







1、前言
在监督学习中,通过比较模型预测结果与实际标签之间的差异来评估模型的性能。但像聚类这种无监督学习任务,没有数据标签,如何衡量聚类的效果呢?
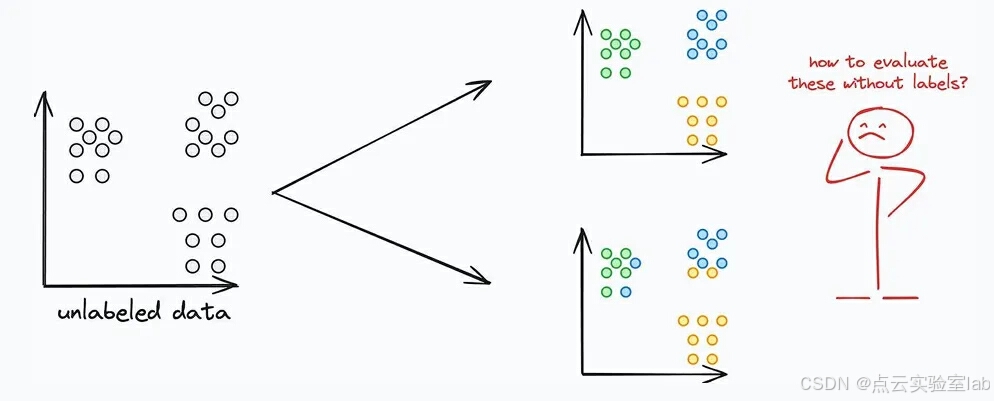
2、评价指标系数介绍
因为很多聚类数据都是高维的,所以没办法直接通过可视化方法进行验证。因此,我们必须找到一种度量指标来判断聚类的质量。
有了度量指标可以这样用它:
● 假设我正在使用KMeans算法:
○ 在一系列k值范围内运行KMeans。
○ 评估性能。
○ 选择具有最佳性能指标的k值。
接下来让我们认识几种常用的指标。
2.1 轮廓系数(Silhouette Coefficient)
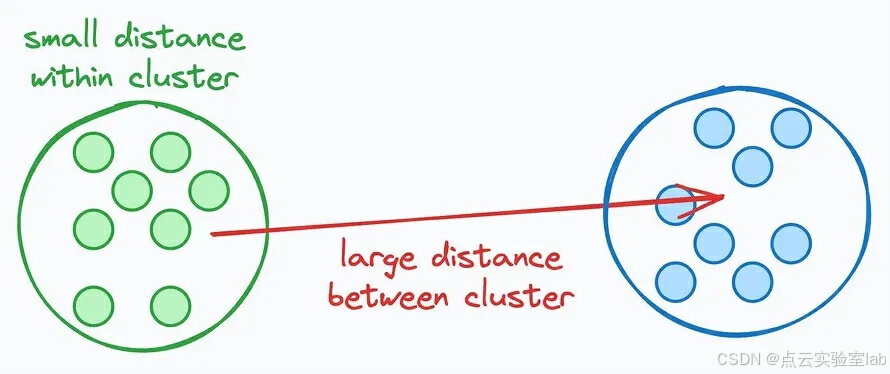
轮廓系数(Silhouette Coefficient)结合了聚类的紧密性(同一簇内的数据点彼此靠近)和分离性(不同簇之间的数据点彼此远离),提供了一个综合性的评价指标。
它的计算方法如下:
● 对于每个数据点:
○ 计算其到同一聚类中所有其他点的平均距离→A
○ 计算其到最近聚类中所有点的平均距离→B
○ 该点的得分=(B-A)/max(B,A)
● 计算所有数据点得分的平均值以获得整体聚类得分。
轮廓系数的值介于 -1 和 1 之间,值越大表示聚类效果越好。
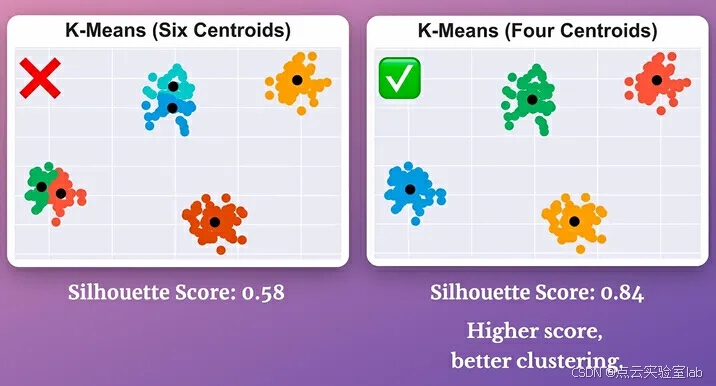
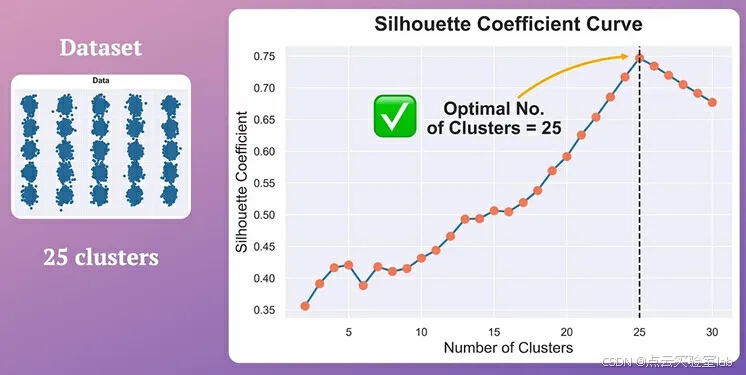
通常用它选择最佳的k值。
2.2 Calinski-Harabasz指数
轮廓系数(Silhouette score)的问题在于,其时间复杂度随着数据点数量的增加而呈二次方增长。
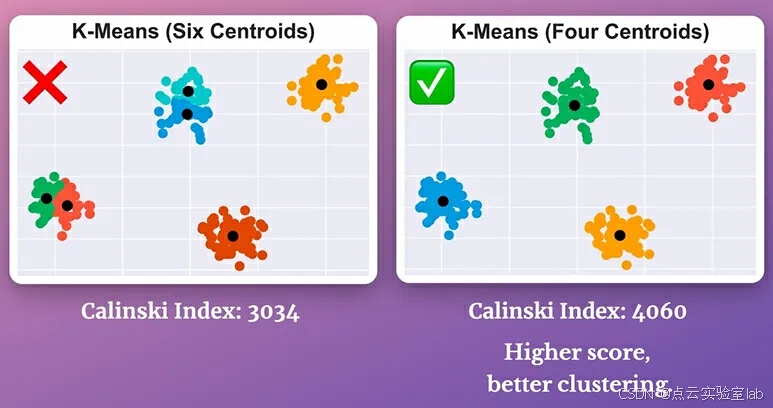
Calinski-Harabasz 指数是另一个与轮廓系数非常相似的聚类质量评估指标。
它的计算方式如下:
● A → 所有质心与整个数据集中心之间的平方距离之和。
● B → 所有点与其所属质心之间的平方距离之和。
● 用A/B 来计算性能指标(还有一个额外的缩放因子)。
如果A远大于B:
● 质心到数据集中心的距离很大。
● 数据点到其特定质心的距离很小。
● 因此,这将得到一个更高的分数,表明聚类是很好地分离的。
我更愿意选择Calinski-Harabasz 指数的原因在于,与轮廓系数相比,可解释性与其相同,但它运行速度更快。
2.3 DBCV
前两个指标的问题在于,它们通常对于凸形(或某种程度上球形)的聚类得分偏高。
将它们用于评估任意形状的聚类(例如通过基于密度的聚类方法得到的聚类)可能会得出误导性的结果。这一点从下面的图像中可以明显看出:
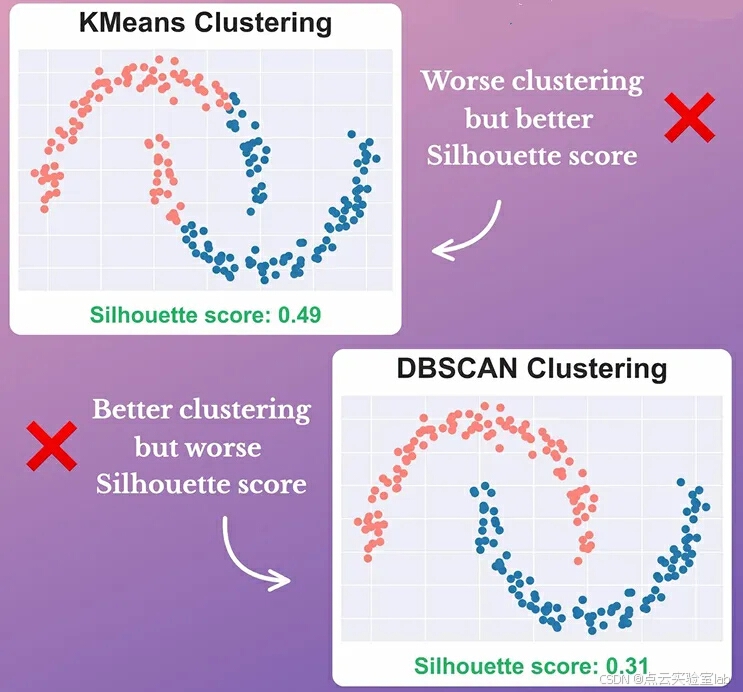
如上图所示,尽管KMeans的聚类输出结果更差,但其轮廓系数仍然高于基于密度的聚类。
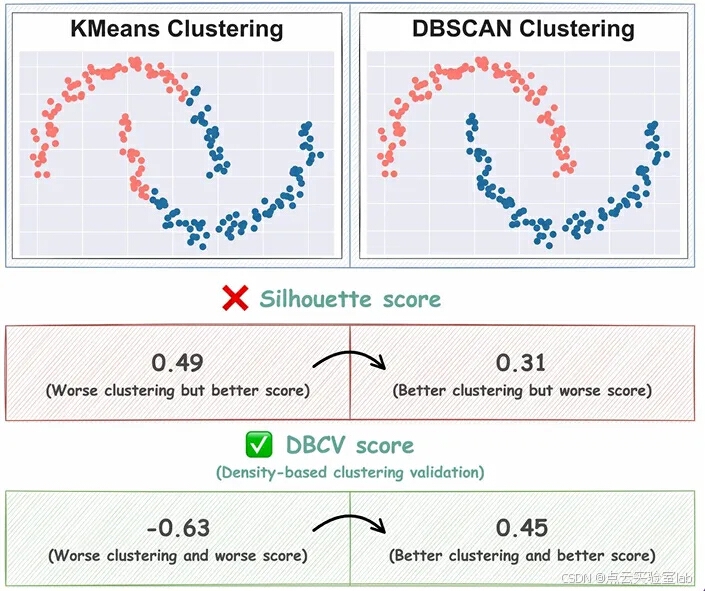
DBCV(density-based clustering validation)是这种情况下更好的度量标准。
顾名思义,它专门用于评估基于密度的聚类。
简而言之,DBCV计算两个值:
● 聚类内的密度
● 聚类之间的密度重叠
聚类内的高密度和聚类之间的低密度重叠表明聚类结果良好。
DBC的有效性也可以从下面的图像中明显看出:
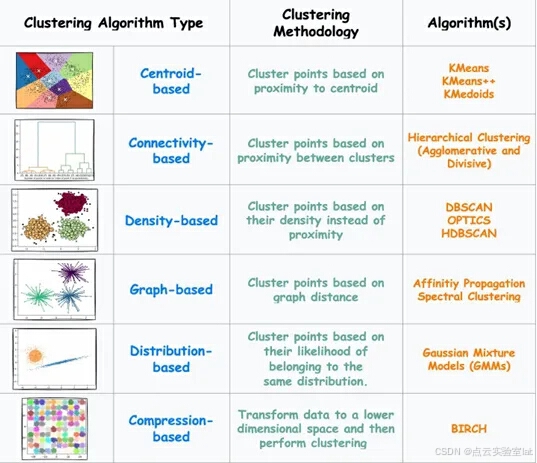
3、常见几种聚类算法
参考内容:
【1】聚类算法的评估指标


















 2814
2814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











