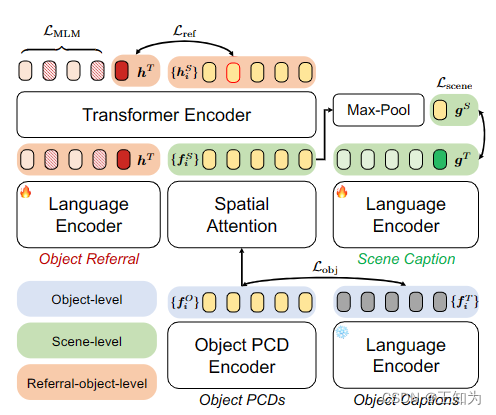
图3. 我们提出的GPS模型概览。我们在三个层次L_obj、L_scene和L_ref上利用对比对齐,以及一个用于模型学习的掩码语言建模目标L_MLM。


















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











