






论文链接:https://arxiv.org/pdf/2403.07300
论文概述
这篇论文主要针对多变量时间序列预测(Multivariate Time Series Forecasting, MTSF)问题,提出了一个新的跨模态微调框架——CALF(Cross-ModAl LLM Fine-Tuning)。论文的核心思想是利用预训练大语言模型(LLM)的强大上下文建模能力,同时通过设计专门的跨模态对齐技术来弥合时间序列数据(临时模态)与文本数据(语言模态)之间的分布差异,从而提升预测性能。整个框架在长短期预测以及少样本/零样本学习场景下均表现出较好的泛化能力和低计算复杂度。
1. 引言与背景
1.1 时间序列预测的重要性
- 实际应用:天气预报、能耗预测、金融建模等领域均依赖准确的时间序列预测。
- 挑战:传统基于单模态(即仅时间序列数据)的深度学习方法容易受到数据量不足、过拟合等问题的影响,导致模型在实际场景中泛化能力不足。
1.2 LLM 在时间序列预测中的应用
- 背景:近年来,研究者开始尝试将预训练的 LLM 用于时间序列预测,利用其大规模预训练获得的丰富语义信息,进而提升模型表现。
- 问题:直接将时间序列数据投影为与文本输入相匹配的维度,忽略了二者之间分布的巨大差异,这使得直接微调效果往往不尽人意。
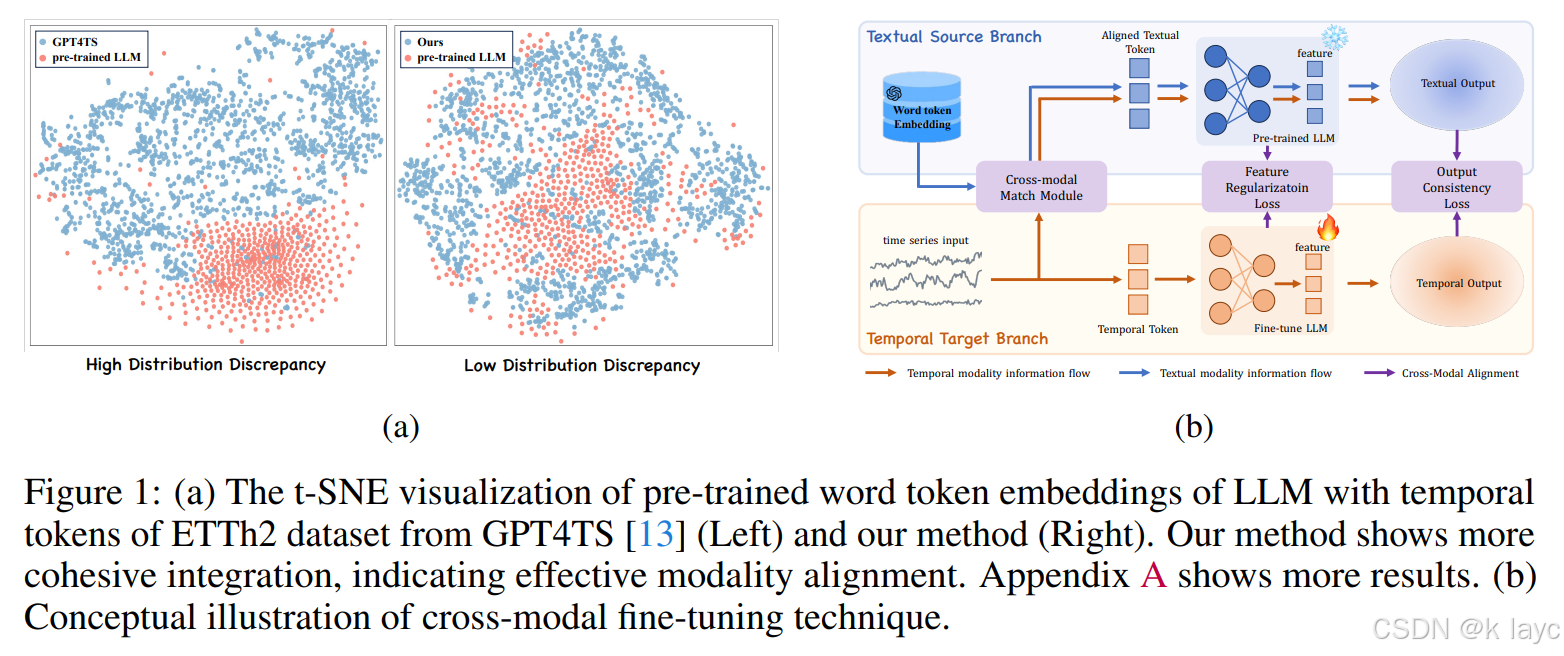
1.3 本文的主要贡献
- 分布对齐问题:明确指出现有方法忽略了文本与时间序列输入之间的分布差异。
- CALF 框架:提出包含三大技术模块的跨模态微调方法:
- Cross-Modal Match Module:通过跨注意力机制将时间序列投影到文本词嵌入空间。
- Feature Regularization Loss:在中间层对齐文本和时间序列两支路的特征表示。
- Output Consistency Loss:保证最终输出的语义一致性。
- 实验验证:在多个真实数据集上展示了 CALF 在长短期预测、少样本及零样本学习场景下的出色表现,同时兼顾低计算复杂度。
2. 方法论
论文的方法论部分详细介绍了 CALF 框架的整体结构及关键技术,主要包括以下几个部分。
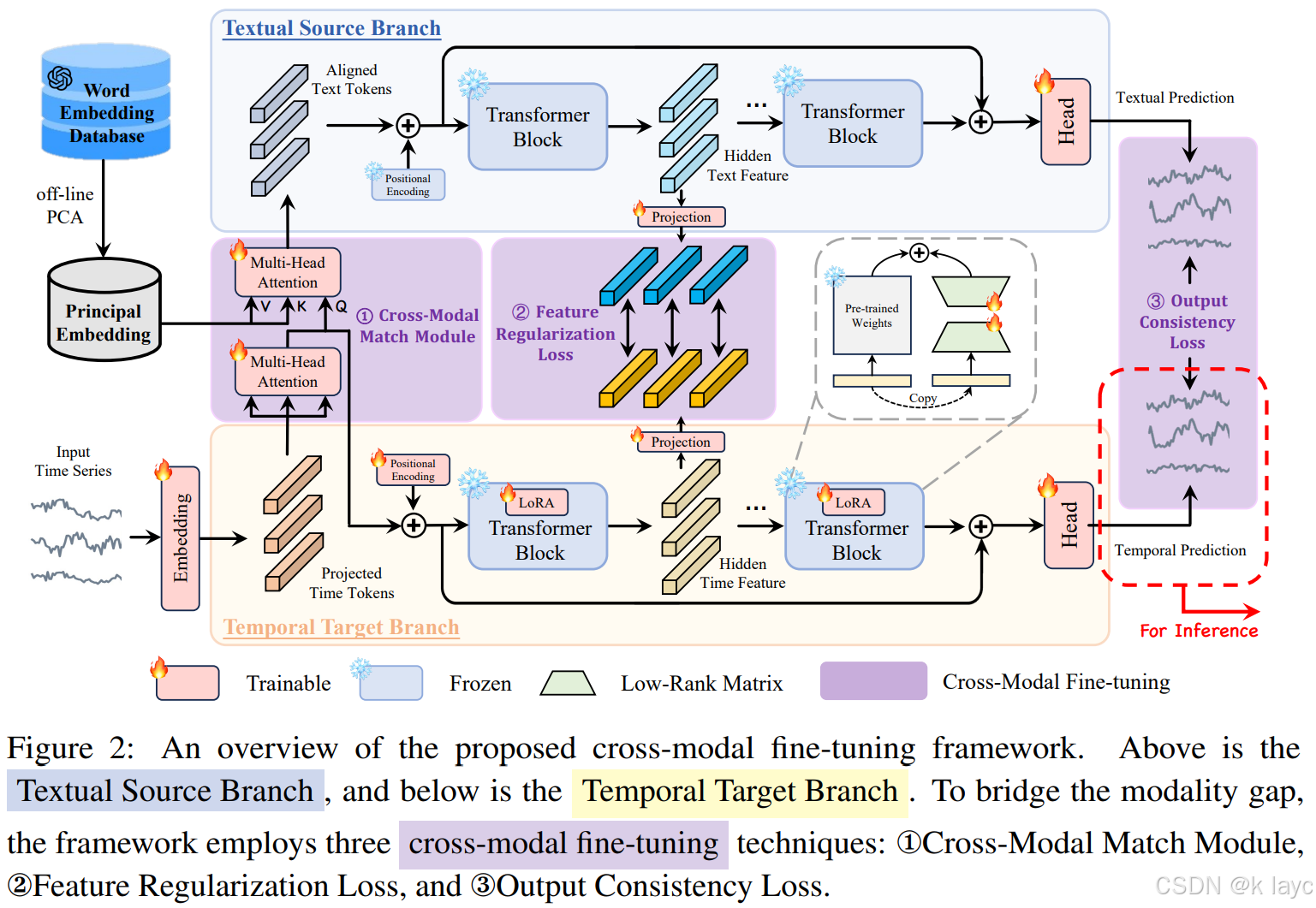
2.1 框架总览
CALF 框架由两大支路构成:
- 文本源支路(Textual Source Branch):输入为经过对齐的文本 tokens,通过预训练 LLM 的多个 Transformer 层提取文本特征,最终得到输出 Y t e x t Y_{text} Ytext。
- 时间目标支路(Temporal Target Branch):输入为经过预处理和投影后的时间序列 tokens,同样使用与文本支路相同的预训练权重获得时间特征,输出为 Y t i m e Y_{time} Ytime。
两支路之间通过三种跨模态对齐技术进行交互和微调。
2.2 Cross-Modal Match Module
2.2.1 目的
在 LLM 中,词嵌入层构成了良好的语义空间。然而,直接将时间序列数据简单映射到该空间会存在分布不匹配的问题。Cross-Modal Match Module 的目标就是将时间序列数据的分布与原始文本词嵌入分布进行对齐。
2.2.2 操作流程
-
时间序列嵌入与自注意力
给定多变量时间序列 I ∈ R T × C I \in \mathbb{R}^{T \times C} I∈RT×C(其中 T T T 为序列长度, C C C 为通道数),首先使用一个嵌入层将每个通道从时间步映射到与 LLM 相同的维度 M M M,再经过多头自注意力(MHSA)得到时间 tokens:
X t i m e = MHSA ( Embedding ( I ) ) ∈ R C × M . X_{time} = \text{MHSA}(\text{Embedding}(I)) \in \mathbb{R}^{C \times M}. Xtime=MHSA(Embedding(I))∈RC×M.
这里, Embedding ( ⋅ ) \text{Embedding}(\cdot) Embedding(⋅) 实现了从 T T T 到 M M M 的通道级映射。 -
词嵌入字典与 PCA 降维
预训练 LLM 的词嵌入矩阵为 D ∈ R ∣ A ∣ × M D \in \mathbb{R}^{|A| \times M} D∈R∣A∣×M,其中 ∣ A ∣ |A| ∣A∣ 表示词汇表大小。直接使用跨注意力计算会非常耗费计算资源,因此论文提出使用 PCA 对 D D D 进行降维,得到主成分词嵌入:
D ^ = PCA ( D ) ∈ R d × M , \hat{D} = \text{PCA}(D) \in \mathbb{R}^{d \times M}, D^=PCA(D)∈Rd×M,
其中 d ≪ ∣ A ∣ d \ll |A| d≪∣A∣ 为预定义的低维度。 -
跨注意力对齐
使用多头跨注意力机制,将时间 tokens 作为查询(query),而将降维后的词嵌入 D ^ \hat{D} D^ 作为键(key)和值(value),进行对齐:
X t e x t = Softmax ( Q K T C ) V , X_{text} = \text{Softmax}\left(\frac{QK^T}{\sqrt{C}}\right)V, Xtext=Softmax(CQKT)V,
其中,
Q = X t i m e W q , K = D ^ W k , V = D ^ W v . Q = X_{time}W_q,\quad K = \hat{D}W_k,\quad V = \hat{D}W_v. Q=XtimeWq,K=D^Wk,V=D^Wv.
这样得到的 X t e x t ∈ R C × M X_{text} \in \mathbb{R}^{C \times M} Xtext∈RC×M 即为经过对齐的文本 tokens,为文本支路提供输入。
2.3 Feature Regularization Loss
2.3.1 动机
预训练 LLM 的权重主要是基于文本数据训练的。直接使用这些权重对时间序列数据进行处理时,容易因为特征分布不匹配而导致梯度更新不足,从而影响模型性能。为了使时间支路的中间层输出与文本支路保持一致,引入了特征正则化损失。
2.3.2 定义
假设在第
l
l
l 层 Transformer 模块中,文本支路和时间支路分别输出的隐藏特征为
F
t
e
x
t
l
F_{text}^l
Ftextl 和
F
t
i
m
e
l
F_{time}^l
Ftimel。通过两个可训练的投影层
ϕ
t
e
x
t
l
(
⋅
)
\phi_{text}^l(\cdot)
ϕtextl(⋅) 和
ϕ
t
i
m
e
l
(
⋅
)
\phi_{time}^l(\cdot)
ϕtimel(⋅) 将特征映射到共享表示空间中,然后计算相似性,定义特征正则化损失为:
L
f
e
a
t
u
r
e
=
∑
i
=
1
L
γ
(
L
−
i
)
s
i
m
(
ϕ
t
e
x
t
i
(
F
t
e
x
t
i
)
,
ϕ
t
i
m
e
i
(
F
t
i
m
e
i
)
)
,
L_{feature} = \sum_{i=1}^{L} \gamma^{(L-i)} \, sim\Big(\phi_{text}^{i}(F_{text}^{i}), \phi_{time}^{i}(F_{time}^{i})\Big),
Lfeature=i=1∑Lγ(L−i)sim(ϕtexti(Ftexti),ϕtimei(Ftimei)),
其中
γ
\gamma
γ 是控制各层损失权重的超参数,
s
i
m
(
⋅
,
⋅
)
sim(\cdot,\cdot)
sim(⋅,⋅) 可以是
L
1
L_1
L1 损失等相似性度量函数。
2.4 Output Consistency Loss
2.4.1 目的
为了确保最终输出在语义上保持一致,论文引入输出一致性损失,使得两个支路最终得到的预测结果 Y t e x t Y_{text} Ytext 与 Y t i m e Y_{time} Ytime 在输出空间上尽可能接近。
2.4.2 定义
输出一致性损失简单定义为:
L
o
u
t
p
u
t
=
s
i
m
(
Y
t
e
x
t
,
Y
t
i
m
e
)
.
L_{output} = sim(Y_{text}, Y_{time}).
Loutput=sim(Ytext,Ytime).
这样保证了无论数据来源如何,最终模型的预测输出具有一致的语义表示。
2.5 参数高效训练
- 低秩适应(LoRA):为了防止灾难性遗忘(catastrophic forgetting)以及提高训练效率,论文在时间支路中采用 LoRA 技术,仅微调低秩矩阵参数,同时对位置编码权重进行微调。
- 总损失函数:整个模型的训练目标是监督损失、特征正则化损失和输出一致性损失的加权和:
L t o t a l = L s u p + λ 1 L f e a t u r e + λ 2 L o u t p u t , L_{total} = L_{sup} + \lambda_1 L_{feature} + \lambda_2 L_{output}, Ltotal=Lsup+λ1Lfeature+λ2Loutput,
其中 λ 1 \lambda_1 λ1 和 λ 2 \lambda_2 λ2 是超参数。
3. 实验与评估
论文在多个数据集和任务场景上进行了详细的实验验证,包括长短期预测、少样本(few-shot)和零样本(zero-shot)学习,同时还对计算复杂度进行了分析。
3.1 长期预测
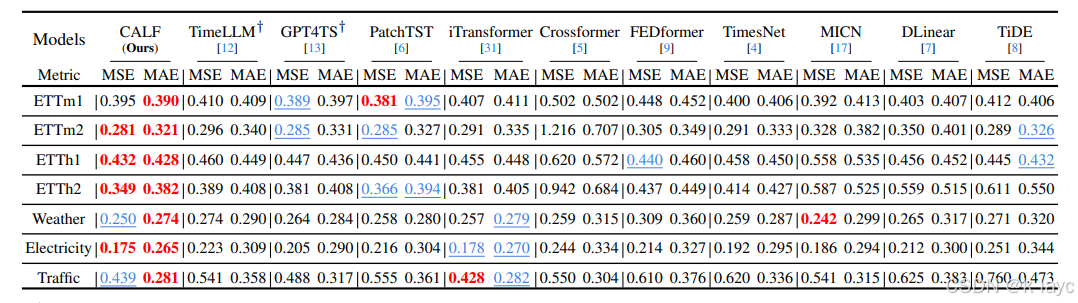
- 数据集:包括 ETT(ETTh1、ETTh2、ETTm1、ETTm2)、Weather、Electricity、Traffic 等。
- 评价指标:主要使用均方误差(MSE)和平均绝对误差(MAE)。
- 结果:CALF 在 56 个评估指标中均取得最佳表现,相比其他方法如 PatchTST 和 GPT4TS,MSE 和 MAE 均有显著下降(例如 MSE 下降 7.05%,MAE 下降 6.53%)。
3.2 短期预测
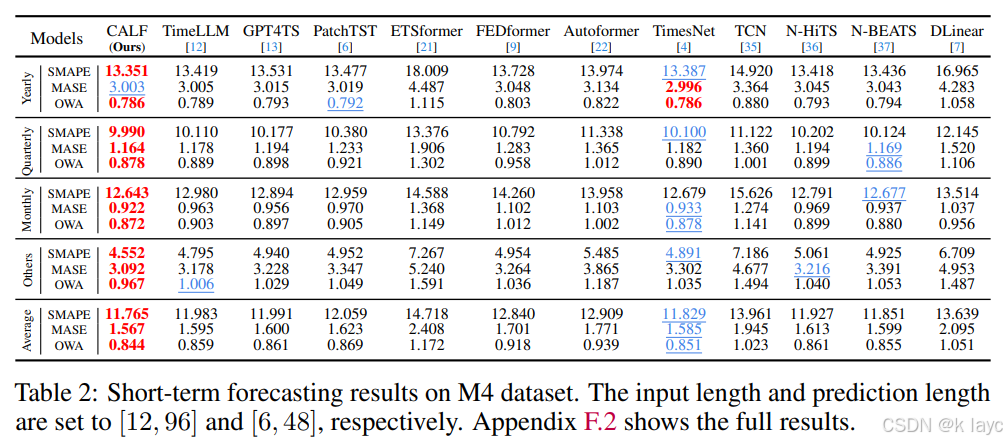
- 数据集:主要采用 M4 数据集,包括年份、季度、月份、周、日和小时级数据。
- 评价指标:使用 SMAPE、MSAE 和 OWA 等指标。
- 结果:CALF 在大部分分类任务中取得最佳结果,并在整体性能上比当前领先的模型(如 TimesNet)有约 1% 的提升。
3.3 少样本与零样本学习
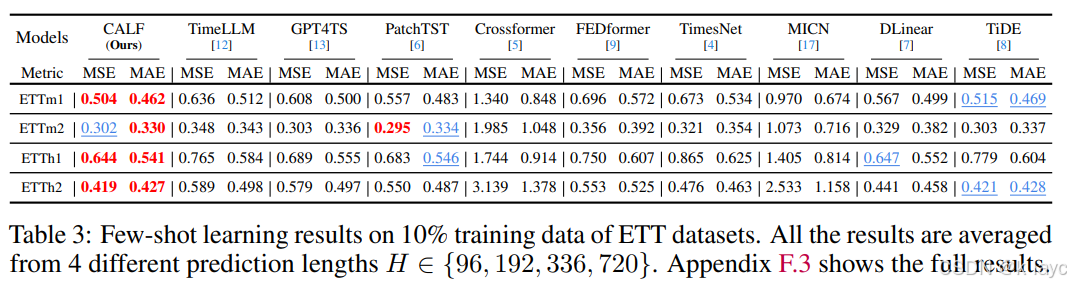
- 少样本:在 ETT 数据集上仅使用 10% 的训练数据进行实验,结果显示 CALF 比 GPT4TS 和 PatchTST 分别降低了约 8% 和 9% 的误差。
- 零样本:模型在训练于一个数据集后直接用于其他数据集测试,表现同样优于对比模型,展示了良好的跨领域泛化能力。
3.4 计算效率
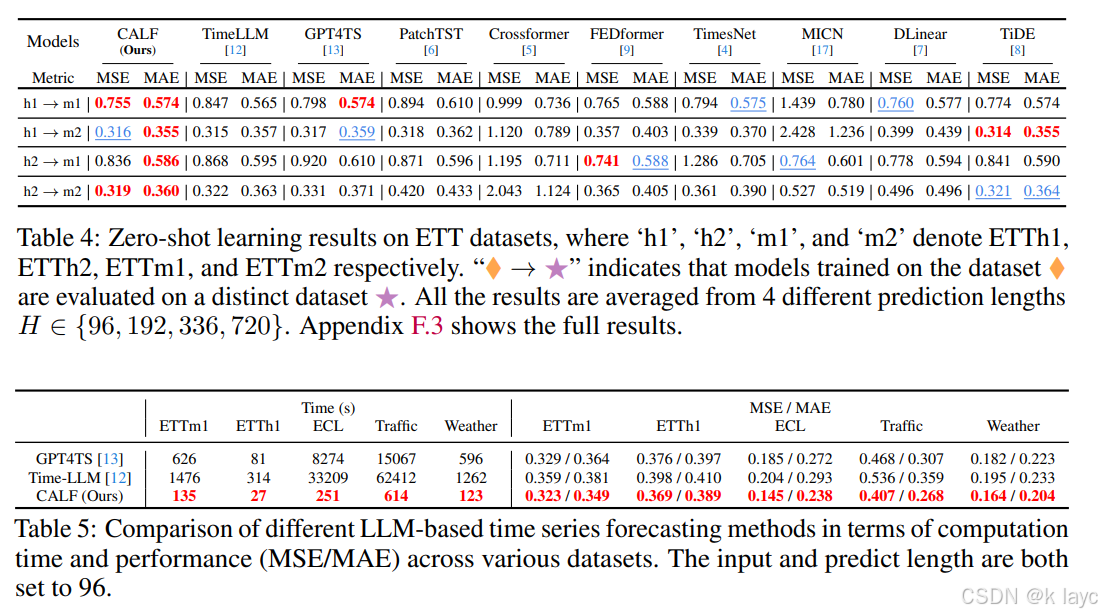
- 分析:论文在多个数据集上对比了计算时间和预测性能。CALF 相较于其他 LLM 基础的方法,如 TimeLLM 和 GPT4TS,不仅在 MSE/MAE 上表现更优,而且在计算时间上大幅减少,证明了其低复杂度优势。
4. 消融实验
论文通过一系列消融实验分析了不同损失函数及 PCA 降维中主成分数量对模型性能的影响。
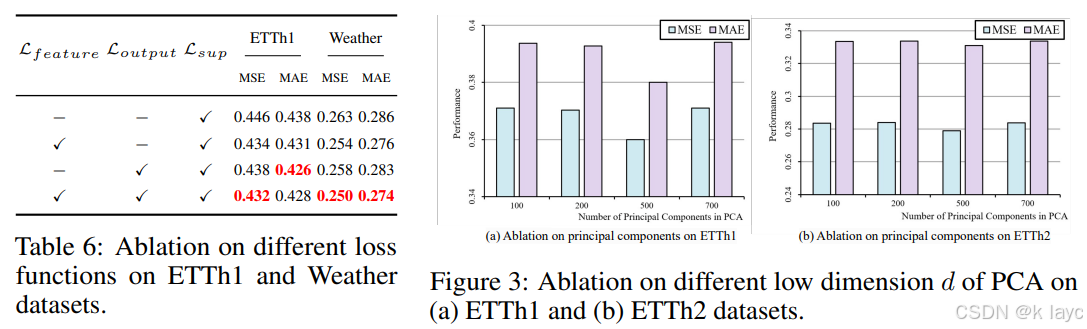
4.1 损失函数消融
- 单独使用监督损失 L s u p L_{sup} Lsup 得到的结果较差;
- 分别加入特征正则化损失 L f e a t u r e L_{feature} Lfeature 或输出一致性损失 L o u t p u t L_{output} Loutput 均有不同程度的提升;
- 最终结合三者时,模型在各项指标上均取得最优性能。
4.2 主成分数量消融
- PCA 降维后的主成分数量 d d d 对模型性能影响不敏感,但如果 d d d 过小则信息不足,过大则可能引入冗余;
- 论文实验中选取 d = 500 d = 500 d=500,能解释约 88% 的方差,同时保证了性能表现。
5. 理论分析
论文还提供了一个基于概率论的理论框架,来解释跨模态对齐的合理性:
- 定义领域:将时间序列目标领域定义为 D T = { p ( y T ∣ X T ) p ( X T ) , P ( y T ) } D_T = \{p(y_T|X_T)p(X_T),\, P(y_T)\} DT={p(yT∣XT)p(XT),P(yT)},文本源领域定义为 D S = { p ( y S ∣ X S ) p ( X S ) , P ( y S ) } D_S = \{p(y_S|X_S)p(X_S),\, P(y_S)\} DS={p(yS∣XS)p(XS),P(yS)}。
- 对齐目标:
- 输入对齐:通过 Cross-Modal Match Module 对齐 p ( X T ) p(X_T) p(XT) 与 p ( X S ) p(X_S) p(XS);
- 条件分布对齐:利用特征正则化损失使 p ( y T ∣ X T ) p(y_T|X_T) p(yT∣XT) 与 p ( y S ∣ X S ) p(y_S|X_S) p(yS∣XS) 接近;
- 输出对齐:使用输出一致性损失使得 P ( y T ) P(y_T) P(yT) 与 P ( y S ) P(y_S) P(yS) 保持一致。
这种从边缘分布和条件分布同时进行对齐的策略,从理论上保证了模型在不同模态间的迁移能力和泛化性能。
6. 讨论与未来工作
6.1 与其他工作对比
- 方法差异:相较于一些并行工作的跨注意力方案,CALF 更侧重于通过离线生成同义词聚类(利用 PCA 降维)来降低计算成本,同时在两个支路间进行特征和输出层面的严格对齐。
- 优点:该方法不仅在准确率上优于现有模型,而且在计算资源上更加高效。
6.2 解释性与局限性
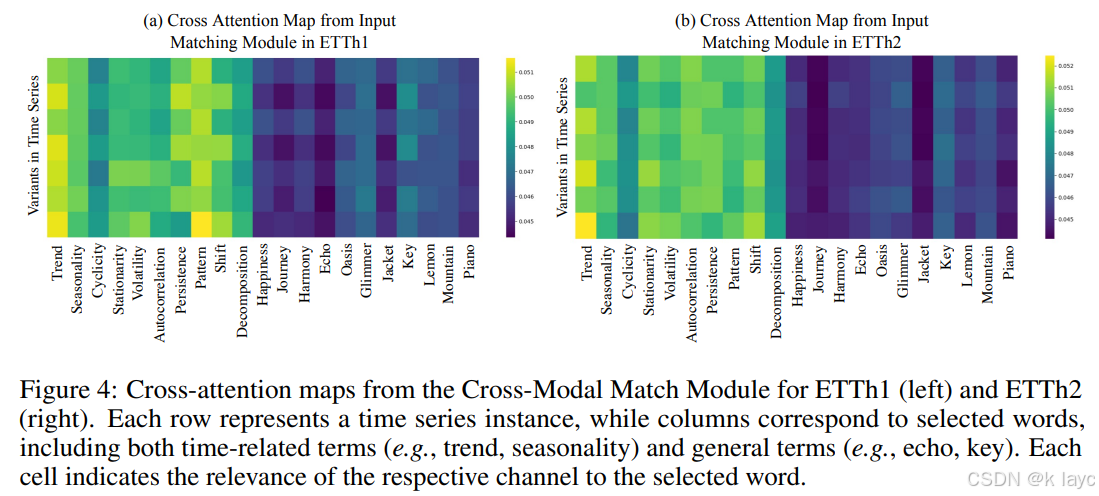
- 解释性:通过可视化跨注意力图,论文展示了时间序列 tokens 能够有效地与描述时间特征的文本词语(如 trend、seasonality 等)进行对齐,增强了模型的解释性。
- 局限性:当前方法主要依赖于隐式对齐,未来可以探索如何更好地利用 LLM 的显式文本推理能力,进一步融合文本语义知识。
7. 结论
论文提出的 CALF 框架通过跨模态微调技术成功地将预训练 LLM 的知识迁移到时间序列预测任务中。主要贡献包括:
- 发现并解决了文本与时间序列输入之间的分布不匹配问题;
- 设计了跨注意力模块、特征正则化损失和输出一致性损失,实现了全面的模态对齐;
- 在多个数据集和任务场景中证明了 CALF 在精度、泛化能力以及计算效率上的优势。
总体来说,该工作为利用 LLM 进行时间序列预测提供了一个新的思路,并为未来更深层次的跨模态知识整合奠定了基础。

















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









