









【Apollo 论文】Exploring Imitation Learning for Autonomous Driving with Feedback Synthesizer and Differentiable Rasterization
一、总览
核心关键点:Mid-to-mid approach for planning,feed back synthesizer for data augmentation,spatial attention mechanism
拟解决的问题:Imitation Learning 中 distributional shift,variation in input state distribution
解决思路:设计feed back synthesizer用于增强数据以及spatial attention机制
最终效果:70个测试场景通过率70%,对超越动态车辆、红灯路口场景非常有效(针对目前的规划框架而言)
二、具体方法:
(1)总体流程
TODO:绘制一下pipeline的流程图
(2)模型设计

输入端:多通道BEV Image(鸟瞰图),WxH大小,
ρ
\rho
ρm/pixel,以Ego为中心的对整个世界的感知、预测的建模。如下图所示,每一层BEV图像对不同的数据单独处理,包含自车的bounding box,自车历史姿态数据,障碍物预测数据,障碍物历史数据,删格化的HD map,Routing的Passage,限速信息以及Traffic light

模型结构:
TODO:使用deep learning工具对开源的模型进行可视化
CNN+Spatial Attention模块:
- CNN backbone使用MobileNetV2:精度和推理速度能够平衡
- MLP多层感知机:将CNN输出的特征
F
h
F_h
Fh转化为平坦特征
h
0
h_0
h0,作为后续LSTM的初始隐藏状态
- CNN中间输出特征
F
i
F_i
Fi输入至Spatial Attention分支,输出注意力特征
F
A
F_A
FA,该特征再通过
f
(
e
n
c
o
d
i
n
g
)
f(encoding)
f(encoding)编码模块输出向量
A
i
A_i
Ai、
LSTM模块:
- 输入:
c
0
c_0
c0为初始化的状态,使用Glorot初始化后的输出;上层MLP提取的平坦特征
h
0
h_0
h0,以及空间注意力机制分支通过
f
(
e
n
c
o
d
i
n
g
)
f(encoding)
f(encoding)编码的输出
A
i
A_i
Ai,以及上次迭代处理后的
S
t
S_t
St
- 输出:输出结果再通过一个MLP多次感知机提取出未来的序列化方向盘转角和加速度控制量
(
δ
i
,
a
i
)
(\delta_i, a_i)
(δi,ai),利用运动学模型(差分模型)转化为
(
x
i
,
y
i
,
ϕ
i
,
v
i
)
(x_i, y_i, \phi_i, v_i)
(xi,yi,ϕi,vi)序列,转化方法:
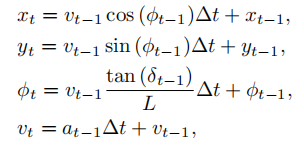
差分栅格化:
这一步主要是了解决如何表示车辆的问题,在栅格图中难以用一个bounding box的属性来描述车辆,因此需要合理设计对车辆的描述。

使用三个2D Gaussian Kernel描述一个车辆,并且这些Kernel并不会受bounding box的强约束,通过合理设计Kernel可以使得训练过程中,让机器学习像人一样在开车过程中保持与其他障碍物的一定距离。
损失函数:
1.与真实轨迹数据的损失偏差:
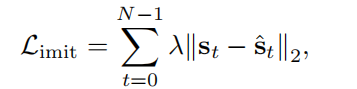
2.发生碰撞、偏离Routing、偏离道路、错误响应信号灯的偏差:

3.合成最终偏差:
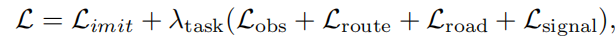
(3)数据增强
这一部分主要是解决Learning-based存在的关键问题,即如何保证数据的有效性,从而避免训练模型失真。
1.随机合成器
通过控制轨迹的起点和终点,随机的给原始轨迹给定偏差,通过曲率阈值量筛选出有效的轨迹,从而增强部分数据集。
2.反馈合成器
由于随机合成器存在随机的性质,本质上很难保证数据增强的“方向性”,因此需要设计一个满足一定规则的合成器来使得数据增强更有效。
核心算法:

效果示意图:

对状态采样并通过运动学约束,形成了更多的轨迹数据,并且对轨迹的评价和筛选可以自动化完成(设计好规则和cost,可以自动排除)
(4)后处理规划方法
核心步骤:

Mid-to-Mid的方法核心还是需要后续的优化处理,优化的boundaries仍然按照规则去生成,只是优化的参考量变成了Learning-based的输出轨迹。
三、实验结果
(1)实验细节:
鸟瞰图参数:大小W=200,H=200, 0.2m/pixel
数据来源:Apollo感知预测模块给出的目标检测结果、跟踪结果以及预测结果
轨迹时间长度:记录2s的历史轨迹信息和2s的预测轨迹信息
输出轨迹时长:N=10s,每dt=0.2s一个点
训练细节:Adam Optimizer进行训练,初始Learning rate为0.003
(2)数据集及增强数据集
400小时人开的数据->生成250K帧的训练集
生成400K帧随机合成增强数据,反馈步长为5的465K帧反馈合成增强数据
(3)场景评估
Crusing、Junction、Static Interaction、Dynamic Interaction


结合原有的框架,场景数据集通过率94.29%,但是没有说不加Learning-based通过率是多少
(4)评估指标

对于舒适分数的评价通过查看Learning-based输出的Jerk以及角速度落在真实数据的比例,这里假设的人开的数据是舒适的。
(5)运行情况
设备:Nvidia Titan-V GPU, i7-9700K CPU,16GB内存
时间消耗:每一帧10ms render,22ms model inference,15ms 后续规划
【Apollo Imitation 开源代码】
一、框架大纲:
特征Feature设计:
Overlap:id、距离
Chassis:时间戳、速度、节流阀、刹车、转向、档位
Localization:时间戳、位置、朝向、速度、加速度、角速度
Trajectory:时间戳、轨迹点(x, y, theta, s, lane_id, v, a, relative_time, guassian_info)
PerceptionObstacle:时间戳、位置、theta、速度、加速度、包围盒
PredictionObstacle:时间戳、预测时间、意图、优先级、是否静态、预测轨迹
Obstacle:id、长宽高、类型、轨迹、预测轨迹
Routing:routing_response,local_routing_lane_id,local_routing
TrafficLight:时间戳、颜色、id、置信度、跟踪时间、是否闪烁、剩余时间
ADCTrajectory:时间戳、标签、轨迹点
PlanningTag:lane_turn、clear_area、crosswalk、pnc_junction、signal、stop_sign、yield_sign
开源的Learning-based模式:
1.E2E:端到端的训练和输出轨迹
2.RL:强化学习方法
3.Hybrid:将E2E的结果作为初始解,随后再利用原有基于优化的方法继续求解
调用方法:
在scenario中新增了两个场景,通过配置文件将给定场景读入即可:
1.Lane_follow_hybrid:Hybrid模式
2.Learning_model_sample:E2E模式
Learning-based方法整体pipeline:
训练:接收数据->数据处理->按规则提取特定的特征->离线训练(具体处理细节暂时未找到)
推理:接收数据->数据处理->按规则提取特定的特征->在线处理时间戳并转化为Img->输入网络推理
二、框架细节:
数据处理类MessageProcess:
功能:在线提取当前帧接收到的消息,转化为特征;离线读取数据转化为特征
条件:离线学习+在线learning模式时需要启用
输出:在线运行输出injector->learning_based_data();离线输入到文件
Scenario-Lane_follow_hybrid:
相比于Lane_follow_scenario多了两个task:
1.learning_model_inference_task:主要为在线模型推理的接口task,完成数据feature转化为img feature的过程
主要由以下关键步骤组成:
①TrajectoryEvaluator
1.Evaluate adc trajectory:先前自车定位的结果记录为轨迹,再把记录的轨迹点转化为特征,并且按dt对齐
2.Evaluate obstacle trajectory:将历史障碍物的位置记录为障碍物的轨迹,同样将轨迹点转化为特征,并按dt对齐
3.Evaluate obstacle prediction trajectory:把预测结果转化为特征,并按dt对齐
②Trajectory imitation:用的是libtorch,网络用CNN或者CNN LSTM
1.载入模型,调用的是libtorch库
2.BirdviewImgFeatureRender:将EgoPastPoint、ObsPastBox、ObsFutureBox、LocalRoadMap、Routing、SpeedlimitMap、TrafficLight转化为cv::Mat形式,然后合并到一个cv::Mat里
3.调用模型
4.处理output:输出轨迹点的dx, dy, dtheta, v, x, y, heading
③Evaluator:
1.Evaluate输出的轨迹转化成的feature,对齐时间再转化为轨迹
2.path_reference_decider_task:判断推理的轨迹结果是否合理,转化为后续优化求解的初始解
Scenario-Learning_model_sample:
纯端到端的场景,输入输出一步到位
1.learning_model_inference_task:同上
2.learning_model_inference_trajectory_task:将结果转化为可执行的规划轨迹
三、实现效果
实际运行效果:
无法上传视频
四、最终可行性分析
需要做的工作:
1.模型复现
这部分咨询了相关深度学习同学,按照目前的框架来说难度不大,主要是其中一些多层感知机如何实现需要自己钻研,其次是一些编码器需要设计,这部分暂时没找到对应的开源成果,Tesla的ChauffeurNet可以作为参考,其已经开源了
2.数据采集
采集的数据也比较明确,同时开源部分的数据处理也已有现成可以用的东西了,可能难度在于感知、预测的准确性以及自车规划轨迹的真值性,这部分没有用到仿真器的数据,不知道如何保证真值可靠
3.数据增强
增强方法还是比较简单,生成一堆数据比较容易,难得是怎么挑选出合理的增强数据,以及怎么保证增强数据一些参数比如舒适度是否计算正确
4.训练和调参
炼丹过程比较困难,特别是上文提到的损失函数,两个参数细节并没有太多工程上的调试描述
5.运行和部署
总体运行和推理时间还是可以接受的,但是通过率这部分描述的比较含糊,如果已有的场景都不能100%通过,那其实没有任何意义,因为网络不具有可解释性,很难确保调参对结果的指导意义,有可能网络本身就不可能100%通过














 1471
1471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









