






作者:摘星狐狸
链接:https://www.zhihu.com/question/656903686/answer/3527956804
来源:知乎(学术分享,侵删)
Yann LeCun的建议说得很直白,LLM已经在大厂手里了,作为一个学生能做的很有限。与其继续在已有的路径上卷,不如去探索更多可能性 -- “lift the limitations of LLMs”!但如果要解读的话,只看字面意思未免浅了些,那就让我们聊点深入的吧。
LeCun的观点
LeCun对大语言模型的“吐槽”由来已久。早在2022年他就指出,语言只承载了所有人类知识的一小部分,而大部分人类知识和所有动物知识都是非语言的,因此大语言模型无法达到人类水平的智能。他对大语言模型的能力始终持怀疑态度,认为它们在理解复杂世界方面存在局限性。
LeCun认为当前的人工智能研究应该放弃生成模型和强化学习方法等主流路线,基于自监督的方法更有希望实现通向通用人工智能(AGI)的突破,未来的人工智能发展方向不应仅仅依赖于大语言模型,而应探索更多元化的技术路径。这才是他一以贯之的观点。
而这种观点的背后,其实是对大模型自身固有限制的担忧。业界疯狂助推所谓“力大砖飞”的大模型,部分也是因为底层架构研究进展缓慢,实在等不及了。
当下的LLM有哪些限制?
当下的LLM大都基于Transformer架构,而Transformer架构的核心是自注意力机,它需要计算输入序列中每个元素对其他所有元素的注意力分数。随着序列长度的增加,这种计算的复杂度呈平方级增长,导致计算成本急剧上升。而由于自注意力层的内存需求与输入序列长度成正比,更长的序列也会导致内存消耗显著增加。这也是为什么LLM都有上下文长度的限制。
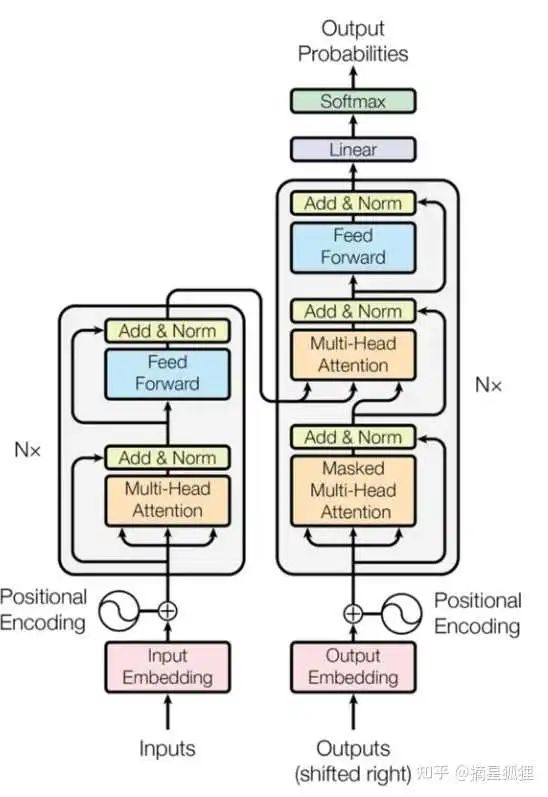
而从模型输出效果来看,尽管大语言模型能够生成连贯的文本,但它们可能无法完全理解生成单词的上下文语境或含义。这意味着它们生成的文本可能缺乏深度或与对话的上下文不完全关联。比如,大语言模型在其训练流程中没有关于事件发生先后顺序的概念,因此它们可能无法理解“时间”。而在空间上,大语言模型在处理描述同一事件的多个文本时,可能无法认识到它们之间的关联,从而无法形成一个一致、完整的世界观。
由于模型所做的一切就是猜测下一个token,它们不真正“知道自己知道什么”,这也导致了大语言模型的决策过程往往是黑箱的,缺乏可解释性,也就难以调试。
为了解决上面这些问题,人们在尝试各种方法。比如为了降低深度学习模型的能耗并保持或提升性能,人们发明了模型剪枝/压缩/蒸馏、轻量级架构、模型并行与数据并等方法,希望用更小的模型达到同样出色、甚至更出色的效果。
但在LeCun看来,这些都是在单一路径下的尝试,是治标不治本的。而对于计算机专业的学生来说,即便有足够的算力支持,想要做出突破LLM限制的工作,也不是一件容易的事。
LLM的跨学科应用
相较于想方设法突破大模型的种种限制,一个更有潜力的方向是寻找大模型的跨学科应用。例如由清华大学聂再清教授团队开发的多模态生物医药大模型BioMedGPT,就整合了基因、分子、细胞、蛋白、文献、专利、知识库等多源异构数据,有助于在药物靶点探索、先导化合物设计与优化、蛋白质设计等领域的应用。
对于学生来说,这可能更容易出成果。一方面,跨学科研究可以让学生更有效地利用现有资源,如专业数据库、实验设备和领域专家的知识,不至于为缺乏算力而挠破头。另一方面,在项目中学习如何将大模型技术应用于特定领域,也有助于掌握将技术转化为实际应用的能力,对于大多数学生的就业来说更有好处。更重要的是,跨领域的边缘地带往往也是创新最密集的地方,在这里工作能产生巨大的价值。
当然,要想用LLM做出跨学科的应用,工程能力是必须的。
世界模型
如果LLM不是AI的最终方向,那它又会是什么呢?Yann LeCun给出了他的答案,那就是“世界模型”。
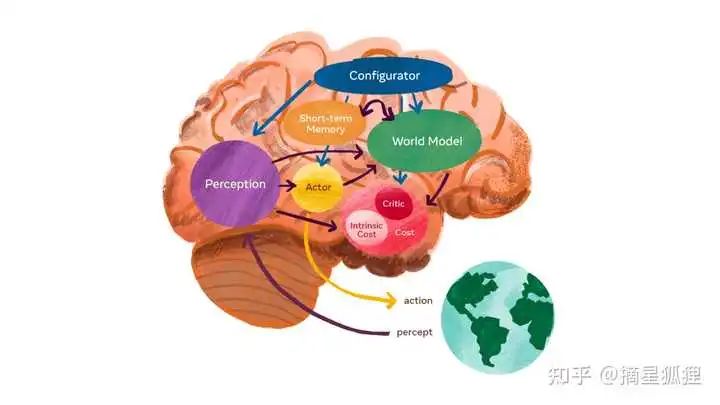
LeCun提出的自主智能的系统架构
世界模型(world models)是用于描述智能系统如何捕捉和模拟现实世界的概念框,它对于智能体的认知功能、逻辑推理以及决策制定至关重要。具体而言,世界模型涵盖了对自然界法则、社会结构和人类思维过程的深入洞察,赋予了AI更精准地识别环境状态、响应外界变化的能力。通过构建精确的世界模型,AI系统可以在其中进行反复试错,找到现实中的最优决策。Yann LeCun认为,世界模型是通往强人工智能(AGI)的关键技术路径之一。
要理解世界模型,我们可以试着把它和两类技术进行对比。第一个是多模态大模型,当初Sora诞生时,很多人认为它就是world simulator,然而事实证明,尽管Sora能够生成视频,但它更多是一个视频工具,并不能很好地进行反事实推理(counterfactual reasoning),即在没有实际数据支持的情况下,准确回答“what if”类型的问题。Sora并没有准确地学到物理规律,这表明简单的数据堆砌可能并不是实现高级智能的正确途径。而世界模型的最大特点,就是能够进行反事实推理。
另一个场景是数字孪生。这种技术通常基于数据驱动的方法,创建一个数字副本来代表一个物理实体或过程。通过利用数字化建模技术、实时数据收集、仿真运行以及深入分析,数字孪生能够与原系统实现同步,并对其进行有效的监测和性能提升。这种方法允许用户在虚拟环境中模拟、预测和优化物理系统的运行,从而提高效率并降低风险。可是随着时间的推移,单纯的数据驱动的数字孪生已经不能满足复杂系统的需求了。比如智能建筑使用数字孪生来监控和控制建筑内的环境条件,如温度、湿度、能耗等。但是建筑物的实际使用情况可能因季节、天气或居住者的行为而变化,如果模型不能适应这些动态变化,其优化建议就不再适用。而这正好是世界模型的强项,通过让系统合成和解释大量的传感器数据,从而预测潜在的未来场景。
对于一个想要进入AI领域工作的人来说,LLM代表着当下,而世界模型可能是未来。就大模型而言,单纯的语言模型可能不如多模态更有潜力,其技术栈尚未收敛,多模态学习和跨模态对齐仍然是技术难点。而一旦在反事实推理方面取得突破,AI的决策能力将大幅提升,就可能带来真正的AGI。
备注:昵称-学校/公司-方向/会议(eg.ACL),进入技术/投稿群

id:DLNLPer,记得备注呦

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









