






Meta最新发布的Llama 4系列标志着开源大语言模型(LLM)的重大演进,其采用的混合专家(MoE)架构尤为引人注目。
两大核心模型——Llama 4 Scout(170亿参数含16专家)和Llama 4 Maverick(170亿参数含128专家)——展现了Meta向高效能AI模型的战略转型,这些模型在挑战传统扩展范式的同时保持了强大性能。
本文将深入解析这些模型的技术原理、架构创新、训练方法、性能基准测试及安全措施。通过多维度技术剖析,我们可以更清晰地理解Meta如何突破计算效率型大语言模型的能力边界。

理解专家混合架构
在深入探讨Llama 4的具体实现之前,理解MoE架构背后的核心理念至关重要。
为何选择MoE?
• 可扩展性与可控计算成本:模型可提升容量,而不会线性增加推理成本
• 动态路由机制:通过学习的门控机制,将每个token路由至最相关的专家模块
核心概念
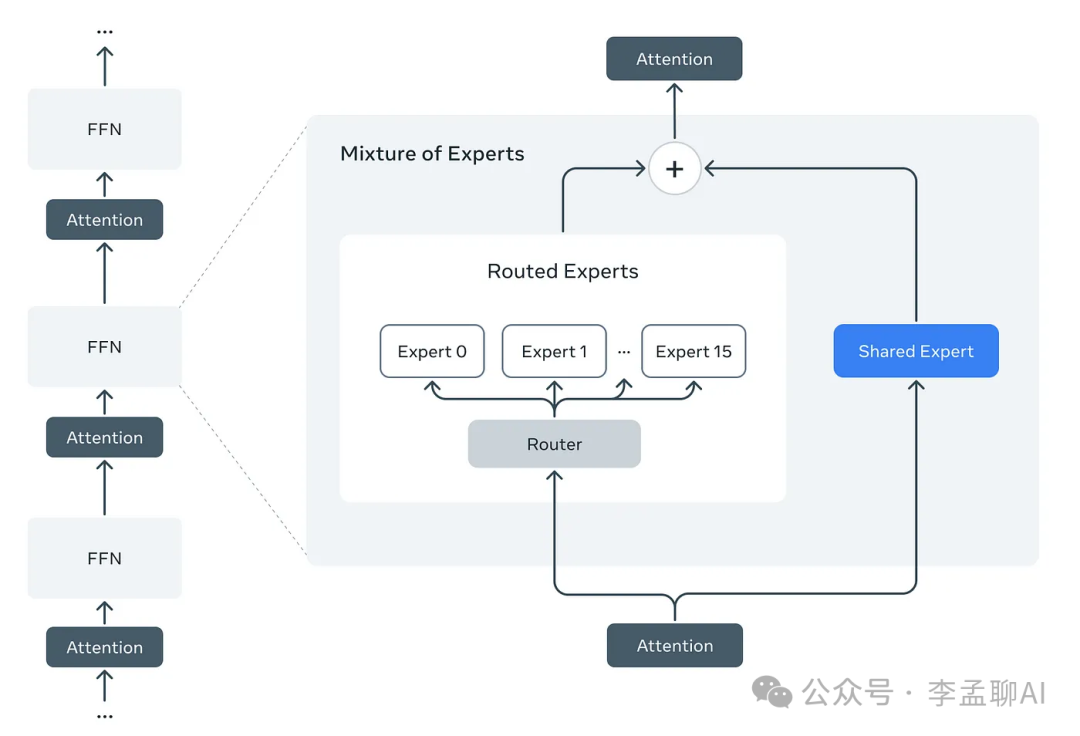
专家混合(Mixture-of-Experts,MoE)是一种模型架构设计方法,其核心在于模型由多个"专家"神经网络组成,每个专家专精于处理任务的不同方面。通过路由机制(通常是一个"门控网络")动态决定由哪些专家或专家组合来处理特定输入。
与传统稠密模型(所有参数对每个输入都激活)不同,MoE模型在前向传播时仅选择性激活部分参数。
这种选择性激活机制使MoE模型能够扩展到更大的总参数量,同时在推理和训练阶段保持合理的计算成本。
MoE模型与稠密模型的差异解析
在早期Llama版本等标准稠密Transformer模型中,每个输入词元都需要调用全部参数参与计算。随着模型规模扩大,计算成本和内存需求呈线性增长。
而MoE模型通过以下机制引入稀疏性:
- 参数专家化分组:用多个专家模块替代Transformer块中的前馈网络层(FFN)
- 动态路由机制:通过可学习的路由函数决定每个词元分配的专家组合
- 局部专家激活:每个输入词元仅激活部分专家模块,实际调用的参数量仅占总量的很小比例
这种架构使MoE模型具备双重优势:在激活参数量相同的情况下性能优于稠密模型,在总参数量相同时计算效率更高。
Llama 4的MoE架构实现

体系结构概览
Llama 4推出两种MoE变体:
• Llama 4 Scout: 170亿激活参数配置,集成16个专家模块
•Llama 4 Maverick: 170亿激活参数配置,集成128个专家模块
注:所述"170亿参数"特指推理时激活的参数量,其总参数量将显著更高。这种设计使模型既能调用海量参数空间中的知识,又能保持合理的计算资源需求。
专家分布与路由机制
(基于行业先进模型的典型实现方案)
尽管Meta未公开具体实现细节,当前顶尖MoE模型通常采用以下设计原则:
专家部署策略
• 结构替代:用MoE层部分或全部替换Transformer块中的FFN层
• 动态激活:采用Top-k路由机制(通常k=1或2),每个词元仅激活最相关的k个专家
• 负载均衡:通过算法确保各专家训练量均衡,防止出现某些专家完全未被调用的"专家坍缩"现象
Llama 4的对比实验设计
Scout(16专家)与Maverick(128专家)的核心差异揭示Meta正在探索:
→ 不同稀疏化程度对模型性能的影响
→ 少量通用型专家 vs 大量专用型专家的效益权衡
预训练阶段
Meta 指出,LLaMA 4 模型在数据效率上有所提升,尤其在低资源语言和代码领域表现更优。
训练数据
-
语料构成:混合公开数据集与授权数据
-
训练规模:约 15–20 万亿 tokens(Meta 未公布精确数字)
-
多语言 & 多模态:
-
- Scout 和 Maverick 针对多语言理解优化
- 部分变体支持图像+文本混合输入
架构特点
- 解码器结构:纯解码器 Transformer
- MoE 集成:专家混合层 + 动态路由学习
预训练策略解析
(基于MoE模型的典型训练范式)
尽管Meta未公开Llama 4的具体预训练细节,MoE模型通常遵循以下核心策略:
1. 数据构成
- 可能包含多样化语料:网页文本、书籍、代码
- (基础版本可能仅限纯文本,但预留多模态扩展能力)
2. 专家初始化
- 随机初始化:从零开始训练专家模块
- 稠密模型迁移:基于已有稠密模型参数扩展为专家架构
- 定向专业化训练:让不同专家专注特定数据分布
3. 负载均衡优化
- 引入特殊损失函数:确保所有专家均获得梯度更新
- 防止"专家坍缩"现象:避免部分专家被永久闲置
4. 容量调控机制
- 动态调整每个专家处理的token量
- 在严格路由与计算效率间取得平衡
5. 扩展规律差异
- 性能提升双路径: ✓ 专家数量增加 ✓ 单个专家规模扩大
- 遵循与稠密模型不同的扩展定律
训练后技术
Llama 4模型可能采用的训练后优化技术包括:
- 监督微调(SFT):通过人工标注样本调整模型输出,使其符合预期响应
- 人类反馈强化学习/AI反馈强化学习(RLHF/RLAIF):基于偏好数据,通过人类或AI反馈进一步优化模型输出
- 专家剪枝:可能剔除或合并表现欠佳的专家模块以提升效率
- 知识蒸馏:可能将大型混合专家模型的知识蒸馏至小型模型,或将完整专家集知识浓缩至专家子集
基准测试与性能表现

根据Meta内部评估,LLaMA 4 Scout与Maverick模型在多项指标上不仅可与GPT-4、Gemini等开源及商业模型抗衡,部分领域甚至实现超越。虽然当前公开资料未披露具体测试数据,但混合专家(MoE)架构模型通常呈现以下优势:
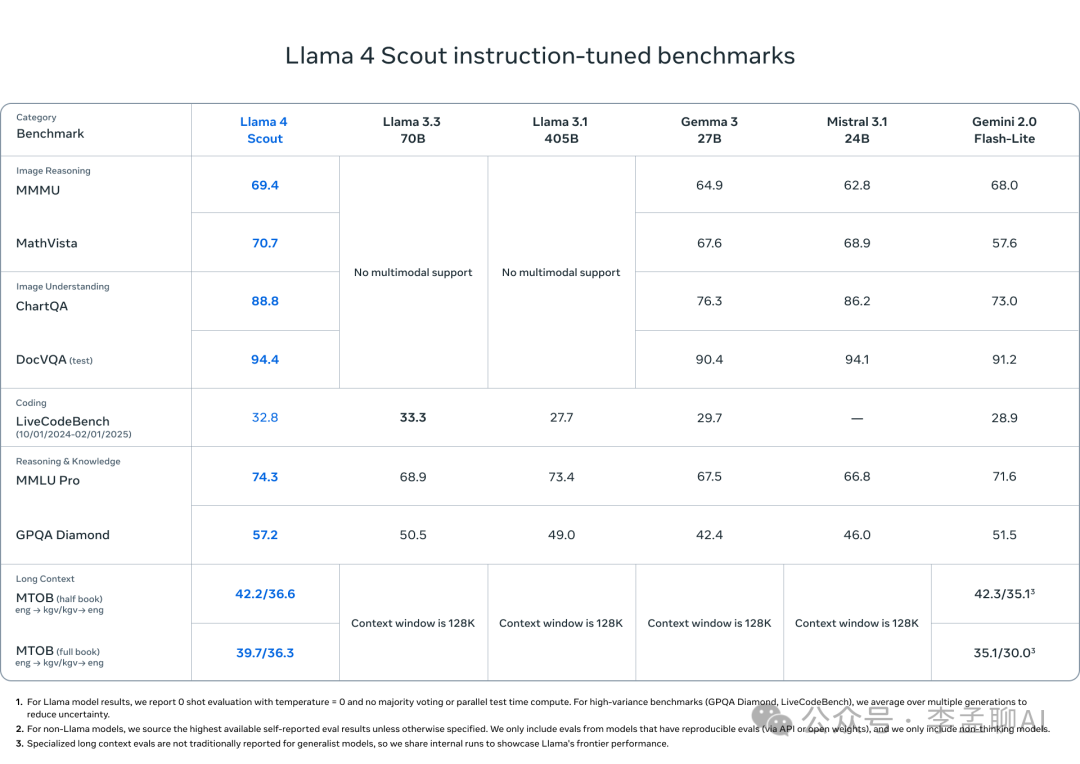
预期优势
- 参数效率:在激活参数量相同的情况下,性能显著优于稠密模型
- 内存效率:总参数量相同时,推理过程内存占用更低
- 领域专精:在需要专家模块分工的专业任务中表现更优
- 计算效率:在控制浮点运算量(FLOPs)的前提下,推理性能优于稠密模型
逐步本地安装指南
请按照以下步骤在本地设备上安装并运行 meta-llama/Llama-4-Scout-17B-16E-Instruct 模型
⚠️ 重要硬件要求🛑 最低显存需求:• 以 FP16/bfloat16 精度运行 LLaMA 4 Maverick (17B, 128E) 需超过 67GB 显存
• 需配备 NVIDIA A100 (80GB)、H100 等高性能显卡,或多卡并联使用 device_map=“auto” 进行模型分片
步骤 1:安装必要依赖
执行以下命令安装所需库:
!pip install torch
!pip install git+https://github.com/huggingface/transformers
!pip install git+https://github.com/huggingface/accelerate
!pip install huggingface_hub
步骤 2:Hugging Face 身份验证
- 访问 Hugging Face 平台
- 签署《LLaMA 4 社区许可协议》
- 完成模型访问授权
!huggingface-cli login
步骤 3:加载模型与处理器
执行模型初始化操作,载入预训练权重及配套处理器组件
from transformers import AutoProcessor, Llama4ForConditionalGeneration
import torch
model_id = "meta-llama/Llama-4-Maverick-17B-128E-Instruct"
# Load the image-text processor and model
processor = AutoProcessor.from_pretrained(model_id)
model = Llama4ForConditionalGeneration.from_pretrained(
model_id,
attn_implementation="flex_attention",
device_map="auto", # Enables automatic GPU placement
torch_dtype=torch.bfloat16
)
步骤 4:准备图像输入与提示词
• 选项一:使用公开图像URL链接
• 选项二:通过PIL.Image加载本地图像文件
url1 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/0052a70beed5bf71b92610a43a52df6d286cd5f3/diffusers/rabbit.jpg"
url2 = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/cat_style_layout.png"
# Create a multimodal prompt
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": url1},
{"type": "image", "url": url2},
{"type": "text", "text": "Can you describe how these two images are similar, and how they differ?"}
]
}
]
步骤 5:格式化输入数据
调用处理器组件实现:
- 应用对话式模板
- 对输入内容进行标记化(tokenize)处理
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
步骤 6:执行推理并获取响应
启动模型前向传播,生成文本输出结果
outputs = model.generate(
**inputs,
max_new_tokens=256,
)
# Decode the output (excluding the prompt tokens)
response = processor.batch_decode(outputs[:, inputs["input_ids"].shape[-1]:])[0]
print(response)
安全防护与责任部署
Meta为LLaMA 4系列模型构建了多层次的安全对齐体系
核心防护机制
• 安全分类器:内置经过训练的分类模块,可识别并拒绝危险/有害指令
• 拒答机制:强化训练模型对虚假信息、仇恨言论及有害内容的拒绝生成能力
• 长对话过滤:专项优化确保长时间对话中保持主题一致,抵御越狱尝试
透明度与评估体系
• 开放模型卡片:每个模型均附带详细技术文档,明确说明使用限制及适用场景
• 红队测试:Meta组织内外专家团队进行漏洞测试和极端案例验证
Meta特别强调:LLaMA 4不仅具备强大能力,更实现了安全性、可追溯性与可审计性三重保障
总结
Meta推出的16专家与128专家配置的Llama 4模型,标志着开源大语言模型发展迈出重要一步。通过采用混合专家(MoE)架构,Meta在持续突破模型性能边界的同时,有效应对了AI模型规模扩展带来的计算挑战。
Scout与Maverick采用不同专家数量的设计,表明Meta正在积极探索模型容量、推理效率与任务性能之间的最优平衡点。随着这些模型向研究社区和开发者开放,我们有望获得关于如何最佳利用MoE架构的丰富新见解。
尽管混合专家模型本身并非全新概念,但其与广受欢迎的Llama系列的结合,或将加速这一高效架构在整个AI生态系统的普及。
长期来看,这可能带来更高效的计算资源利用、更易获取的高性能模型,以及无需完整模型再训练即可实现专业化的新方法。
如何零基础入门 / 学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么我作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,希望可以帮助到更多学习大模型的人!至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈
全套AGI大模型学习大纲+路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。




👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉 福利来袭CSDN大礼包:《2025最全AI大模型学习资源包》免费分享,安全可点 👈

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









