







Park变换
Park变换的本质是静止坐标系αβ乘以一个旋转矩阵,从而得到dq坐标系,输入的i_α和i_β经过Park变换得到i_d和i_q(交直变换)。
数学公式
跟着转子旋转的“d-q”坐标系把cos,sin正余弦信号转化线性的了,theta角度是由位置传感器得到的已知变量。
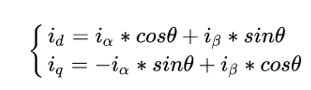
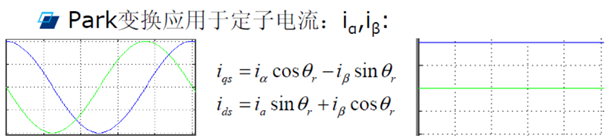
simulink仿真
TI的实现
简单的两句计算,cos和sin(theta)是外部计算传入参数。对于三角函数,TI有自己的库去计算。而cos和sin(theta)不止只有在park中使用,其他地方也会使用,在这函数中再计算一次,未免多花时间了。
typedef struct {
_iq Alpha; // Input: stationary d-axis stator variable
_iq Beta; // Input: stationary q-axis stator variable
_iq Angle; // Input: rotating angle (pu)
_iq Ds; // Output: rotating d-axis stator variable
_iq Qs; // Output: rotating q-axis stator variable
_iq Sine;
_iq Cosine;
} PARK;
/*------------------------------------------------------------------------------
PARK Transformation Macro Definition
------------------------------------------------------------------------------*/
#define PARK_MACRO(v)
v.Ds = _IQmpy(v.Alpha,v.Cosine) + _IQmpy(v.Beta,v.Sine);
v.Qs = _IQmpy(v.Beta,v.Cosine) - _IQmpy(v.Alpha,v.Sine);
ST的实现
ST的代码写很“规矩”,一步一步的。很多限幅检测。在对theta求角度的查表法也绕了一下。解决浮点计算,统一后,全使用int型的。
typedef struct
{
int16_t hCos;
int16_t hSin;
} Trig_Components;
typedef struct
{
int16_t alpha;
int16_t beta;
} alphabeta_t;
typedef struct
{
int16_t q;
int16_t d;
} qd_t;
__weak qd_t MCM_Park( alphabeta_t Input, int16_t Theta )
{
qd_t Output;
int32_t d_tmp_1, d_tmp_2, q_tmp_1, q_tmp_2;
Trig_Components Local_Vector_Components;
int32_t wqd_tmp;
int16_t hqd_tmp;
// 传入theta 查表计算得到 cos和sin的值
Local_Vector_Components = MCM_Trig_Functions( Theta );
// 不保证溢出,先计算一次,然后各种限幅判断,最后再做IQ的赋值
/*No overflow guaranteed*/
// 计算 alpha*cos(theta)
q_tmp_1 = Input.alpha * ( int32_t )Local_Vector_Components.hCos;
/*No overflow guaranteed*/
// 计算 beta*sin(theta)
q_tmp_2 = Input.beta * ( int32_t )Local_Vector_Components.hSin;
/*Iq component in Q1.15 Format */
#ifdef FULL_MISRA_C_COMPLIANCY
wqd_tmp = ( q_tmp_1 - q_tmp_2 ) / 32768;
#else
/* WARNING: the below instruction is not MISRA compliant, user should verify
that Cortex-M3 assembly instruction ASR (arithmetic shift right) is used by
the compiler to perform the shift (instead of LSR logical shift right) */
// IQ的计算,计算完了,去各种限幅。 右移15是sin和cos/32768得到真正的值,又回到16位以内
wqd_tmp = ( q_tmp_1 - q_tmp_2 ) >> 15;
#endif
/* Check saturation of Iq */
if ( wqd_tmp > INT16_MAX )
hqd_tmp = INT16_MAX;
else if ( wqd_tmp < ( -32768 ) )
hqd_tmp = ( -32768 );
else
hqd_tmp = ( int16_t )( wqd_tmp );
Output.q = hqd_tmp;
if ( Output.q == ( int16_t )( -32768 ) )
{
Output.q = -32767;
}
/*No overflow guaranteed*/
d_tmp_1 = Input.alpha * ( int32_t )Local_Vector_Components.hSin;
/*No overflow guaranteed*/
d_tmp_2 = Input.beta * ( int32_t )Local_Vector_Components.hCos;
/*Id component in Q1.15 Format */
#ifdef FULL_MISRA_C_COMPLIANCY
wqd_tmp = ( d_tmp_1 + d_tmp_2 ) / 32768;
#else
/* WARNING: the below instruction is not MISRA compliant, user should verify
that Cortex-M3 assembly instruction ASR (arithmetic shift right) is used by
the compiler to perform the shift (instead of LSR logical shift right) */
wqd_tmp = ( d_tmp_1 + d_tmp_2 ) >> 15;
#endif
/* Check saturation of Id */
if ( wqd_tmp > INT16_MAX )
{
hqd_tmp = INT16_MAX;
}
else if ( wqd_tmp < ( -32768 ) )
{
hqd_tmp = ( -32768 );
}
else
{
hqd_tmp = ( int16_t )( wqd_tmp );
}
Output.d = hqd_tmp;
if ( Output.d == ( int16_t )( -32768 ) )
{
Output.d = -32767;
}
return ( Output );
}
















 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









