







一次性获取完整回答:智谱清言 API 高效调用指南
1. 介绍
智谱清言 API 是一个强大的 AI 语言模型接口,支持对话生成、搜索增强等功能。API 提供两种输出方式:
- 流式输出(stream=True):逐字返回内容,适用于打字机效果或实时交互。
- 非流式输出(stream=False):一次性返回完整回答,更加直观。
本文将重点讲解如何一次性获取完整回答,避免逐字返回的问题,并提供代码示例与常见错误解决方案。
2. 获取 API Key
- 访问 智谱清言 API 控制台。
- 点击 立即体验,在右上角找到 查看代码 按钮,获取 API Key。
- 如果无法看到示例代码,尝试 最大化窗口。
(最小化页面)
(最大化页面)
👉 直接访问 API Key 管理页面 申请新 Key,并查看最近的使用记录。
3. 安装 SDK
在使用 API 之前,需要安装 zhipuai Python SDK:
pip install zhipuai
4. 代码示例
官方提供的代码如下:
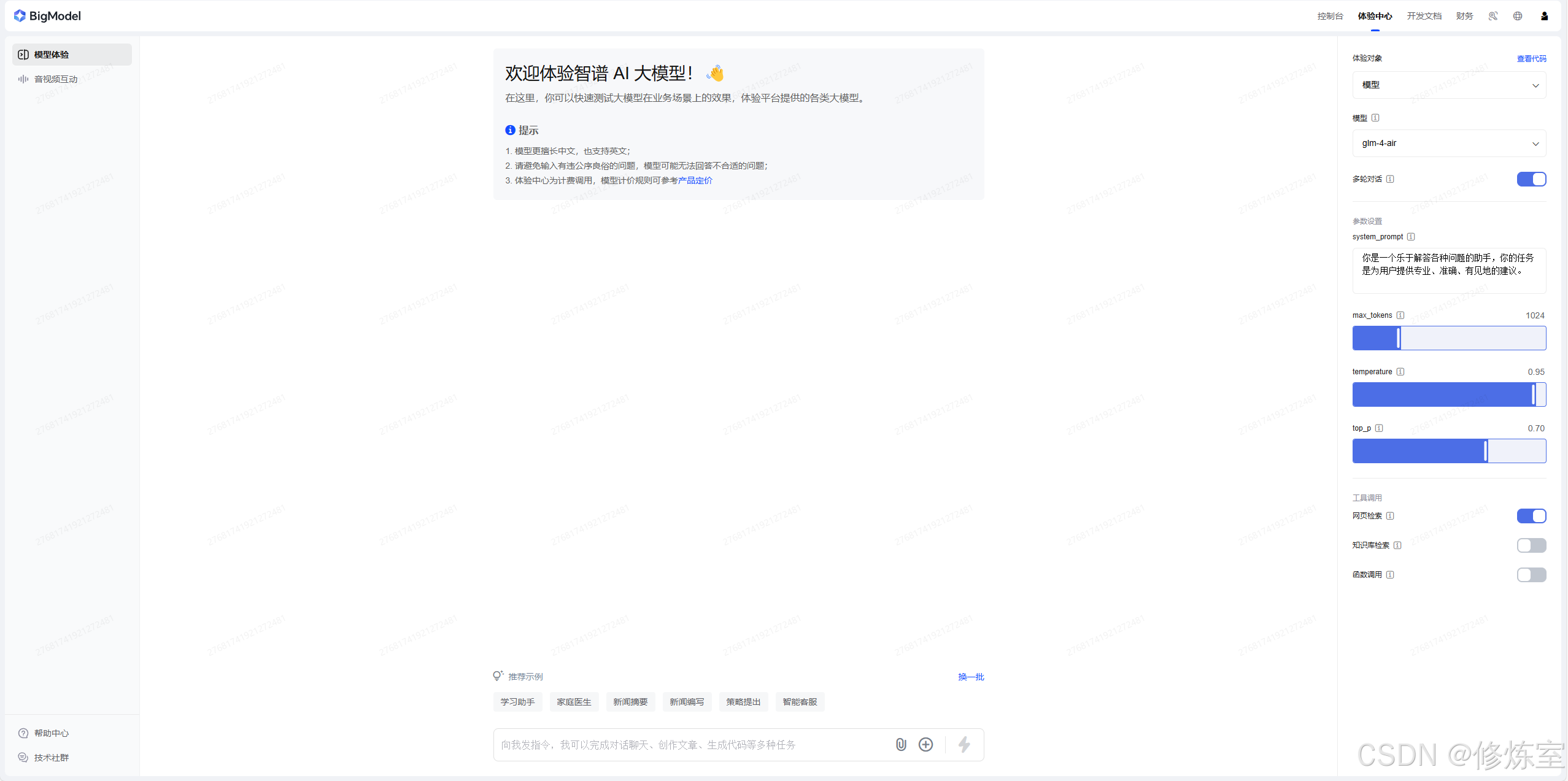
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="your api key")
response = client.chat.completions.create(
model="glm-4-flash",
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"},
{"role": "user", "content": "你好"}
],
top_p=0.7,
temperature=0.95,
max_tokens=1024,
tools=[{"type":"web_search","web_search":{"search_result":True}}],
stream=True
)
for trunk in response:
print(trunk)
5.1 运行结果分析
此代码的 stream=True 使 API 以流式输出方式返回结果,每个 ChatCompletionChunk 代表一个 token 输出。例如,输出可能是:
ChatCompletionChunk(id='xxx', choices=[Choice(delta=ChoiceDelta(content='你好', role='assistant', tool_calls=None, audio=None), finish_reason=None, index=0)], created=xxxxxx, model='glm-4-flash', usage=None, extra_json=None)
ChatCompletionChunk(id='xxx', choices=[Choice(delta=ChoiceDelta(content='👋!', role='assistant', tool_calls=None, audio=None), finish_reason=None, index=0)], created=xxxxxx, model='glm-4-flash', usage=None, extra_json=None)
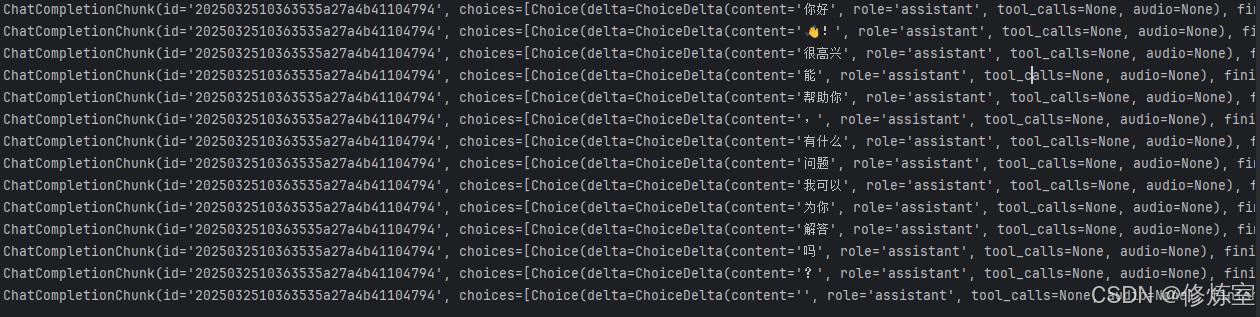
这种方式适用于实时打字机效果(如聊天机器人),但对于普通应用,分块输出可能显得不直观。
🚨 问题:stream=True 会让 API 逐字返回,输出过程显得不直观。
5.2 ✅ 解决方案:修改为非流式输出
如果希望 API 直接返回完整的回答,可设置 stream=False 或移除该参数:
response = client.chat.completions.create(
model="glm-4-flash",
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"},
{"role": "user", "content": "你好"}
],
top_p=0.7,
temperature=0.95,
max_tokens=1024,
tools=[{"type":"web_search","web_search":{"search_result":True}}]
)
print(response.choices[0].message.content)
🔹 运行结果
你好👋!很高兴见到你,有什么可以帮助你的吗?
✅ 非流式输出的优点:
- 直接获取完整回答,无需拼接。
- 更适合批量处理和标准 API 调用。
⚠ 注意:非流式输出可能会稍慢,在 API 处理完之前不会返回任何内容,请耐心等待。
6. 可能遇到的问题及解决方案
6.1 网络连接错误
错误信息:
zhipuai.core._errors.APIConnectionError: Connection error.
✅ 解决方案:
- 检查网络连接。
- 确保未开启影响 API 访问的代理。
6.2 认证失败(401 错误)
错误信息*:
zhipuai.core._errors.APIAuthenticationError: Error code: 401, with error text {"error":{"code":"401","message":"令牌已过期或验证不正确!"}}
✅ 解决方案:
- 确保
ZhipuAI(api_key="xxx")中正确填写了 API Key。 - 若 Key 失效,可在 API Key 管理页面 申请新的 Key。
7. 流式 vs 非流式输出对比
| 方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 流式 (stream=True) | 实时交互,如聊天机器人 | 逐字返回,响应迅速 | 需要手动拼接,难以一次性获取完整内容 |
| 非流式 (stream=False) | 普通 API 调用 | 直接返回完整结果,适合批量处理 | 需要等待完整结果返回 |
8. 结论
智谱清言 API 提供了流式和非流式输出选项,选择合适的方式可以优化用户体验。
- 💡如果希望逐字显示,提高交互性,可以使用
stream=True; - 💡如果希望一次性获得完整结果,提高可读性,则应使用
stream=False。
掌握这一技巧,可以让你的 API 调用更加高效,轻松获取完整的 AI 生成内容!

















 2088
2088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









