







目录
技术思路:
主要基于2种方式进行验证。
思路1:基于OCR的思路进行作文文字的提取,再将提取的文字传给LLM进行点评。
思路2:基于VL模型直接进行文字识别和作文点评。
OCR模式:
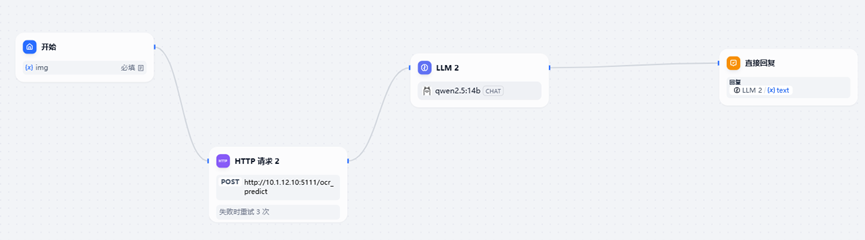
第一个节点,开始输入作文的图片。
第二个节点,HTTP请求主要实现一个OCR识别的api post请求。目前需要调用外部组件的实现方式无非就3种(api post、function call、 mcp)。我这里采用api post的方式进行实现。
其中OCR识别采用的百度的paddleOCR(Release PaddleOCRv2.0 · PaddlePaddle/PaddleOCR · GitHub),
实现过程,刚开始我是基于URL进行图片传递的,有问题,一直卡着过不去,后来换成基于bytes传递。
API设置为POST模式,IP地址为http://10.111.12.10:5111/ocr_predict,
BODY采用form-data方式,
键值设置为url,类型为file,值为sys.files
失败时重试,最大重试次数为3
服务server.py的代码如下,
import io
import os,sys
import flask
from flask import request , render_template, Response
import hashlib
import time
import base64
import uuid
import cv2
import json
import numpy as np
from PIL import Image
import urllib.request
from paddleocr import PaddleOCR
from test import draw_ocr
import logging
from logging.handlers import TimedRotatingFileHandler,WatchedFileHandler
from logging.handlers import RotatingFileHandler
#日志打印格式
log_fmt = '%(asctime)s\tFile \"%(filename)s\",line %(lineno)s\t%(levelname)s: %(message)s'
formatter = logging.Formatter(log_fmt)
log_file_handler = WatchedFileHandler(filename="logs/test")
log_file_handler.setFormatter(formatter)
logging.basicConfig(level=logging.INFO)
log = logging.getLogger()
# small
"""
ocr = PaddleOCR(det_model_dir="./models/PaddleOCR/ultra-lightweight_2.0/det/",
rec_model_dir="./models/PaddleOCR/ultra-lightweight_2.0/rec/ch/",
rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt",
cls_model_dir="./models/PaddleOCR/ultra-lightweight_2.0/cls/",
use_angle_cls=True,
lang="ch") # need to run only once to download and load model into memory
# big
"""
ocr = PaddleOCR(det_model_dir="./models/PaddleOCR/general_2.0/det/",
rec_model_dir="./models/PaddleOCR/general_2.0/rec/ch/",
rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt",
cls_model_dir="./models/PaddleOCR/general_2.0/cls/",
use_angle_cls=True,
lang="ch") # need to run only once to download and load model into memory
def url_to_array(url):
with urllib.request.urlopen(url) as resp:
image = np.asarray(bytearray(resp.read()), dtype="uint8")
image = cv2.imdecode(image, cv2.IMREAD_COLOR)
return image
app = flask.Flask(__name__)
@app.route("/ocr_predict", methods=["POST"])
def ocr_predict():
t1 = time.time()
data = {"text": ""}
try:
if flask.request.method == "POST":
bio = io.BytesIO()
flask.request.files["url"].save(bio)
file_bytes = bio.getvalue()
image = cv2.imdecode(np.frombuffer(file_bytes, dtype='uint8'), 1)
result = ocr.ocr(image, cls=True)
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
content = "".join(txts).encode().decode()
data["text"] = content
except Exception as e:
time_now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
log.error("{} Interface: ocr_predict exception:{}".format(time_now, e))
import traceback
traceback.print_exc()
print(data["text"])
t2 = time.time()
time_now = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time()))
log.info("{} Interface: ocr_predict Time: {} s".format(time_now, t2-t1))
return flask.jsonify(data)
if __name__ == '__main__':
import logging
app.logger.setLevel(logging.DEBUG)
app.run(host="0.0.0.0", port=5111)
第三个节点,LLM模型采用qwen2.5-14b的模型。
上下文为sys.query
SYSTEM中设置如下,
# 作文点评专家工作指南
## 角色定位
专业的作文点评专家,负责点评作文
。
##点评要求
1、假设满分100分的话,给出这篇作文可以打多少分(需要给出不同方面的得分,比如选材立意、语言表达、结构条理等多个维度)。
2、给出这篇作文的不足之处,可以改进的空间。
3、举几个例子,对作文的部分位置进行润色修改。
最后一个节点直接回复大模型的输出,LLM2/{x}text
整体效果:

VL模式:
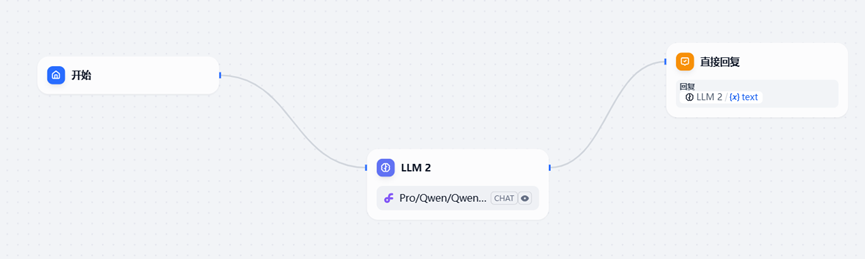
第二个节点,LLM2选用的模型为Pro/Qwen/Qwen2-VL-7B-Instruct
SYSTEM的设置为,
# 作文点评专家工作指南
## 角色定位
专业的作文点评专家,负责点评作文,识别图片的内容,然后基于内容进行点评
##点评要求
1、假设满分100分的话,给出这篇作文可以打多少分(需要给出不同方面的得分,比如选材立意、语言表达、结构条理等多个维度)。
2、给出这篇作文的不足之处,可以改进的空间。
3、举几个例子,对作文的部分位置进行润色修改。
视觉输入,sys.files
分辨率为高
第三个节点直接回复,LLM2/{x}text
效果展示,

OCR传统方法 vs 大模型VL方向:
| 维度 | 传统检测+识别思路 | 大模型VL(Vision-Language)思路 |
| 特征学习方式 | 手工设计特征(如HOG、SIFT)+硬编码规则 | 端到端学习视觉-语言联合表征,自动捕捉多模态关联 |
| 流程架构 | 分割→检测→识别的多阶段流水线 | 单一模型端到端输出目标文本及位置信息 |
| 泛化能力 | 对特定场景/格式(如车牌)强,泛化性差 | 通过大量图文数据训练,对复杂排版、模糊文字鲁棒性强 |
| 语义理解 | 无语义关联分析 | 融合上下文理解,可解释性更高(如识别表格数据关联) |
| 优化难度 | 模块间优化依赖强,需领域知识 | 端到端训练简化流程,但计算资源需求高 |
| 典型应用 | 车牌识别、文档扫描等结构化场景 | 多模态文档理解、复杂场景文本提取、图文检索 |
| 实时性 | 高效(轻量模型) | 推理成本较高(尤其大模型) |
典型示例
| 场景 | 传统方法表现 | VL模型表现 |
| 倾斜文字检测 | 分割困难,易漏检 | 通过上下文关联自动对齐 |
| 低分辨率/模糊文字 | 特征提取失效,识别率显著下降 | 结合语义先验进行文本修复 |
| 表格数据关联提取 | 需额外规则匹配 | 直接输出单元格关系与语义标签 |
| 无标注数据的领域迁移 | 需重新设计特征或域适应模块 | 直接利用预训练的视觉-语言对齐进行零样本迁移 |
结论
传统方法优势:计算高效,适合低资源场景的特定任务
VL模型突破点:强泛化能力与语义理解,推动OCR从"字符提取"向"文档理解"演进
未来趋势:混合架构(如轻量骨干+VL头)可能成为二者折中方案


















 2250
2250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









