









到终点了?还早得很呢
什么?还没完?这都折腾了好几个月了,又是模型又是材质又是处理颜色的,我们不是把该干的都干了么,怎么还有步骤要处理啊?

是的,还没完。模型确实调节好了,也被“压平了”,而且我们还在材质库中为它找到了合适的外衣也就是对应的纹理,甚至还通过shader那像素级的精确修正改变了这些材质上不符合当前场合的颜色错误。
这些工作都很重要,前面的硬件单元们干的也都很棒,但这里有个小问题——几何单元处理的是几何模型,光栅化处理的是坐标变换,纹理单元干的是抓取纹理,shader则在不停的运算着像素相关的数字,通过它们的辛勤劳作,我们得到了处理好的几何模型,拾取出来的纹理,运算妥当的像素,得到了几乎一切构成正确图像的基本要素。
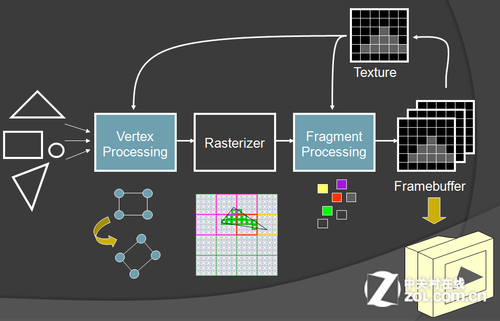
经典图形处理流水线
但我们得到的仅仅是要素,并没有得到图像。
想得到最终的图像,没有ROP单元是不行的。因为ROP单元的作用,就在于将这些图形要素所蕴含的信息混合并串连在一起,让他们形成一个完整有机的整体。
● 到终点了?还早得很呢
图像处理就好像烹调一盘鱼香肉丝,打荷师傅为我们准备了一大盘子新鲜的青椒和冬笋,砧板师傅以精湛的刀工奉上了嫩滑的肉丝,灶台上还有一堆葱姜盐糖豆瓣酱之类的调料,这些都是一盘美味的鱼香肉丝的基础。但他们仅仅是基础,要想吃到好吃的鱼香肉丝,我们必须把他们混合在一起下锅,用精湛手法加以烹调才可以。
而这,正是ROP单元的主要工作。

图形处理犹如烹饪佳肴
这世界简直就是一个茶几,上面摆满了杯具。你看,活着本已不易,各种压力和琐事让我们每天都焦头烂额了。好不容易腾出空来想要放松一下玩个游戏,结果竟然还要经历这么多复杂的处理步骤,又是几何又是变换,还要与各种方程狠狠地缠斗一番,最后还要在经历这么一个混合的过程,才能看到一帧画面。这根本就不是辛苦,简直就是命苦了。
活着,确实是一种修行啊。
| 顾杰所写过的技术分析类文章索引(持续更新) | |
| 2、 忠实微软是否有用 A/N统一构架细节分析 | |
| 3、揪出幕后罪魁祸首 是谁拖累了统一架构 | |
| 5、融聚的未来在哪里 APU构架方向发展分析 | |
| 7、NV也玩融合 探GTX700核心CPU+GPU构架 | |
| 11、iPad2也成无尽陷阱?移动GPU构架全揭秘 | |
| 13、GPU大百科全书第一章:美女 方程与几何 | 14、重归正途迎未来 AMD新GPU构架深度解析 |
| 15、GPU大百科全书第二章:凝固生命的光栅化 | 16、GPU大百科全书第三章:像素处理那点事儿 |
| 17、GPU大百科全书番外篇:那年AN那些事儿 | 18、GPU大百科全书第四章:虚与实共舞的TMU |
我是一个粉刷匠,粉刷本领强
● 我是一个粉刷匠,粉刷本领强
ROP单元一直是一个相对神秘的地方,不同于其他单元的单纯和直接,ROP单元的结构和作用一直都容易让人产生混淆。有人认定ROP单元的作用就是处理雾化之类的特效,有人觉得他是抗锯齿的场合,有人以为光栅化过程在这里进行,有人相信它是送出像素的单元。甚至连ROP单元的名字长期以来都存在着不同的版本——Raster Operations Units以及Render Output Unit。

ROP单元结构
其实,ROP单元并没有大多数人想象中那样神秘,除了觉得ROP是在处理光栅化过程的人之外,其他所有人并排坐在一起,把自己的观点重复一遍,ROP单元的功能就出来了——是的,ROP单元的功能,就是处理雾化等特定的特效,进行采样及抗锯齿操作,以及将所有图像元素混合成最终画面并予以输出。所以从作用的角度出发,相比于Raster Operations Units这种头衔味道更重的名字来说,Render Output Unit显然更加适合用来描述ROP单元。

ROP位于图像处理过程的最后一步
Render Output Unit,翻译过来就是渲染输出单元,那么渲染输出的第一步,明显就是渲染啦。

渲染实例
渲染这个词对不少人来说一直都很神圣。包括笔者在内,许多爱好者在刚刚接触到图形处理过程时,都曾经一度将渲染想象的极其复杂和神秘。其实不然,渲染过程无非就是将已经准备好的诸多图像元素混合在一起而已。几何处理单元,光栅化,TMU以及Shader单元,他们所做的看似复杂的工作,都只是为渲染过程准备基础和条件。而真正进行渲染的混合过程,跟其他图形处理过程一样,从本质上来讲其实非常简单。
把处理好的像素弄上纹理,把调好的漆刷上墙,收工。
哎呀我的小鼻子,变呀变了样
● 哎呀我的小鼻子,变呀变了样
如果仅仅是完成混合以及输出,这么简单而且轻松的工作量似乎有点太便宜了ROP单元了。没错,除了进行Z值相关的检查来保障输出像素的准确性之外,混合输出过程几乎不会带来其他更加复杂的操作。这种相对宽松和富裕的工作环境,让ROP单元有了扩展的充分理由和借口。于是随着人们图形需求的增长,ROP单元很快就具备了另一个作用,那就是协助完成全屏抗锯齿(FSAA)工作。

不同全屏抗锯齿(FSAA)等级带来不同画质
我们所看到的图像的基本构成单位是像素,而像素的形状则是一个又一个的小方格,当两个相邻像素存在巨大的颜色反差时,这两个像素中间就会出现一条非常显眼的颜色分界线。颜色分界线带来的界面效应是区分物体边缘的重要标识。

AA过程,本质上就是界面过渡性的调整
对于垂直和水平出现的像素分界来说,由于其本身的范围非常均一,因此并不会造成界面效果之外的效应,但当像素分界以斜线的形式出现时,效果就完全不一样了。斜向像素分界线,正是困扰3D图形界多年的问题——锯齿。

最简单的方法体验锯齿
打开你的画笔,尝试着画一条最简单的斜线,然后放大看看。是的,非常不幸,这就是让人讨厌的锯齿,外号“狗牙”。

不同锯齿以及FSAA过滤方法
锯齿的存在极大的影响了图形效果的表达,本来应该平滑的几何模型表面,在光栅化并变成像素图元之后变得不再平滑,这极大地影响了人们观赏图形时的感受。所有影响人们观赏图形的因素最终都要被干掉,这正是图形界发展的根本动力。为了消除锯齿感给图形造成的影响,我们有了Anti-Aliasing以及Anti-Aliasing Unit,也就是AA以及AA单元。
可抗锯齿这事,跟ROP又有什么关系呢?
锯齿怎么抗
● 锯齿怎么抗
既然锯齿的产生源自斜向分布像素之间的反差所生成的颜色分界线,那么淡化这条分界线就成了抗锯齿的首选方案。分界线的碍眼是因为他极强的对比性,那么我们如果将分界线周围数个像素的颜色提取出来进行混合,然后重新赋予分界线周围这些像素“中和”后的颜色,不就能让原本非常突兀的颜色分界线变成自然平顺的颜色过渡,并借以消灭碍眼的锯齿了么?

NV17核心抗锯齿实例
混合,中和,赋予像素新的颜色,Anti-Aliasing的这些核心内容,不正是ROP最传统的工作么。抗锯齿的原理,注定了这项工作必须通过ROP单元来进行,现在你明白AA单元为什么会出现在ROP里了吧。

抗锯齿操作过程
Anti-Aliasing过程的起点开始于对图像的放大,我们首先要将整个图像(超级采样,SSAA)或者比较精确的物体边缘(多重采样,MSAA)进行放大,然后对颜色反差巨大的物体边缘部分的像素及其周围的像素进行提取和混合,形成比原来更加自然但也更加模糊的颜色过渡,最后再将图像缩小回原来的尺寸以便消除颜色过渡产生的模糊现象。

平滑实例
ROP在AA过程中所做的事情,就是提取颜色分界线所在像素及其周围像素的颜色数值,然后对这些像素的颜色进行混合,再重新把新的过渡颜色刷上去。
又完了?是的,又完了,看似高深的抗锯齿,其实就是通过混色削减边缘比度这么简单……
每个人都有自己的好“碰友”
● 每个人都有自己的好“碰友”
几何单元后面跟着光栅化,纹理单元有shader陪伴,似乎每个人都有自己的好“碰友”,大家激烈竞争同时又相互支持,共同完成着属于自己的工作。那作为整个流水线后端的ROP,有没有自己的好“碰友”呢?

ROP需要反复对一帧画面进行多次操作
在前面的章节中我们已经知道,抗锯齿环节的操作需要频繁的对图像进行放大,缩放以及对像素采样和混合过程,这些过程意味着ROP需要反复对一帧画面进行多次操作,而且这些操作还会涉及高分辨率以及更多像素数量的问题。
另外,游戏体验很重要的组成部分就是画面的流畅度,要利用视觉残留效应让人眼误以为画面是连贯的,每秒钟ROP所需要输出的有效帧数起码要大于30帧,本来每一帧画面的数据量就比正常情况下高很多,画面总量有如此之大,这一切都意味着一件事——ROP的工作,背后蕴藏着巨大的数据量。

开启AA会带来极大的数据增量
由此可见,想要让ROP保持极高的工作效率,充足的显存带宽和缓冲空间是必不可少的。

一个64链路的CrossBar显存控制器
我们要为ROP提供的好“碰友”,不仅要满足他对数据存储空间的极大要求,同时还要让他能够在任何想要进行存储及访问操作时均能自由的对存储空间进行动作。这不仅需要一套优秀的高频高位宽显存体系,同时还需要大数量的并行显存控制器。
ROP需要的大带宽和大储存空间由前者提供,而后者则通过星形连接的Crossbar总线让每个ROP单元都与MC进行直连,从而尽可能多的降低ROP单元的存储延迟问题。
鱼香肉丝的烹调流程
● 鱼香肉丝的烹调流程
明白了ROP能干什么以及需要些什么,接下来我们就该看看ROP到底干了些什么,又是怎么干的了。只要你能明白鱼香肉丝是怎么从案板走向餐桌的,你就一定可以明白ROP单元是怎么把图像元素变成图像的。

构成图像的图元
首先,由TMU拾取的纹理以及由shader处理完成的像素会被传送到对应的z/stencil buffer,接下来ROP单元会首先对这些纹理和像素进行z/stencil检查,尽管经由光栅化处理之后的模型已经不具备实际存在的Z轴了,但其深度信息依旧会被保存下来,对于深度和模板信息的判断能够让ROP做出让那些像素被显示出来的决定,这不仅能够避免完全遮挡的像素被错误的显示在前面,同时也能够减少后续的color output部分的压力。由于存在对深度的判断和剔除操作,再加上Raster Operations Units这一特殊名称的误导,很多人都以为光栅化过程是在ROP单元才完成的,实际上Rasterization和ROP单元本身并没有什么直接联系的。Rasterization所进行的是对模型的3D-2D坐标投影变换,而ROP则是对像素的混合和输出。

z/stencil test过程
当所有像素都完成了深度检查等操作之后,特定范围深度值的像素将被输送到alpha单元进行透明度检查,由透明度及透明混合所导致的效果对于雾化以及体积光等效果有至关重要的意义,因此alpha单元的检查与深度检查几乎可以说同等重要。根据程序的需要,ROP会以Blend单元对特定的像素进行alpha Blending操作。

alpha Blending半透明混合贴图操作
经过上述步骤之后,剩下的像素将会被填充进2D化模型需要的范围内,也就是我们常见的Pixel Fillrate过程。Pixel Fillrate就好像一口大锅,作为肉丝、青椒、冬笋还有葱姜盐糖豆瓣酱之类原料出现的像素会在这里被正确的混在一起。经过混合,图形元素所包含的原本孤立的信息会像食材之间交互作用产生的香气一样被释放出来,最终形成我们能够接受的图像。

锯齿与抗锯齿
由于像素上的效果已经被shader以数学的形式处理完毕了,因此如果没有AA操作,那么到这里为止图形渲染工作就算彻底完成了,所有效果的混合及填充将会让正确的画面最终得以呈现,这幅完成处理的画面会被送入output buffer等待输出。而如果程序要求进行AA操作,比如MSAA,那么ROP中的AA单元还需要对填充完毕的画面进行若干次多重采样,然后再对采样出来的像素点进行color Blending操作,完成之后的画面才会被送入帧缓存等待输出到屏幕上。
装盘,上桌。混合,输出。
一个厨子引发的危机
● 一个厨子引发的危机
有人的地方就会有争议、争执甚至是争斗,GPU领域自然也不例外。不管ROP单元是忙活装修的粉刷匠,还是演绎火的艺术的大厨,安分守己的他似乎并未躲开成为事件中心的命运。
ROP承担着最终混合和输出图形的任务,它所需要处理的像素几乎等于前面所有步骤处理像素的总和,它的最终效率也决定着整个流水线的效率,即便前面的单元再强大再高效,如果ROP单元不足,整个体系就会遭遇到Fillrate wall,无法将上游过来的诸多图形元素进行混合也就无法完成输出,最终的帧数自然会受到影响,HD5830/6790就是明显的例子。

ROP单元削减一半的HD6790芯片
因此,保障ROP的总效率对GPU构架来说是极其重要的。由于Z/stencil检查和操作、AA以及blind过程都十分耗费显存带宽以及ROP自身的资源,因此与别的单元独善其身不同,为了获得更好的ROP动作效率,人们不仅要增加ROP的总数量,同时还要为其配置充足的显存带宽及显存控制器资源。

fillrate过程
说配就配?难道晶体管不要钱的么?
以常规GPU的结构来看,每增加一个ROP/MC,不仅要添置这些单元及其配套资源的晶体管,还要考虑星形互联的crossbar总线所带来的沉重负担。动辄数亿的晶体管增量,对任何一颗GPU来说都不是一个小数目。在制程上限和芯片面积限定了晶体管总数的前提下,ROP这种近乎于喝水一般消耗晶体管的单元,势必会影响到其他单元所能够占有的资源总量。

拥有庞大ROP规模及恐怖带宽的Fermi核心
那能不能找一个不怎么浪费晶体管又能提升性能的方法呢?似乎有,比如Imagination的TBR/TBDR。

TBDR技术细节
TBDR全称Tile-based Deferred Rendering,它通过将每一帧画面划分成多个矩形区域,并对区域内的所有像素分别进行Z值检查,在任务进入渲染阶段之前就将被遮挡的不可见像素剔除掉。由于在渲染之前进行Z-culling操作,TBR/TBDR理论上能够大幅削减进入shader以及ROP的像素数量,这不仅大幅降低了系统对像素的处理和输出压力,更极大的节约了显存带宽及空间的开销。
问题来了——既然有这样的技术,为何不用呢?

TBDR技术理论上对显存的节约度
尽管Imagination以及其TBR技术在几年前已经自桌面领域败亡至SoC及其他低功耗芯片领域,目前桌面GPU的几乎全部灵魂也都是由当年那一场胜负决定的,可以说今天桌面GPU的尊严和荣耀,都是由更大数量的ROP/MC这一理念所带来的。

PowerVR MBX构架
但伴随着近年来移动领域的迅猛增长,Imagination因为在智能手机及平板电脑平台,特别是苹果平台上稳定的统治地位而不断壮大,功耗性能及晶体管消耗比例暂时占优的TBR/TBDR技术大有重归桌面领域的趋势,Imagination的Roadmap中颇具挑衅性质的MBX及SGX MPx系列就很能说明问题。如果Imagination凭借苹果为其带来的厚厚一叠美金最终成功回归了桌面领域,并且以TBR/TBDR技术重新占领市场甚至是主流,那就意味着对几年前那场胜负的完全推翻,以及对近年来桌面GPU发展思路的极大否定。
山雨欲来风满楼啊。
一致对外
● 一致对外
NVIDIA和ATI/AMD在桌面GPU领域是激烈的竞争对手,他们的恩恩怨怨多得可以写一部百万字以上的传记体长篇小说。双方的发展思路,理念以及对市场和需求的看法在细节上存在非常大的差异,产品风格和强调重点也不尽相同,但在某个本质问题上,双方却保持了高度的一致,起码是大方向上的一致。那就是在彻底依赖TBR等类似的Early-Z手段和结合类似手段的同时保证充足的ROP/MC资源的选择中,坚定的支持后者。

将ROP等后端统和成RBE的R600构架
无论是G80/GF100还是R600/RV970,NVIDIA和ATI/AMD的GPU构架无不强调着ROP以及显存带宽的重要性。双方近年来的旗舰GPU的ROP数量从未低于过16个,而显存带宽则更是一路飙升到了近200G,尽管实现手段存在差异,但大方向上的一致性根本无需多言。甚至近年来GPU战场中少有的RV770这样漂亮的“翻身仗”,其成功的关键也在于ROP以及显存带宽的极大改进。

非公版GF110的显存带宽更为恐怖
是什么导致了斗争不断的两个冤家一致对外,又是什么导致了几年前那一场桌面GPU发展之路大战中Imagination的败北呢?答案就在TBR/TBDR本身。
对于常规的光栅化过程来说,TBR/TBDR会带来诸多的问题。包括深度检查耗损、频繁的Z读取、Tiles划分带来的纹理重复读取、多边形数量上升之后的scene buffer溢出等等。最初的TBR甚至需要CPU来进行Z-Occlusion Test,尽管后来的TBDR不再像传统的TBR那样需要通过CPU来进行Z值检查,但是TBDR过程需要对画面内所有的像素进行一次“额外”的load过程,这个过程本身无论从哪个角度来讲都是与节约显存带宽背道而驰的,尤其是在复杂度极高但Z-Occlusion并不严重的场景中更是如此。

割裂多边形过程
另外,尽管对画面的矩形划分越细密,GPU对像素进行Z判断的效率和准确率越高,但TBDR过程对画面的矩形切割非常机械,这种划分经常会导致很多多边形和纹理被Tiles所切割,这些多边形和纹理都必须经过2次甚至4次读取才能保持自身形态的“完整”,这无疑加重了几何和纹理处理过程的负担。如果场景的多边形数量较多,这种切割还会导致scene buffer被快速的消耗殆尽,scene buffer的溢出会直接导致Z判断延迟的急剧增大,这对整个处理过程的影响是巨大的。

scene buffer溢出导致的错误图像
通俗的说,TBDR需要在屏幕上画很多很多的小格子,然后把格子里的所有像素都拿出来做某种检查,没通过检查的“坏”像素就会被丢掉。尽管丢掉这些没通过检查的像素可以让后面的工作量减小,但这个检查本身对渲染没有任何意义,所以没有被丢掉的像素就相当于走了一遍无用的过场。与此同时,划分小格子的过程会切坏很多多边形和纹理,想要让这些多边形和纹理能够从“误伤”中幸存下来,你切了它们多少刀就要重新读取它们多少次。如果多边形本身就很多,被误伤的概率就更大,这会使得系统的某种缓存被快速消耗干净,缓存没了,系统干什么都不可能快得起来。

Z Occalusion检测软件——VillageMark
当这种问题累积到一定地步之后,采用TBR/TBDR等手段的GPU不仅无法节约显存带宽,相反还会更加依赖显存带宽。目前采用这一技术的SGX543MP2拥有吞吐shader更加高效的USSE单元,4倍于竞争对手Geforce ULP的理论性能以及双倍以上的显存带宽,最终的实际性能却被对手紧紧咬住,如果SGX543MP以单芯片的形式登场,最终的性能甚至可能会负于竞争对手。
对于这样一个技术,我想NVIDIA和ATI/AMD在ROP上的坚持根本就是无需考虑的。Early-Z技术确实有它非常积极的一面,但如果将Early-Z强调到唯一的高度,所换来的结果根本就是与Early-Z技术的初衷背道而驰的。桌面显卡如果放弃传统的ROP/MC规模换取执行效率的发展方向,转而开始倡导类似TBDR的技术,其结局必定会像现在采用TBDR的SGX系列显卡一样尴尬。因此,理智的厂商都会坚持传统的ROP/MC的发展思路,并逐步的将更有效地Early-Z纳入到流水线中去以便辅助现有的渲染方式。

推动这个世界发展的,是金钱啊!
但是我们生存的世界,似乎并不是一个理性能够占主导的世界。Imagination从苹果那里赚来了一叠又一叠的绿票,这些绿票不仅可以击败理智并使人疯狂,更能改变市场需求甚至是移山填海……
“推动这个世界发展的,是金钱啊!”——美神令子。
止战之殇
● 止战之殇
Imagination不是不知道TBDR技术这些天生的弊端,其旗下SGX系列显卡那顽固的理论性能/景深系数的实际表现也一直让其头疼不已。但在最初退到嵌入式及低功耗芯片领域时,Imagination显然没有选择。在SoC领域,芯片的功耗就是一切的指挥棒,抛弃ROP/MC为主的思路,坚持以TBR/TBDR这类减少无效渲染的操作方式为基础的发展思路刚好能够迎合该领域的需求。所以从桌面败亡的Imagination坚强的在SoC领域活了下来,并且以其在低性能需求阶段较高的功耗性能比获得了苹果的青睐,并最终赚的盆满钵满。

跟苹果混就意味着赚钱
如果Imagination静静地呆在SoC领域,继续与苹果续写今天IOS设备的神话,桌面GPU领域自然不会受到多大的影响。尽管移动设备尤其是平板电脑的大行其道缺失让桌面领域头疼不已,但毕竟双方并非直接的对决,桌面领域依旧可以凭借绝对性能上毫无疑问的领先维持住自己的一部分固定市场。但现在,来自苹果强劲需求所带来的丰厚利润显然让Imagination发生了某些化学反应,变得不再安分于SoC领域。不断更新的USSE指令集,PowerVR MBX以及SGX MPx系列无不清晰地显露着Imagination重返桌面领域的野心。而如果Imagination重返桌面领域,其丰沛的资源虽然不一定能改变现有市场对性能需求的看法,但却一定可以让TBDR技术搅起一片漫天尘埃,让本已尽显混沌和发展不平衡的桌面显示领域变得更加让人迷茫。

似乎已经停滞不前的桌面显示技术
没人希望市场和发展前景一片混沌,也没人希望自己被轻易的超越和淘汰,起码NVIDIA和AMD都是如此。因此不管是出于何种目的,是防范Imagination也好是对抗自己的对手也罢,反正NVIDIA和AMD对桌面GPU的性能改进,尤其是ROP/MC的性能改进,一刻也没有停止过。只有保持在性能上的绝对领先,才能通过压制对手以及创造和满足更高的需求等手段来防止对手的进入。ROP单元,也便因此而成了桌面显卡发展的保护者了。

ROP单元细节
NVIDIA以及AMD对ROP部分的改进,首先是常规的增加ROP以及显存带宽的绝对数量。我们前面已经提到了,近年来无论是NVIDIA还是AMD,其GPU构架的ROP资源及显存带宽都在不间断的增长着。在最新的Fermi构架中,NVIDIA GPU的ROP单元数量已经达到了恐怖的48个,而显存带宽更是被加到了192GB/S这一空前的数字。下一代的Kepler及GNC构架将很有可能拥有64个左右的ROP单元,以及接近甚至超过300GB/S的显存带宽。更多ROP单元可以保证GPU拥有更高的像素处理和填充能力,而更高的带宽则可以满足ROP对AA等操作的需求。尽管这些举措均非常消耗晶体管资源,但更多的ROP单元显然可以带来更加强劲的输出效率,其所带来的对整体性能的提升可以说是立竿见影的。

添加Z/stencil buffer所带来的性能提升
除了扩展规模之外,进一步改进ROP及整个后端内部的结构,使其具备更高的像素输出效率也未尝不是一条合适的道路。比如当初Z/stencil buffer的加入就为ROP单元带来了不小得性能提升,现在继续增大Z-buffer以及stencil buffer来变相提升ROP单元的单位周期以及某些特定环境下的像素吞吐能力,也是一种很好的尝试,在这方面AMD构架走的相对靠前,相信其构架如GNC等,在未来会有更多更加强大的改进出现。
这样总该完结了吧,什么?还没有?
● 这样总该完结了吧,什么?还没有?
我们可以在日常生活中找到很多与ROP类似的图景。前面提到的将所有材料炒成一盘佳肴的大厨,GPU大百科前传中出现过的刷漆师傅,流水线上将所有元件组装成机械的工人,他们都是ROP单元在现实生活中所对应的形象。ROP单元所从事的工作,与他们没有任何区别。
因为他们所从事的工作,都是从单个元素向成品的跨越。

粉刷匠的工作,与ROP是一样的
ROP单元对于GPU来说是不可或缺的组成部分,它负责着图形过程中图像元素向画面的最终跨越,混合像素并输出这一特性,让它的性能直接决定了画面输出的速率,进而影响到整个GPU的实际性能表现,它甚至还是桌面GPU维持自身地位和荣耀的重要标志。作为整个图形流水线的最后一步,ROP单元真可谓是图形之根本。

深受ROP单元裁剪限制的HD6790
在经历了ROP单元的故事之后,伴随着画面的最终输出,我们关于图形“处理”过程的全部步骤就算完成了。我们用了整整3个月,累计7篇文章的篇幅来完整的进行了一次GPU硬件执行流程的巡礼,这漫长而疲劳的过程相信应该能给屏幕前的你带来一点点收获了吧。

传统到怀旧的NV20流水线
完成对整个GPU硬件流水线各个单元的观察并不是GPU大百科全书系列的终点,要理解了解GPU的方方面面,我们所要涉及的故事还有很多——比如存在于各个单元之间的、直接关乎着它们动作效率的缓冲体系,还有GPU各个组成单元之间一些非常有趣的数字关系,以及它们与最终性能之间的联系等等。请相信我们,GPU内还有着更多精彩的故事和真相在等待着你的发掘和思考,而这些精彩的故事都会在接下来的GPU大百科全书中一一的为你呈现,各位敬请期待吧。














 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









