







使用NEU-DET数据集进行缺陷检测的YOLOv8改进模型应用详解
在现代工业生产过程中,质量控制是至关重要的一个环节。随着机器视觉技术和人工智能算法的发展,基于深度学习的方法已经成为自动化缺陷检测的重要工具。本篇将介绍一种基于NEU-DET数据集,利用YOLOv8及其改进版本(包含坐标注意力机制和Swin Transformer)进行缺陷检测的应用开发过程。我们将详细探讨从数据准备到模型训练,再到最终部署的全过程。

一、项目背景与意义
随着制造业向着智能化、自动化的方向发展,传统的人工目视检查方式已逐渐不能满足高效、精准的质量控制需求。机器视觉技术结合深度学习算法,特别是目标检测领域的突破,为缺陷检测提供了一种全新的解决方案。YOLO(You Only Look Once)系列算法以其快速且准确的特点在这一领域表现出色。而最新版本YOLOv8不仅继承了前几代的优势,还在多个方面进行了优化,使其更加适合于工业场景下的缺陷检测任务。
NEU-DET数据集是由东北大学(Northeastern University)发布的一个专注于表面缺陷检测的数据集。它包含了多种类型的材料表面缺陷图片,非常适合用来评估和训练用于缺陷检测的深度学习模型。本项目旨在通过结合YOLOv8与最新的改进技术,如坐标注意力机制(Coordinate Attention)和Swin Transformer,来提高缺陷检测的准确性和鲁棒性。
二、技术原理简介
-
YOLOv8: 最新一代的YOLO模型,相比之前的版本具有更快的速度和更高的精度。它采用了更先进的骨干网络结构,并且在训练策略上做了许多创新性的尝试,使得模型能够在保持轻量化的同时达到非常好的性能表现。
-
坐标注意力机制(Coordinate Attention): 这是一种特别设计来增强卷积神经网络对空间信息敏感度的技术。通过显式地建模不同通道之间的关系,坐标注意力机制可以帮助模型更好地捕捉到图像中不同位置的信息差异,这对于识别细小或形状复杂的缺陷尤为重要。
-
Swin Transformer: 结合了Transformer架构与局部窗口注意力机制,Swin Transformer能够有效地处理图像数据,尤其擅长于长距离依赖关系的学习。当应用于缺陷检测时,这种特性有助于模型理解更大范围内的上下文信息,从而提高检测准确性。

三、数据准备
首先,我们需要准备好NEU-DET数据集。该数据集已经按照训练集、验证集和测试集进行了划分,可以直接下载使用。每个类别都有大量的样本,涵盖了不同类型和程度的表面缺陷,这为我们的模型训练提供了丰富的学习材料。
接下来,为了适应YOLOv8框架的要求,我们需要对原始图像进行一些预处理操作,比如调整大小、归一化等。此外,还需生成相应的标注文件,这些文件包含了每张图片中所有缺陷的位置信息(通常是边界框坐标加上类别标签)。整个过程可以借助一些开源工具或脚本来简化工作量。
四、模型构建与训练
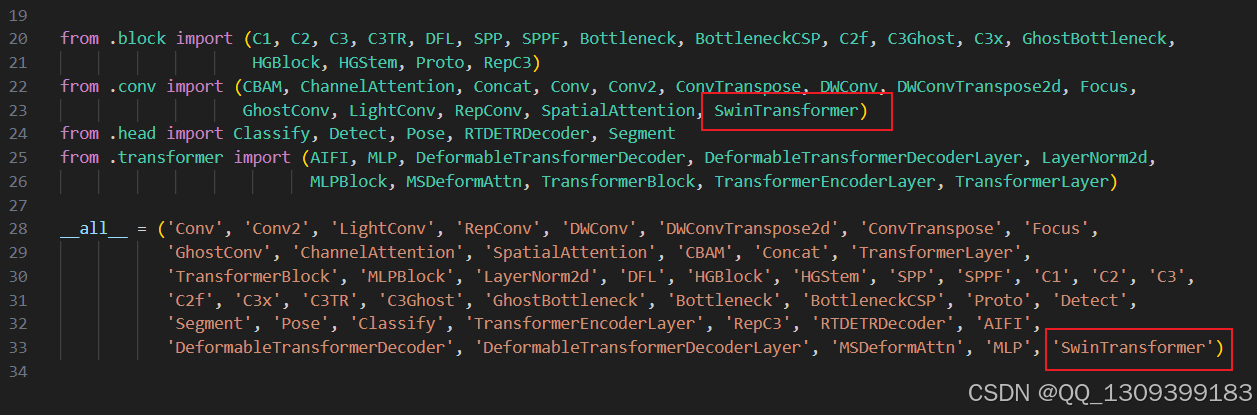
在模型构建阶段,我们将基于官方发布的YOLOv8代码库进行二次开发,加入坐标注意力机制和Swin Transformer模块。这部分工作主要涉及以下几个步骤:
- 导入必要的库 - 包括PyTorch、Ultralytics提供的YOLOv8相关库以及其他可能用到的辅助库。
- 定义改进的模型结构 - 根据需要定制化修改原有模型架构,引入新的注意力机制与Transformer层。
- 准备数据加载器 - 利用PyTorch的数据加载工具创建训练集与验证集的数据迭代器。
- 设定超参数 - 包括学习率、批次大小、训练周期数等关键参数的选择。
- 开始训练 - 执行训练循环,定期保存模型权重并记录训练过程中各项指标的变化情况。
训练过程中,建议密切关注损失函数曲线以及在验证集上的表现,适时调整超参数以避免过拟合或欠拟合现象的发生。
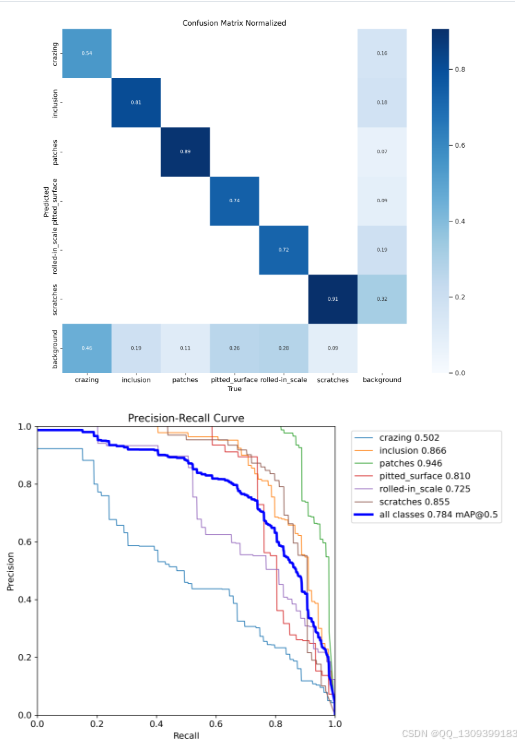
五、性能评估与调优
完成初步训练后,下一步就是对模型进行全面的性能评估。这包括但不限于计算精确度(Precision)、召回率(Recall)、F1分数(F1 Score)等标准评价指标。同时,还需要针对实际应用场景中的特定要求进行额外考量,比如漏检率、误报率等。
如果发现模型存在不足之处,则应考虑采取进一步的调优措施。常见的方法有增加正则化项防止过拟合、采用更复杂的数据增强策略提升泛化能力、或是探索不同的损失函数形式等。此外,也可以尝试集成学习(Ensemble Learning)技术,即组合多个独立训练得到的模型共同做出决策,以此来进一步提高系统的整体性能。
六、用户界面设计与实现
为了让最终用户能够方便快捷地使用我们开发出来的缺陷检测系统,我们决定采用Streamlit这一强大的Python Web应用框架来构建用户友好的交互界面。通过简单的几行代码,就可以快速搭建出一个包含文件上传、结果显示等功能齐全的应用程序。
例如,我们可以为用户提供一个简单的网页界面,其中包含一个文件选择器让用户上传待检测的图片或视频,然后在后台调用训练好的YOLOv8模型进行处理,并将结果显示在网页上。这样的设计既简化了用户的操作流程,又保证了良好的用户体验。
七、部署与维护
最后一步是将整个应用打包并通过Docker容器化技术进行部署。Docker允许我们将所有的依赖项和环境配置封装在一个独立的容器内,这样无论是在本地测试还是迁移到云端服务器上运行都非常方便快捷。
部署完成后,还应该定期检查系统的运行状况,及时修复可能出现的问题,并根据用户反馈不断迭代升级产品功能。随着技术的发展,未来的版本或许还会引入更多前沿的研究成果,以持续提升系统的性能表现。
通过以上几个阶段的工作,我们成功构建了一个基于YOLOv8及其改进版的高性能缺陷检测系统。该系统不仅具备较高的检测准确率,而且拥有良好的可扩展性和易用性,能够很好地满足工业界对于自动化质量控制的需求。希望这份详细的开发指南能够为其他从事类似研究工作的同行们提供一定的参考价值。
代码
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
nn.init.normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
# print(attn.dtype, v.dtype)
try:
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
except:
# print(attn.dtype, v.dtype)
x = (attn.half() @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformer(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(SwinTransformer, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.m(self.cv1(x))
y2 = self.cv2(x)
return self.cv3(torch.cat((y1, y2), dim=1))
class SwinTransformerB(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(Swin_Transformer_B, self).__init__()
c_ = int(c2) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
x1 = self.cv1(x)
y1 = self.m(x1)
y2 = self.cv2(x1)
return self.cv3(torch.cat((y1, y2), dim=1))
class SwinTransformerC(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(Swin_Transformer_C, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 1, 1)
self.cv4 = Conv(2 * c_, c2, 1, 1)
num_heads = c_ // 32
self.m = SwinTransformerBlock(c_, c_, num_heads, n)
# self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(torch.cat((y1, y2), dim=1))
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.SiLU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
B, H, W, C = x.shape
assert H % window_size == 0, 'feature map h and w can not divide by window size'
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class SwinTransformerLayer(nn.Module):
def __init__(self, dim, num_heads, window_size=8, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.SiLU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
# if min(self.input_resolution) <= self.window_size:
# # if window size is larger than input resolution, we don't partition windows
# self.shift_size = 0
# self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=(self.window_size, self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def create_mask(self, H, W):
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
return attn_mask
def forward(self, x):
# reshape x[b c h w] to x[b l c]
_, _, H_, W_ = x.shape
Padding = False
if min(H_, W_) < self.window_size or H_ % self.window_size != 0 or W_ % self.window_size != 0:
Padding = True
# print(f'img_size {min(H_, W_)} is less than (or not divided by) window_size {self.window_size}, Padding.')
pad_r = (self.window_size - W_ % self.window_size) % self.window_size
pad_b = (self.window_size - H_ % self.window_size) % self.window_size
x = F.pad(x, (0, pad_r, 0, pad_b))
# print('2', x.shape)
B, C, H, W = x.shape
L = H * W
x = x.permute(0, 2, 3, 1).contiguous().view(B, L, C) # b, L, c
# create mask from init to forward
if self.shift_size > 0:
attn_mask = self.create_mask(H, W).to(x.device)
else:
attn_mask = None
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.permute(0, 2, 1).contiguous().view(-1, C, H, W) # b c h w
if Padding:
x = x[:, :, :H_, :W_] # reverse padding
return x
class SwinTransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=8):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i in
range(num_layers)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x


















 7453
7453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









