






1 论文简介
-
作者
- Christian Szegedy Alexander Toshev Dumitru Erhan 论文来源
- Szegedy C, Toshev A, Erhan D. Deep Neural Networks for object detection[J]. Advances in Neural Information Processing Systems, 2013, 26:2553-2561. 论文概要
-
(1) 摘要
Deep Neural Networks (DNNs) have recently shown outstanding performance on image classification tasks. In this paper we go one step further and address the problem of object detection using DNNs, that is not only classifying but also precisely localizing objects of various classes. We present a simple and yet powerful formulation of object detection as a regression problem to object bounding box masks. We define a multi-scale inference procedure which is able to produce high-resolution object detections at a low cost by a few network applications. State-of-the-art performance of the approach is shown on Pascal VOC.
-
(2) 基本思想
利用DNN来做目标检测,因为现在的CNN等深度学习在识别上面做的还挺好,但是在目标检测( 目标检测 = 目标识别 +目标定位)上面( CNN在目标检测中没有取得好成绩是本篇论文2013年发表时的情况),好像没有特别突出的结果。本文中作者把目标检测看做一个回归问题,回归目标窗口BoundingBox)的位置,寻找一张图片当中目标类别和目标出现的位置。
2 主要内容
-
1 介绍
-
(1) Deformable Part-based Model(DPM)
1
现阶段主流对象检测方法性能的提高,来源于对象表征以及机器学习模型的提高。在这一时期,取得state-of-the-art的检测系统是DPM(基于部件的变形模型)。DPM是一种图模型,它需要仔细设计对象表征,并结合流体的对象组件分解原理。对于不同的对象类,可以利用具有辨别性的图像学习模型构建高精度的DPMs。
-
(2) DNNs for Objection Detection – 1
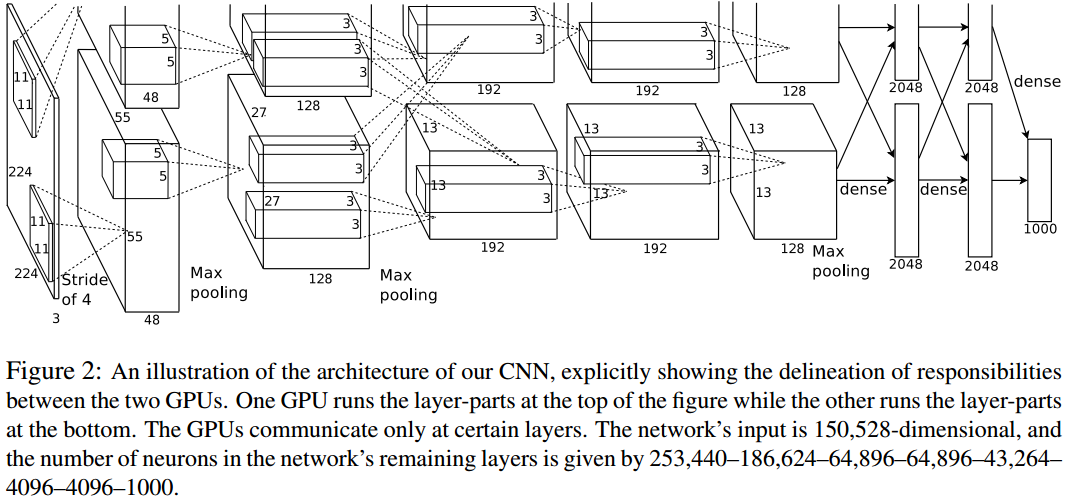
作者在Krizhevsky A, Sutskever I, Hinton G E提出的ImageNet CNN(见下图)基础上构建网络模型。 2
ImageNet CNN共7层,前5层为卷积+Relu层(其中3层还包含Max Pooling),后2层为全连接层。本文将ImageNet CNN的最后一层(Softmax Classifer)替换成了Regression Layer。
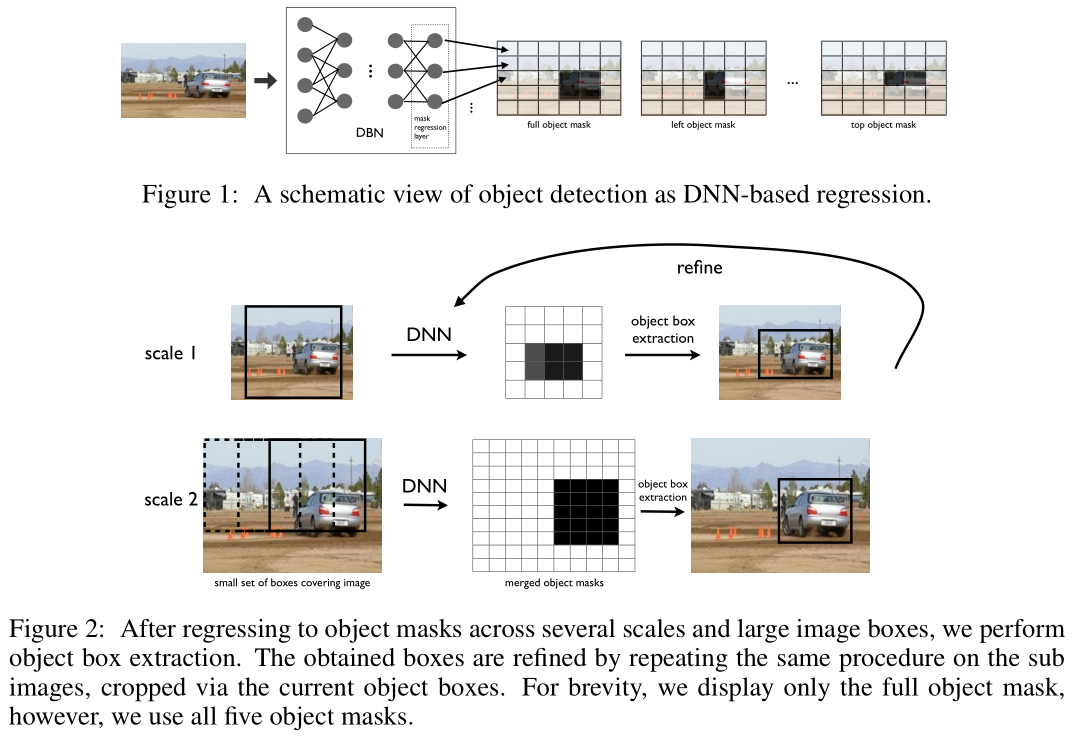
首先,作者制定了一个基于DNN的回归方法,它的输出是对象Bounding Boxes的二值masks;其次,利用一个简单的Bounding Boxes从这些masks中推理提取出检测对象;最后,在全图以及少数修剪后的大图上进行调整,从而提高定位的精度。下图是基于DNNs进行对象检测的原理图(Figure 1)以及微调步骤图(Figure 2)。
2 相关工作
-
(1) 传统的进行对象检测的工作
这些工作中最重要的对象检测研究例子是基于组件的变形模型,脚注[2]的文献是最重要的代表。除此之外,还有基于segments as primitives, shape, Gabor filters, larger HOG filters的Compositional Models。这些方法存在训练比较困难,需要对所学习的程序进行特殊设计以及Inference time需要结合Bottom-up 和 Top-down过程。
神经网络也可以被认为是Compositional Models,比上述模型通用但不易解释。神经网络应用在视觉问题上已经有几十年了,卷积神经网络是最主要的例子。CNN在最近的分类任务中取得了很好的成绩,但是在定位上的应用依然有局限。多层CNN被用于场景解析(一种更加精细的对象检测形式),DNNs被用于医学图像的Segmentation。但是,这两种方法都利用NNs作为超像素或每个像素位置的局部或半局部分类器。然而,作者的方法将整个图片作为输入以及进行位置的回归,因此,会比NNs类方法具有更高的效率。
3 Detection as DNN Regression
-
(1) 论文模型核心设计
模型共7层,前5层为卷积层,后两层是全连接层。与分类模型不同的是该模型的最后一层是Regression Layer,而非Softmax Layer。
Regression Layer生成对象的Binary Mask DNN(x;θ)∈RN ,其中 θ 是模型的参数, N 是对象的像素总数。由于模型的输出维度固定,因此假设模型所预测的输出大小为N=d×d 。对于Resized后,符合模型输入的图片,经模型得到的Binary Masks结果包含一个或多个对象,然后规定属于对象中的Binary Mask的值为1,否则为0。
通过最小化每张图片 x 的Binary Mask与Ground Truth maskm∈[0,1]N 差值的 L2 范式对模型进行训练,Loss Funciton 如下所示:
min θ∑(x,y)∈θ∥(Diag(m)+λI)12(DNN(x;θ)−m)∥22
其中 D 是图片训练集,这些图片j包含Bounding Boxed Objects,而图片中的Bounding Boxed Objects被表征为Binary Masks。
从损失函数的形式可以看出,它具有非凸性,则求解最优值将得不到保证。通常,可以利用Varying Weights对Loss Function进行Regularize。对于绝大多数Objects的尺寸相对于整个图片来说比较小,从而使得模型容易将平凡解(指尺寸比较小的Objects)容易被忽略掉。为了避免这个问题,Loss Function利用参数λ∈R+ 来调整模型中的权重值,模型的输出若为与Ground Truth Mask对应的非零值,则增加输出的Weight。若所选择的参数 λ 比较小,则具有Groundtruth value 0的输出上的误差被惩罚的强度将小于Groundtruth value1的误差,因此即使模型输出的Masks属于Objects的强度比较弱,也能促使模型预测其为非零值。在本论文的实现中,作者设计模型的输入是 225×225 而输出的Binary Mask是 d×d ,其中 d=24 。
4 Precise Object Localization via DNN-generated Masks
-
(1) 概述
论文的这个部分主要对三个具有挑战性的问题进行分析和解决。第一,模型输出的单个Object Mask无法有效地对相互靠近的歧义Objects进行对象检测;第二,由于模型输出大小的限制,所生成的Obinary Mask的尺寸相对于原始图片显得及其小,譬如: 400×400 , d=24 ,那么每个输出对应到原始图片的单元大小大约为 16×16 ,故无法精确地对对象进行定位,而在原始图片更小的时候,难度将更大;第三,受输入是整张图片的影响,尺寸比较小的Objects对Input Neurons的影响很小,从而使得识别变得困难。如下是论文所作的分析和讨论。
-
(2) Multiple Masks for Robust Localization
为了处理图片中多个触摸的对象,我们生成不是一个而是几个Obinary Masks,每个Obinary Mask表示完整对象或其一部分。由于我们的最终目标是产生一个边界框,我们使用一个网络(模型)来预测Object Box Mask和四个额外的网络来预测四个半框,即Bottom, Top, Left 和 Right 半框。定义 mh , h∈{full,bottom,top,left,right} 。这5个预测边界框组成了针对对象的超完备集,这可以减少对象检测的不确定性以及处理一些预测Binary Masks的错误。此外,如果相同类型的两个对象彼此相邻放置,则所产生的5个Binary Masks中至少有2个Binary Masks将不会具有合并的对象,这将允许消除它们的歧义。 这种方法能够检测多个对象。
在训练时,我们需要将Object box转换为这5个Binary Masks。 由于Binary Masks比原始图像小得多,我们需要将Ground Truth Mask缩小到网络输出的大小。定义 T(i,j) 为模型输出值 (i,j) 对应原始图片中小方格的大小,则这个小方框左上角的坐标为 (d1d(i−1),d2d(j−1)) ,大小为 d1d×d2d ,其中 d 是墨西哥呢输出的binary mask,d1,d2 是输入图像的高和宽。那么,在训练时,就可以利用模型的输出 mask(i,j) 预测原始图像中对应的部分 T(i,j) ,从而可以将对象边界框 bb(h) 覆盖。公式如下:
mh(i,j;bb)=area(bb(h)∩T(i,j))area(T(i,j))(1)
其中 bb(full) 对应Ground Truth Object Box,其余的 bb(h) 对应余下的4个Original Box Halves。
注意:作者使用Full Box 以及 Top, Bottom, Left, Right Halves of the Box代表5种不同的覆盖类型。计算的结果 mh(bb) 对应于Ground Truth Box bb ,它在训练时被用来代表模型输出的类型 h 。
应当注意,在这一点上,可以为所有Masks训练一个网络,其输出层将生成它们中的所有5个masks。这样,5个定位器将共享大多数层,因此能够共享特征。这看起来是自然的,因为它们处理相同的对象。 一个更Aggressive的方法是使用相同的定位器为很多不同的类进行定位,这似乎也是可行的。 - (3) Object Localization from DNN Output
为了完成检测过程,我们需要为每个图像估计一组Bounding Boxes。 虽然模型的输出分辨率小于输入图像,但我们可以将模型输出的Binary Masks重新缩放为与输入图像分辨率相同的大小。这个目标是估计Bounding Boxes
bb=(i,j,k,l) 的参数,即在模型输出Mask坐标系下标定出Bounding Boxes bb 的左上角坐标 (i,j) 以及右下角坐标 (k,l) 。
文中作者使用表示每个Bounding Box bb 与Masks具有一致性的分数 S ,并利用具有最高分数的S 来推断Boxes。一个自然做法是测量Bounding Box的哪部分被Mask覆盖。计算分数 S 的公式如下:
S(bb,m)=1area(bb)∑(i,j)m(i,j)area(bb∩T(i,j))(2)
其中 (i,j) 是模型输出的Binary Masks的索引, m=DNN(x) 是模型输出的Binary Masks。作者将 S(bb,m) 扩展到所有的5中Mask类型,最后得到的分数 S(bb) 如下:
S(bb)=∑h∈halves(S(bb(h),mh)−S(bb(h¯),mh))(3)
其中 halves={full,bottom,top,left,right} , h 是halves 中的一个, h¯ 被定义为与 h 相反的一半。例如,被检测对象的Top Mask应该被模型输出的Top Mask完全覆盖,而不是完全由Bottom Mosk覆盖。对于h=full ,我们用Bounding Box bb 周围的矩形区域表示,如果Full Mask延伸到Bounding Box bb 之外,则其分数 S(bb) 将被惩罚。在上述求和公式中,如果Bounding Box bb 与所有5个Binary Masks一致,则被检测对象的得分将很大。由以上的公式可以极大地搜索出可能存在的Bounding Boxes。
作者做了这样的考虑,他让Bounding Boxes的平均尺寸等于图片平均尺寸的 [0.1,...,0.9] (即长宽等比压缩),同时,通过训练数据中的Objects的Ground Truth Boxes进行K-Mean聚类估计出10个不同的比率,故而可以得到 9×10=90 个Boxes。接下来,作者对每一个得到的Box在图片中以 stride=5pixels 在图片中进行滑动。
关于计算复杂性的描述(理解得不太准确,因此贴原文): Note that the score from Eq. (3) can be efficiently computed using 4 operations after the integral image of the mask m has been computed. The exact number of operations is 5 (2 × #pixels + 20 × #boxes), where the first term measures the complexity of the integral mask computation while the second accounts for box score computation.
最后,作者利用两种类型的Filtering产生最后的检测集合。第1个Filtering筛选出Eq. (2)计算出的分数中比较高的Boxes,比如 S(bb,m)>0.5 。第2个Filtering是一个DNN Classifier 3,它可以对第一步选出来的Boxes进行更细致的剪切,从而获得检测出所感兴趣的对象类,即 The class of the Current Detector。然后,作者应用引用1( Object detection with discriminatively trained part-based models)中的Non-maximun Suppression得到最终的结果。 -
(4) Multi-scale Refinement of DNN Localizer
网络输出的Binary Masks分辨率不足的问题以两种方式解决:(i)将DNN Localizer应用于若干Scales和几个大Sub-Windows; (ii)通过在顶部推断的Bounding Boxes上应用DNN Localizer来改进检测(参见 Fig. 2)。
使用各种Scales的大窗口,我们生成几个Masks,并将它们合并为更高分辨率的Masks,每个Scale一个。 合适Scales的范围取决于图像的Resolution和Localizer的Receptive Field的大小 - 我们希望图像被以更高分辨率操作的网络输出覆盖,同时我们希望每个对象落在至少一个窗口内并且这些窗口的数量比较少。
为了实现上述目标,我们使用三个Scales:完整图像和两个其他Scales,使得在给定Scale下的窗口的尺寸是先前给定Scale窗口尺寸的一半。 我们用每个Scale的窗口覆盖图像,使得这些窗口具有小的重叠 - 其面积的20%。 这些窗口在数量上相对较小并且在几个尺度上覆盖图像。 最重要的是,最小尺度的窗口允许以更高的分辨率定位。
在推理时,我们在所有窗口上应用DNN。 注意,它与滑动窗口方法非常不同,因为我们需要评估每个图像的少量窗口,通常小于40。 在每个Scale下生成的Object Masks通过Maximum Operation合并。 这给了我们三个图像大小的Masks,每个”Looking” at 不同大小的对象。 对于每个Scale,我们应用来自(第3节)的Bounding Boxes推理以得到一组检测结果。 在我们的实施中,我们在每个Scale上选取前5个Detections,即:在3个Scales上总共有15个Detections。
为了进一步改进定位,第二阶段我们对结果进行精细化调整,用到的方法是DNN回归。 DNN Localizer被应用于由初始检测阶段定义的窗口上,其上的15个Bounding Boxes都被放大了1.2倍,并应用于模型中。所以,对较高分辨率的Binary Masks应用定位器,可以显著提高检测的精度。如下的Algorithm 1概述了完整的算法:
4 DNN Training and Evaluation
- 略

脚注:
- Felzenszwalb P F, Girshick R B, Mcallester D, et al. Object detection with discriminatively trained part-based models.[J]. IEEE Transactions on Software Engineering, 2010, 32(9):1627-45. ↩
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2):2012. ↩
- Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012, 25(2):2012. ↩

















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









