






深度学习自然语言处理 分享
整理:pp
Analyzing and Reducing Catastrophic Forgetting in Parameter Efficient Tuning
摘要:现有研究表明,大语言模型(LLM)在语言理解和生成方面表现出卓越的性能。然而,当 LLM 在复杂多样的特定领域下游任务上不断进行微调时,其在历史任务上的推理性能会急剧下降,这就是所谓的灾难性遗忘问题。因此,需要在学习可塑性和记忆稳定性之间进行权衡。现有的大量研究都探索了记忆重放、正则化和参数隔离等策略,但对持续 LLMs 微调场景中各种相邻最小值的几何联系却知之甚少。在这项工作中,我们从mode connection的角度研究了不同极小值之间的geometric connection,这意味着不同极小值之间可以低损耗地连接起来。通过大量实验,我们发现了 LLMs 持续学习场景中的模式连接现象,并发现它可以在可塑性和稳定性之间取得平衡。在这些发现的基础上,我们提出了一种简单而有效的方法,称为基于插值的 LoRA(I-LoRA),它基于 LoRA 参数插值构建了一个双内存经验重放框架。在八个特定领域的CL基准上进行的广泛实验和分析表明,I-LoRA与之前的先进方法相比始终保持着显著的改进,性能提升高达11%,为未来大型语言模型持续学习问题的研究提供了坚实的基础和深刻的见解。

https://arxiv.org/abs/2402.18865
Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决大型语言模型(LLMs)在持续学习(Continual Learning, CL)场景中遇到的灾难性遗忘(Catastrophic Forgetting)问题。在持续学习过程中,当LLMs在复杂且多样化的特定领域下游任务上进行连续微调时,它们在历史任务上的推理性能会显著下降。这种现象是由于学习塑性(快速适应新任务)和记忆稳定性(保留已学知识)之间的权衡。论文提出了一种基于插值的LoRA(Interpolation-based LoRA, I-LoRA)方法,通过构建一个基于LoRA参数插值的双记忆体验重放框架,旨在在塑性和稳定性之间取得平衡。通过在八个特定领域的CL基准测试上的广泛实验和分析,论文证明了I-LoRA在性能上显著优于先前最先进的方法,并为未来关于大型语言模型持续学习问题的研究提供了强有力的基线和洞见。

Q2: 有哪些相关研究?
A:相关研究主要集中在以下几个方面:
记忆重放(Replay-based)方法:这些方法通过显式地存储历史数据的一个子集或提示(prompts)来保留历史信息。例如,Chaudhry等人(2019b)提出的Elastic Weight Consolidation (EWC) 方法,以及Khan等人(2023)提出的Gradient Gradient Episode Memory (GEM) 方法。
正则化(Regularization)方法:这类方法通过惩罚重要模型参数的变化或在新任务学习期间从历史模型进行嵌入级别的蒸馏来实现。例如,Li和Hoiem(2017)提出的正则化方法。
参数隔离(Parameter Isolation)方法:这些方法通过显式编码特定于任务的模型参数来减轻遗忘,例如,Kang等人(2022)提出的通过引入一系列适配器来巩固历史知识的策略。
线性模式连接(Linear Mode Connectivity):这是一个现象,即不同的最小值可以通过低损失路径在参数空间中连接。Garipov等人(2018)和Doan等人(2023)在计算机视觉领域进行了相关研究,发现在多任务学习和持续学习场景中,解决方案可以通过简单的曲线在权重空间中展示低误差。
预训练模型的模式连接分析:Qin等人(2022)在预训练模型上进行了模式连接分析,揭示了尽管在不同任务上训练的最小值本质上是断开的,但预训练逐渐以一种隐式的方式将多样化任务的最优区域拉近。
这些研究为本文提出的I-LoRA方法提供了理论基础和技术支持。本文首次在参数高效的微调(Parameter-Efficient Fine-Tuning, PEFT)框架内深入研究持续学习,并提出了一种新的视角来理解和改进大型语言模型的持续学习。
Q3: 论文如何解决这个问题?
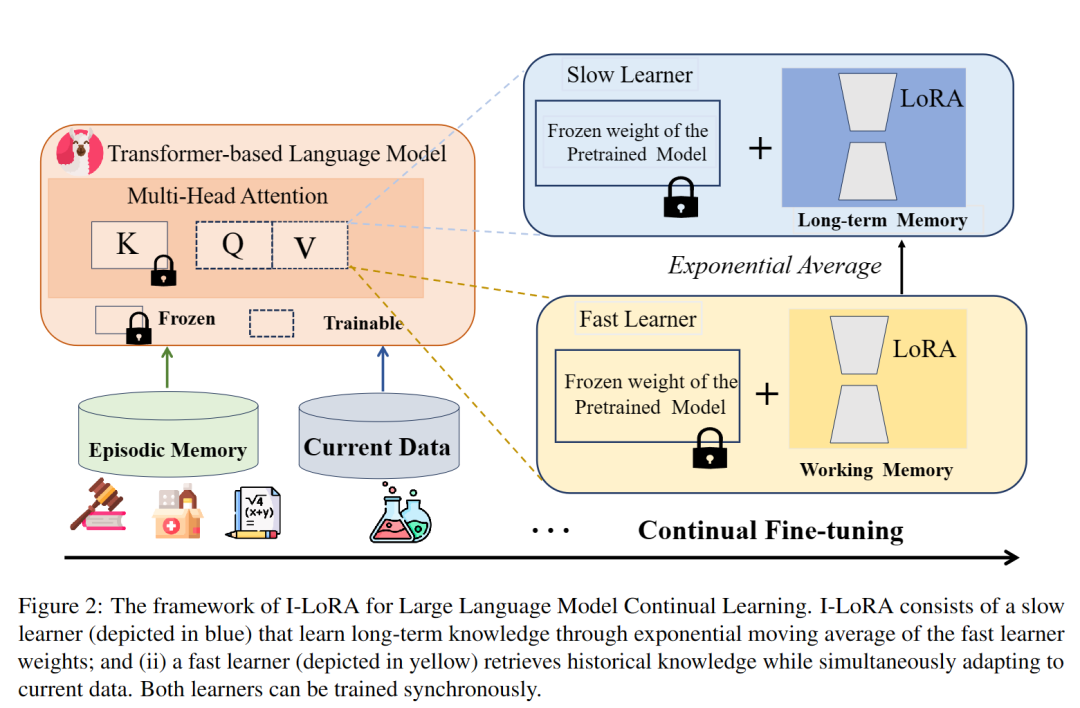
A:论文通过以下步骤解决大型语言模型在持续学习中的灾难性遗忘问题:
模式连接性(Mode Connectivity)分析:首先,论文通过实验研究了在参数高效的持续学习(PEFT)中模式连接性的存在。模式连接性指的是不同的最小值可以通过低损失路径在参数空间中连接。论文发现,在LLMs的持续微调场景中存在模式连接性,并且可以通过构建参数路径来连接历史和当前任务的最优解。
提出I-LoRA方法:基于模式连接性的发现,论文提出了一种名为Interpolation-based LoRA (I-LoRA) 的方法。I-LoRA构建了一个双记忆体验重放框架,该框架包含一个快速学习器(由工作记忆参数化) 和一个慢速学习器(由长期记忆参数化)。快速学习器负责快速适应不断变化的数据,而慢速学习器则旨在巩固长期记忆并保留历史知识。
双记忆架构:I-LoRA通过维护长期记忆(θl)和工作记忆(θw)来实现快速和慢速学习。长期记忆通过指数移动平均快速学习器的权重来更新,从而在历史和新知识之间实现平衡。
持续PEFT算法:I-LoRA在持续PEFT过程中,通过优化快速学习器来适应新任务,并通过更新慢速学习器来保留历史知识。这个过程涉及到在混合数据集上优化交叉熵损失和历史实例嵌入与慢速学习器之间的均方误差损失。
实验验证:论文在八个特定领域的CL基准测试上进行了广泛的实验和分析,证明了I-LoRA在塑性和稳定性之间的权衡上显著优于先前的方法,并提供了强大的基线和洞见。
通过这些步骤,I-LoRA能够有效地在LLMs的持续学习过程中平衡快速适应新任务的能力和保留历史知识的能力,从而减轻灾难性遗忘问题。
Q4: 论文做了哪些实验?
A:论文进行了一系列实验来验证I-LoRA方法的有效性,主要包括以下几个方面:
模式连接性评估:通过线性插值在相邻任务的最小值之间进行评估,观察在不同插值因子λ下模型在历史任务、当前任务和所有任务上的推理准确率(Ap, An, All)。
双记忆架构实验:构建了一个包含快速学习器(工作记忆θw)和慢速学习器(长期记忆θl)的双记忆框架,并在实验中调整λ值以观察权重距离和特征表示的相似性。
持续PEFT算法实现:实现了I-LoRA算法,并在训练过程中使用了经典的经验重放(ER)作为基础框架,同时保持了历史数据的一个子集。
跨领域CL基准测试:在八个特定领域的CL基准测试上进行实验,这些领域包括教育、临床、金融、法律、政治等,以及多语言和数学推理任务。
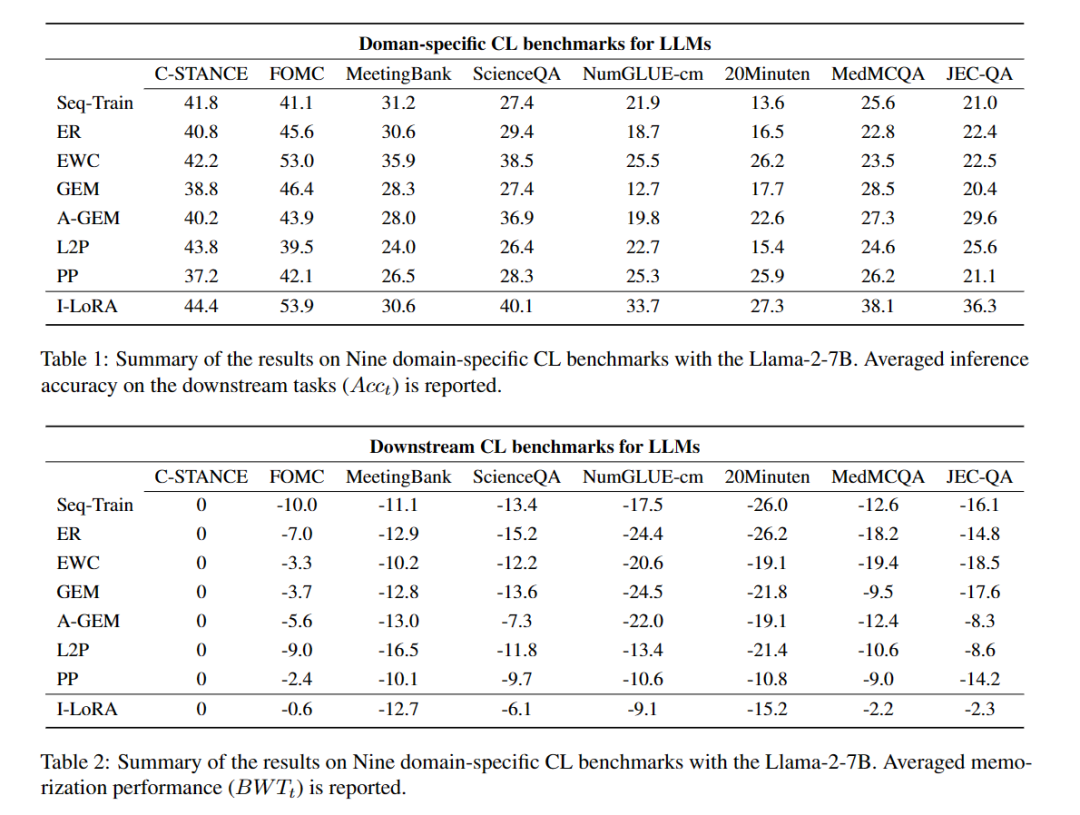
性能比较:将I-LoRA与九种代表性的基线方法进行比较,包括零次推理(ZSI)、序列微调(Seq-Train)、经验重放(ER)、弹性权重巩固(EWC)、梯度梯度记忆(GEM)、平均梯度梯度记忆(A-GEM)、学习提示(L2P)、渐进提示(PP)和多任务学习(MTL)。
记忆能力评估:通过评估后向转移能力(BWT)来衡量模型在持续学习过程中的记忆能力,即学习新任务对旧任务性能的影响。
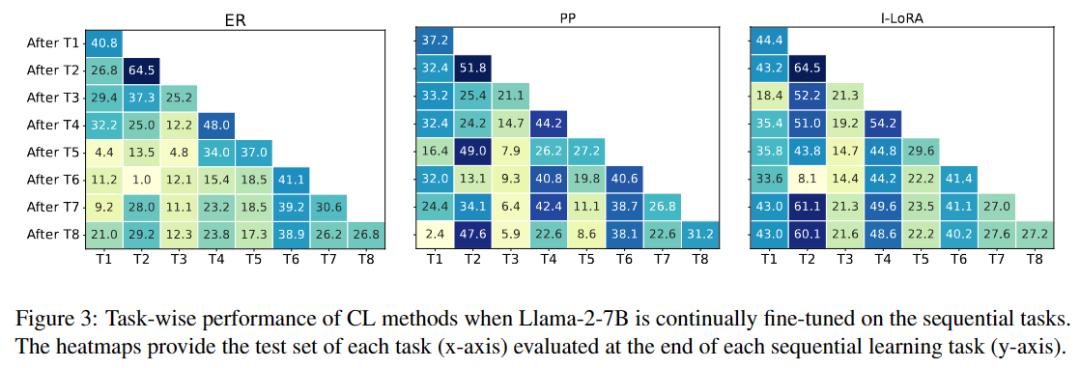
任务性能细粒度分析:分析了模型在顺序学习任务时的性能变化,以理解不同方法如何在稳定性和塑性之间取得平衡。
一般任务性能评估:在完成特定领域的持续学习后,评估模型在一般语言建模任务上的性能,以验证模型在保留通用知识方面的能力。
这些实验结果表明,I-LoRA在持续学习场景中能够显著提高模型的性能,同时减轻灾难性遗忘问题,为大型语言模型的持续学习问题提供了新的解决方案。
Q5: 有什么可以进一步探索的点?
A:尽管论文提出了I-LoRA方法并取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
理论分析:虽然论文通过实验验证了模式连接性的存在,但对模式连接性的深入理论分析仍然有限。未来的研究可以探索模式连接性的数学基础和理论限制。
算法优化:I-LoRA方法虽然有效,但可能还有进一步优化的空间。例如,可以研究如何更精确地确定插值因子λ,或者如何改进双记忆架构以实现更好的性能。
跨领域适应性:研究I-LoRA在更广泛的领域和任务上的适应性和泛化能力,特别是在那些与训练数据分布差异较大的领域。
计算效率:I-LoRA方法在实现过程中可能涉及较高的计算成本。研究如何降低计算复杂度,使其更适合资源受限的环境。
长期记忆的维护:探索长期记忆的维护策略,例如如何有效地更新和压缩长期记忆,以及如何处理长期记忆的容量限制。
遗忘机制研究:深入研究遗忘的机制,包括在持续学习过程中哪些类型的知识和参数更容易被遗忘,以及如何设计策略来减少这种遗忘。
多任务学习与持续学习的结合:研究如何将I-LoRA方法与多任务学习相结合,以进一步提高模型在处理多个相关任务时的性能。
实际应用:将I-LoRA方法应用于实际问题,如自然语言处理、计算机视觉等领域,验证其在实际环境中的有效性和实用性。
模型压缩和加速:研究如何将I-LoRA方法与模型压缩技术结合,以实现更小、更快的模型,同时保持或提高性能。
可解释性和透明度:提高模型的可解释性,使得I-LoRA的决策过程更加透明,便于理解和调试。
这些研究方向可以帮助我们更好地理解持续学习过程中的挑战,并为开发更高效、更稳定的持续学习方法提供新的视角。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
问题定义:论文针对大型语言模型(LLMs)在持续学习(CL)场景中遇到的灾难性遗忘问题,即在连续微调新任务时,模型在历史任务上的性能显著下降。
研究动机:为了在LLMs中实现学习塑性(快速适应新任务)和记忆稳定性(保留已学知识)之间的平衡,论文提出了一种新的视角,即通过分析不同任务最优解之间的几何连接(模式连接性)来解决遗忘问题。
方法提出:基于模式连接性的现象,论文提出了一种名为Interpolation-based LoRA (I-LoRA) 的方法。I-LoRA通过构建一个双记忆体验重放框架,包含快速学习器(工作记忆)和慢速学习器(长期记忆),来模拟权重插值过程。
实验设计:在八个特定领域的CL基准测试上进行了广泛的实验,包括教育、临床、金融、法律、政治等领域,以及多语言和数学推理任务。
性能评估:通过与多种基线方法的比较,I-LoRA在塑性和稳定性之间的权衡上显示出显著的性能提升,平均性能增益达到11%。
分析与讨论:论文对I-LoRA在不同任务上的性能进行了细粒度分析,并探讨了权重距离、中心核对齐(CKA)相似性和嵌入景观可视化等指标,以理解I-LoRA如何实现平衡。
结论与展望:论文得出结论,I-LoRA能够有效地减轻LLMs在持续学习中的灾难性遗忘问题,并为未来的研究提供了新的视角和方法。同时,论文也指出了未来研究的潜在方向,如理论分析、算法优化和实际应用等。
总的来说,这篇论文通过提出I-LoRA方法,为解决LLMs在持续学习中的灾难性遗忘问题提供了一种有效的解决方案,并在实验中验证了其有效性。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









