







文章目录
1 最大似然估计 maximum likelihood estimate
一个讲解最大似然估计的视频很好——来自小元老师
最大似然估计要解决的问题如下一个例子,是一个直观理解:
举一个例子,现在我们讨论一个射击的概率问题,你在靶场进行射击测试,假设你的射击命中率比较稳定,是 P P P,现在你进行了n组实验,每组射击打10发子弹,分别命中了 X 1 X_1 X1次, X 2 X_2 X2次,…, X n X_n Xn次,我们想要通过这几次实验比较准确的估计出你的稳定射击命中率 P P P应该是多少?
如果我们站在上帝视角下,假设你的命中率是0.5,那么我们将可以做出一个概率密度分布函数如下:
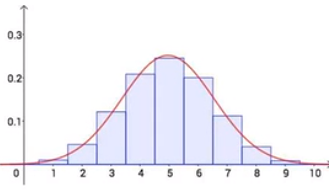
但是我们毕竟不是上帝,我们无法获知你的命中率的真实分布情况,所以我们进行了大量的实验,希望通过大量的实验来比较好的估计出你的射击命中率 P P P,这也就估计出了我们想要的真是分布情况。
那么怎么估计呢?理论上讲,我们做了大量的重复实验,每一组实验都应该有一个命中率 P ( X = X i ) P(X=X_i) P(X=Xi),我们的n组实验在现实情况同时发生的情况下(所有实验命中率的连乘积,其实也就是我们的似然函数),去估计这个分布的参数,当我们的参数估计越接近真实分布,我们的所有实验命中率的连乘积也将会达到最大,也就是我们的似然函数此时取到了最大值。
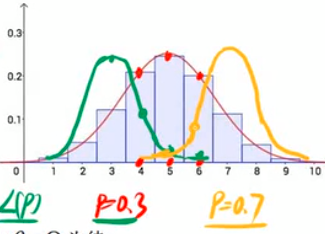
如上图所示,我们猜测命中率分别可能是0.3和0.7分别讲实验结果的分布画出来,求出所有实验命中率的连乘积,站在上帝视角下你的真是命中率是0.5, 只有当你在现实中估计的参数是0.5的时候,我们求得所有实验命中率的连乘积才会最大。
所以有下面这样一个直观的事实:
所有实验命中率的连乘积最大(似然函数最大) 等价于 估计的参数越接近真实的数据分布
使用数学语言描述就是下面的:
给定一个概率分布 D D D,已知其概率密度函数(连续分布)或概率质量函数(离散分布)为 f D f_D fD,以及一个分布参数 θ \theta θ (相当于上面例子的 P P P),我们可以从这个分布中抽出一个具有 n n n个值的采样 X 1 , X 2 , … , X n X_1, X_2,\ldots, X_n X1,X2,…,Xn,利用 f D f_D fD计算出其似然函数: L ( θ ∣ X 1 , … , X n ) = f θ ( X 1 , … , X n ) L(\theta \mid X_{1},\dots ,X_{n})=f_{\theta }(X_{1},\dots ,X_{n}) L(θ∣X1,…,Xn)=fθ(X1,…,Xn)
最大似然估计本质上是一个优化问题,通过设置优化变量 p p p,计算对应的函数输出值,取函数值最大的那个对应的 p p p为结果,认为这个结果就是我们的参数最好估计值 θ ^ = p \widehat{\theta} = p θ =p。
求解最大似然估计的步骤如下:
- 确定优化变量,写出似然函数 L ( θ ) L(\theta) L(θ)
- 对似然函数做对数化处理 l n ( L ( θ ) ) ln(L(\theta)) ln(L(θ))
- 对上一步函数进行求导
∂
l
n
(
L
(
θ
)
)
∂
θ
\frac{\partial ln(L(\theta))}{\partial \theta}
∂θ∂ln(L(θ))然后进行优化求解
对于简单的问题,求一阶导数为零对应的 θ \theta θ值即可,但是很多时候我们没办法求出来最优解,这个时候就需要优化算法来帮助我们来求解问题。但是最核心的还是如何构建出似然函数。
2 几个概率相关的函数
2.1 累积分布函数Cumulative Distribution Function(CDF)
是概率密度函数的积分,能完整描述一个实随机变量X的概率分布
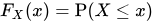

2.2 概率密度函数Probability Density Function(PDF)

2.3 概率质量函数probability mass function(PMF)
PMF是离散随机变量在各特定取值上的概率。
概率质量函数PMF和概率密度函数PDF不同之处在于
-
概率质量函数是对离散随机变量定义的,本身代表该值的概率;
-
概率密度函数是对连续随机变量定义的,本身不是概率,只有对连续随机变量的概率密度函数在某区间内进行积分后才是概率。
















 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









