








文章目录
原文
代码
Abstract
本文主要研究了长尾分布下的实例分割问题,并提出了一个简单而有效的解决方案——SimCal方法。在现有的实例检测和分割模型中,它们通常只适用于样本数量相当平衡的数据集,如COCO数据集,而在现实场景下,数据集通常是长尾分布的,这会导致性能下降。作者通过系统地调查了Mask R-CNN模型在LVIS数据集上的表现,发现其准确率下降的主要原因是物体提案分类不准确。为了解决这个问题,作者首先考虑了各种技术来提高长尾分类性能,这些技术确实提高了实例分割结果。然后,作者提出了一种简单的校准框架,使用双层类平衡采样方法更有效地缓解分类头偏差。这种方法显著提高了LVIS数据集和他们采样的COCO-LT数据集上尾部类别的实例分割性能。该分析提供了有用的见解,可用于解决长尾实例检测和分割问题,而SimCal方法可以作为一个简单但强大的基准线。该方法已经赢得了2019年LVIS挑战赛。
Method
Using Existing Long-tail Classification Approaches
给定样本xi,模型输出logits,记为yi, pi是对真实标签z的概率预测
Loss Re-weighting
这一思路通过对不同的样本或类别施加不同的权值来缓解偏差,从而使尾类或样本在训练过程中得到更高的关注,从而提高分类性能。
具体来说,每个类的训练样本用w = N/Nj加权,其中Nj是第j类的训练实例数,N是一个超参数。为了处理噪声,权重被限制在[0.1,10.0]。背景的权重也是一个超参数。在训练时,第二阶段的分类损失加权为L = -wi log(pi)
Focal Loss
焦点损失可以看作是损失重加权,通过预测自适应地给每个样本分配一个权重。它最初是针对一级检测器的前景-背景类不平衡问题而开发的,也可以用于缓解长尾问题中的偏倚,因为头类样本由于训练足够而往往损失较小,而尾类样本的影响会再次放大。这里我们使用焦损
L = -(1 - pi)γ log(pi)。
略
重加权方法往往会使数据极度不平衡的深度模型的优化复杂化,对于长尾分布的目标检测也是如此,从而导致头部类的性能较差
Focal loss很好地解决了前景和简单背景样本之间的不平衡问题,但难以解决相似度和相关性较高的前景对象类别之间的不平衡问题
class-aware margin loss,在损失计算中强制执行的先验边际也会使深度模型的优化复杂化,导致头部类的性能下降更大
重复采样策略遭受过拟合,因为它从尾类重复采样
Proposed SimCal:Calibrating the Classifier
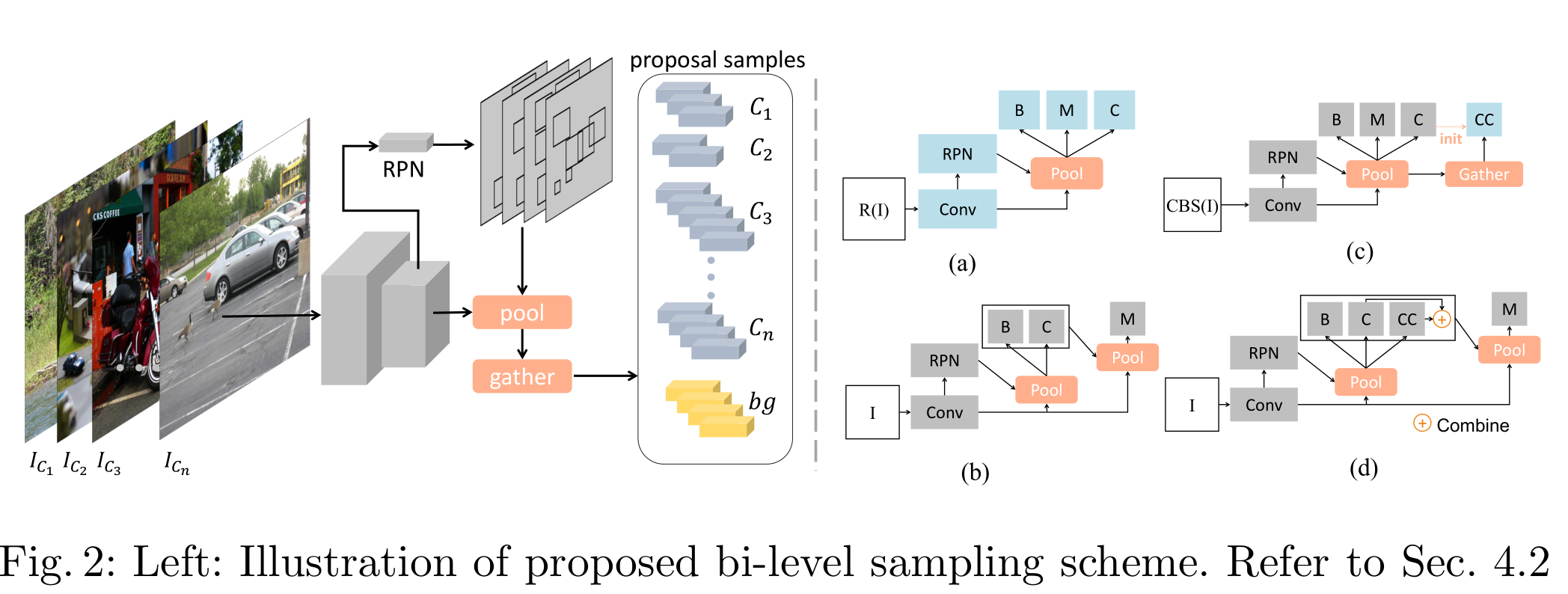
如图,作者提出了一种双水平采样方案,收集训练实例,通过再训练来校准分类头
首先,从所有类别(即c1到cn)中均匀地抽取n个对象类(它们具有相同的概率)。然后,我们分别随机选取包含这些类别的图像(即Ic1到Icn),并将其输入到模型中。在对象级别上,我们只收集属于抽取类别和背景的提议用于训练。以上,我们只是为了简化起见,为每个抽取类别选取一张图像,但请注意,抽取的图像数量也可以更大。
如图2右(a)所示,在标准训练后,我们冻结了除分类头外的所有模型部分(包括骨干、RPN、盒子和掩码头),并采用双水平采样来重新训练分类头,该分类头以原始头初始化。然后,向分类头提供相当平衡的建议实例,从而使模型能够消除偏差。与传统的在大规模数据集上预训练后在小规模数据集上进行微调不同,我们的方法只改变数据样本分布。
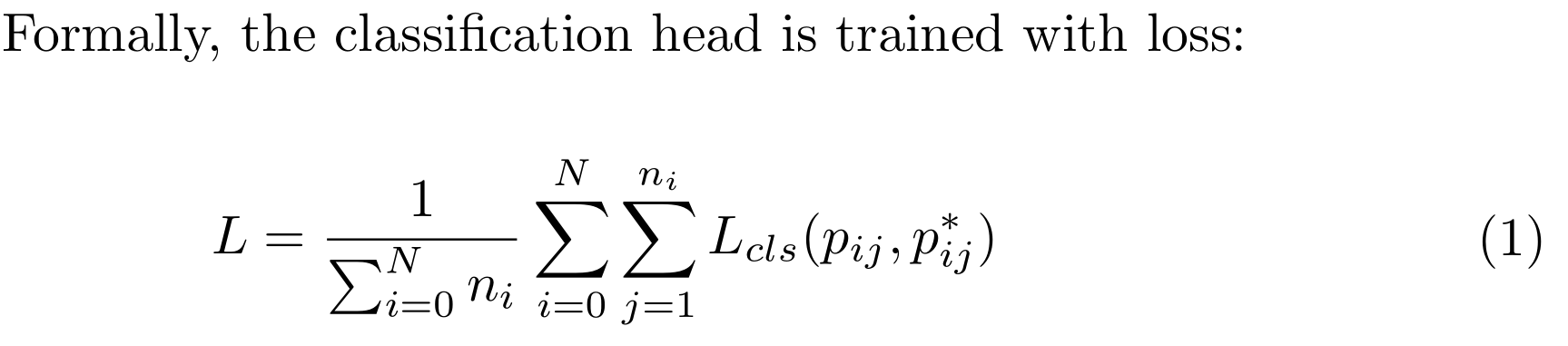
N为每批抽样类别的数量,ni为第i类的提案样本数量,i =0为背景,Lcls为交叉熵损失,pij和p * ij表示模型预测和基础真值标签
Dual Head Inference
经过上述校准,分类头现在在类别上是平衡的,并且在尾部类别上可以表现得更好。然而,头类的性能下降。为了达到最佳的整体性能,我们考虑将新的平衡头和原有的平衡头结合起来,它们在尾部和头部类别上分别具有更高的性能。因此,我们提出了一个双头推理架构。
作者提出了一种新的组合方案,直接从头类和尾类两个分类器中选择预测结果: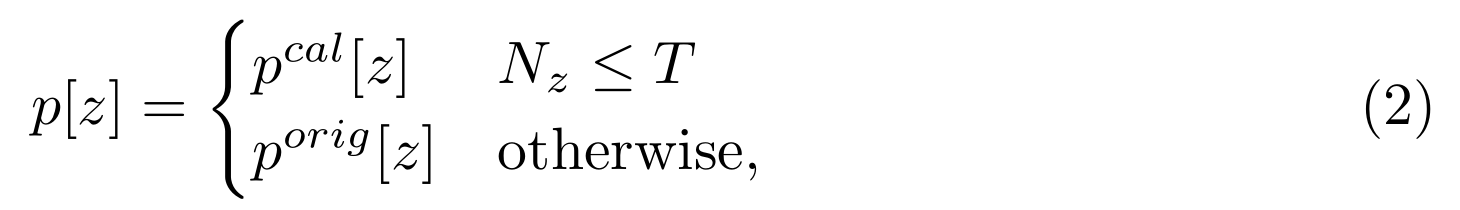
其中z∈[0,C]表示类别,C为类别数,z =0表示背景,pcal和porig分别表示振动头和原始头的(C+1)维预测,p为组合预测,Nz为z类的训练实例数,T为控制头尾类别边界的阈值数,推断的其他部分保持不变(图2 (d))。
Experiment
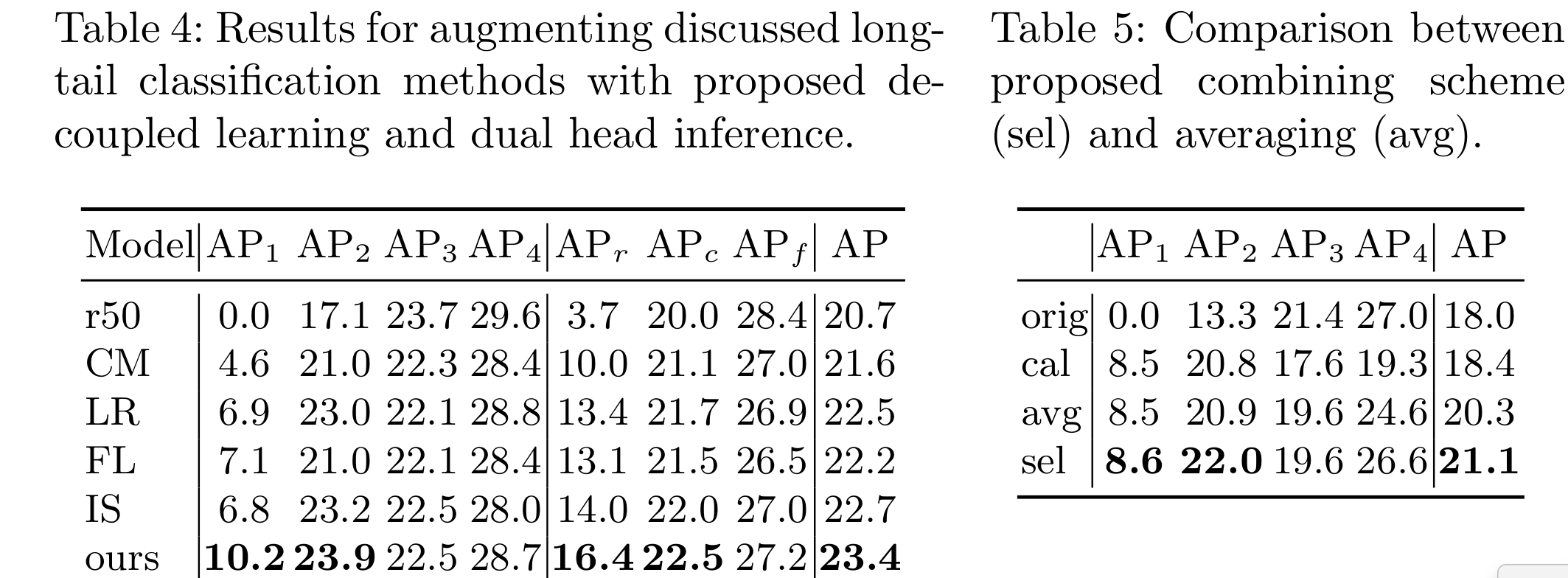
作者首先使用了四种常见的长尾分类方法(loss re-weighting、class-aware margin loss、focal loss和image level repeat sampling)来解决LVIS数据集中的长尾问题,并对其效果进行了评估。结果表明,这些方法虽然可以在一定程度上提高长尾类别的性能,但也会导致头部类别的性能下降。接着,作者将SimCal框架应用于Mask R-CNN模型中,并与上述方法进行了比较。结果显示,SimCal框架可以显著提高长尾类别的性能,同时也能保持头部类别的性能不变或略有提升。此外,作者还分析了不同类型的分类器(class-wise和class-agnostic)在长尾类别上的表现差异,并提出了进一步改进的方向
创新
使用了一种新的双层采样方案,结合图像级别的采样和实例级别的采样,以收集平衡类别的提议样本,并使用这些样本来校准分类器。
引入了一个简单的双头推理组件,有效地减轻了头部类别性能下降的问题















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









