







整体检测思想:
(1)Pico 采用滑窗策略,图像大小维持不变,通过窗口不断移动与放大,实现对图像上所有区域的检测。
(2)针对每一个窗口,使其通过所有树,每通过一棵树会得到一个结果,这个结果不断递加,当其小于阈值时,则拒绝该窗口,判定其非人脸。
(3)若该窗口通过了所有树,其结果大于阈值,则接受该窗口,判定其为人脸,该结果为其置信度。
(4)检测完所有窗口后做一次聚类,假如两个区域的交集比上并集大于0.3,则判定该为同一人脸,结果取其坐标与大小的均值,置信度选择累加。
基于回归的决策树:
其中,pico特征的binary test定义如下,其中,I为图像,l1和l2分别代表图像I中2个不同的位置。
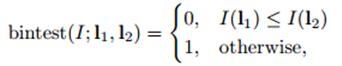
其中,训练数据如下所示,I为图像,v代表图像的标签,w代表权重,s表示第s个图像
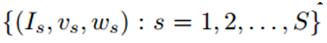
然后,训练的过程,实际就是最小化下式子的加权均值平方误差(weighted mean squared error)
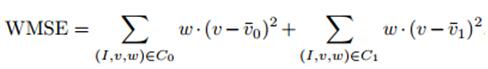
二值分类器的整体决策树:
为了从训练样本中产生K个级联的决策树,需要进行以下的步骤:
(1)首先初始化每个图像Is的权重值Ws,其中,P为正样本的个数,N为负样本的个数,Cs为类别

(2)匹配一个决策树Tk,计算其WMSE,然后按照下式跟新其权值,并重新对权值做归一化操作。
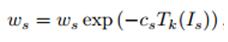
(3)输出决策树Tk
二值检测器结果合并:
如果Iou大于30%,则进行相应的合并,即算2个框的位置和尺度的均值。
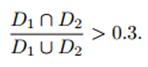
训练过程:
数据集:AFLW&Visage Technologies ( http://www.visagetechnologies.com/)
正样本:20000个原始正样本,经过scale和crop后,每个原始样本产生15个,最终产生300000个正样本
负样本:300000
训练时间:30小时(4核16G的电脑)
训练中cascade内存消耗:<200kb
实验结果:

references:
[1] https://github.com/nenadmarkus/pico
[2] Markuš N, Frljak M, Pandžić I S, et al.Object detection with pixel intensity comparisons organized in decisiontrees[J]. arXiv preprint arXiv:1305.4537, 2013.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









