







1、Background
尽管深度学习模型已经成为医学图像分割的主流方法,但这些模型通常难以泛化到新的、未见过的分割任务,尤其是那些涉及新解剖结构、图像模态或标签的任务。这导致了一个问题,即每当出现新的分割任务时,研究人员都需要从头开始训练或微调模型,这不仅耗时,而且对于缺乏资源和专业知识的临床研究人员来说是一个重大障碍。
为了解决这个问题,提出了UniverSeg方法,能够在不需要额外训练的情况下解决未见过的医学分割任务。UniverSeg利用一种新的CrossBlock机制,通过查询图像和定义新分割任务的示例集(即图像-标签对)来生成准确的分割图。这种方法的关键优势在于它的泛化能力,这得益于作者们收集和标准化的大量多样化的医学分割数据集,称为MegaMedical。这个数据集包含了超过22,000个扫描,涵盖了多种解剖结构和成像模态,用于训练UniverSeg以适应不同的任务。
作者们强调, UniverSeg的目标是构建一个能够在多种任务上表现良好的单一通用医学图像分割模型,而不需要针对每个新任务进行重新训练 。这在医学研究中尤其有价值,因为新的分割任务经常由临床研究人员定义,他们可能没有资源或专业知识来训练新的模型。通过这种方式,UniverSeg旨在加速科学发展,降低进入门槛,使更多的研究人员能够利用深度学习技术进行医学图像分析。
2、Method
UniverSeg 方法的核心是学习一个通用的医学图像分割模型,该模型能够在不需要额外训练的情况下处理各种分割任务,包括在训练时未见过的那些任务。
UniverSeg 的设计包括以下几个关键组成部分:
- 模型结构:UniverSeg 使用一个全卷积神经网络(FCN),该网络采用了新提出的 CrossBlock 模块。CrossBlock 模块能够处理查询图像和支持集(包含图像和标签对)之间的信息交互。
- CrossBlock:这是 UniverSeg 中的一个创新组件,它通过交叉卷积层(CrossConv)来实现查询特征图与支持特征集之间的交互。CrossBlock 能够更新查询表示和支持集,以便于在网络的每一步中进行信息传递。
- 网络架构:UniverSeg 的网络架构采用了编码器-解码器结构,类似于流行的 UNet 架构。网络输入包括查询图像和支持集,输出为分割预测图。编码器路径中的每个级别都包含一个 CrossBlock 后跟空间下采样操作,而解码器路径中的每个级别则包括上采样、与编码器路径中的相应尺寸表示进行连接,然后是一个 CrossBlock。
- 训练策略:UniverSeg 的训练涉及大量的数据增强技术,以增加训练任务的多样性和有效样本数量。这些增强技术包括任务内增强(如图像的仿射变换、弹性变形等)和任务增强(如边缘检测、水平翻转等)。
- 推理过程:在给定查询图像的情况下,UniverSeg 能够根据支持集进行分割预测。为了减少对特定支持集的依赖,UniverSeg 通过集成多个独立采样的支持集的预测来提高预测质量。
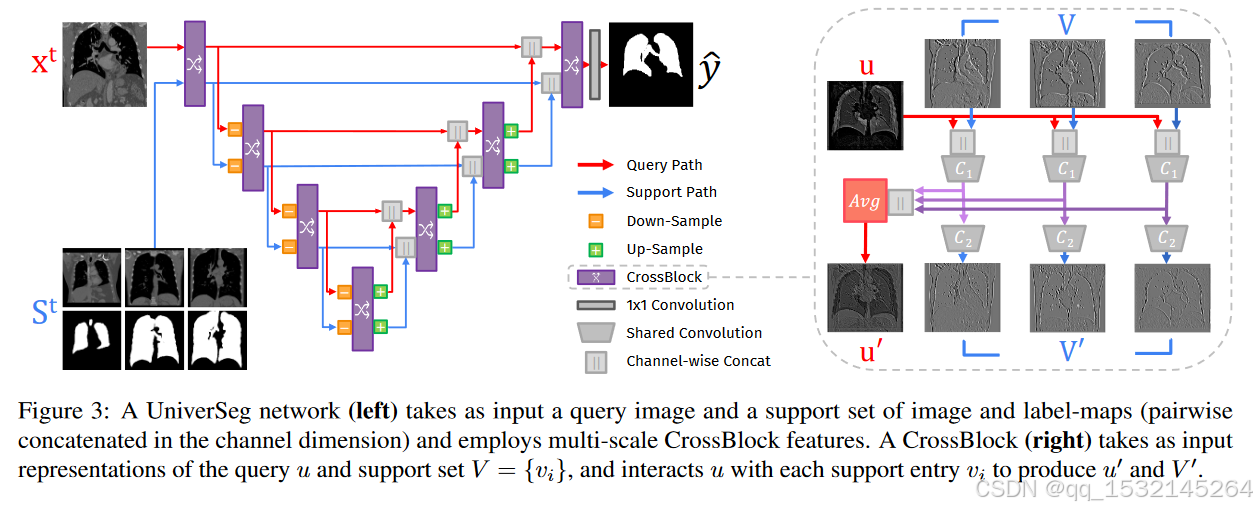
UniverSeg 方法的创新之处在于它能够适应新的分割任务而无需重新训练。这是通过使用 CrossBlock 模块实现的,该模块允许模型从支持集中的示例中学习,并将其知识迁移到新的查询图像上 。这种方法特别适用于医学图像分析领域,因为新的分割任务经常由临床研究人员定义,他们可能没有资源或专业知识来训练新的神经网络模型。
此外,UniverSeg 在训练时使用了大量数据增强技术,这有助于模型学习到更加鲁棒的特征表示,从而提高其在未见任务上的性能。在推理时,通过集成多个支持集的预测,UniverSeg 能够减少对单个支持集样本的依赖,进一步提高分割的准确性和鲁棒性。
pseudo-code
# 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
# 定义CrossBlock模块
class CrossBlock(nn.Module):
def __init__(self, input_channels, output_channels):
super(CrossBlock, self).__init__()
self.cross_conv = nn.Conv2d(input_channels, output_channels, kernel_size=1)
self.activation = nn.LeakyReLU()
def forward(self, u, V):
# 交叉卷积操作
z = [self.cross_conv(torch.cat((u, v), dim=1)) for v in V]
# 更新查询和支持集表示
u_prime = self.activation(torch.mean(torch.stack(z), dim=0))
V_prime = [self.activation(self.cross_conv(z[i])) for i in range(len(z))]
return u_prime, V_prime
# 定义UniverSeg网络
class UniverSeg(nn.Module):
def __init__(self):
super(UniverSeg, self).__init__()
self.encoder = ... # 编码器网络
self.decoder = ... # 解码器网络
self.cross_blocks = nn.ModuleList([CrossBlock(...) for _ in range(num_scales)])
def forward(self, query_image, support_set):
# 通过编码器和CrossBlock模块处理查询图像和支持集
for block in self.cross_blocks:
query_image, support_set = block(query_image, support_set)
# 通过解码器生成分割图
segmentation_map = self.decoder(query_image)
return segmentation_map
# 训练UniverSeg模型
def train_UniverSeg(model, optimizer, criterion, train_loader):
model.train()
for query_image, support_set, labels in train_loader:
optimizer.zero_grad()
outputs = model(query_image, support_set)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 推理过程
def infer(UniverSeg_model, query_image, support_set):
with torch.no_grad():
predicted_segmentation = UniverSeg_model(query_image, support_set)
return predicted_segmentation
# 主程序
if __name__ == "__main__":
# 初始化模型、优化器和损失函数
model = UniverSeg()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
# 训练模型
for epoch in range(num_epochs):
train_UniverSeg(model, optimizer, criterion, train_loader)
# 推理
support_set = ... # 为新任务准备的支持集
query_image = ... # 新任务的查询图像
predicted_segmentation = infer(model, query_image, support_set)
3、Experiments
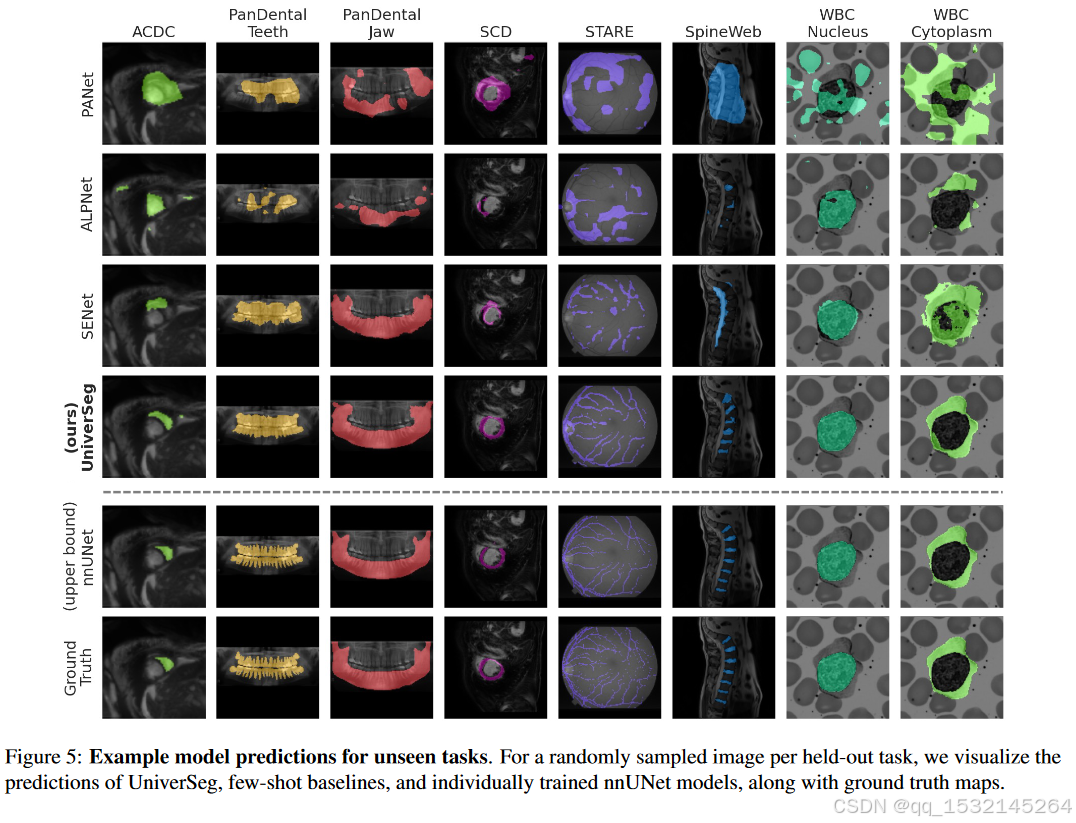
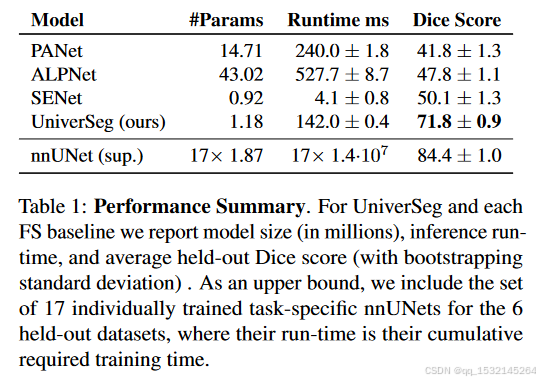
4、Conclusion
UniverSeg是一个用于医学图像分割的通用方法,它能够学习一个单一的、不依赖于特定任务的模型。这个模型能够在没有额外训练的情况下,通过给定的查询图像和支持集(少量标记的图像-标签对)来适应新的分割任务。

















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









