







灾难性遗忘/增量学习的研究现状
- 一. 灾难性遗忘(catastrophic forgetting)为什么会发生?
- 二. 增量学习的概念
- 三. 增量学习的方法
- 3.1. 基于正则化的增量学习(基于Loss) --《Learning without Forgetting》 (ECCV 2016) LwF
- 3.2. 基于正则化的增量学习(基于参数约束) --《Overcoming catastrophic forgetting in neural networks》 (PNAS 2017) EWC
- 3.3. 基于回放的增量学习 --《iCaRL: Incremental Classifier and Representation Learning 》 (CVPR 2017)
- 3.4. 基于参数隔离的增量学习 --《PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning》
- 3.5. 基于生成数据的增量学习 --《PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning》
- 三. 方法的对比
主要参考文献:《A continual learning survey: Defying forgetting in classification tasks》
知乎:增量学习(Incremental Learning)小综述
一. 灾难性遗忘(catastrophic forgetting)为什么会发生?
灾难性遗忘,是指在新的数据集上训练模型,会遗忘掉旧数据上学习到的知识,在旧数据上测试会发生很大的掉点
- 场景:
- 相同任务,数据集不同,新数据和旧数据相似度高:finetuning效果可以
- 相同任务,数据集不同,新数据和旧数据相似度低:出现灾难性遗忘
- 不同任务或者有新增任务:出现灾难性遗忘
- 分析:
- 同一个网络,学习完一个任务后的权重,在学习新的任务的时候可能完全变化掉,由于不同任务的最优化的目标往往不同,即使目标函数相同数据集也不同,旧的权重被毁坏是完全有可能的
- 但理论上,两者是可以实现重用的,需要分清楚两个任务目标能否找到一个基础网络层,这种解决方案就是常见的多任务学习。
- 但多任务学习的一个问题是随着任务的增多,新的任务目标越来越难训练,因为多个loss累加在一起,后加入的loss被优化的压力慢慢会变小,优化的压力会分摊到所有的loss上,而且这样也会带来训练上的成本,如果能在训练完一个任务后,再训练一个新任务,而老任务学到的东西不会遗忘就好了,这就产生了增量式学习的概念,也叫持续学习。
增量学习和持续学习(Continual Learning)、终身学习(Lifelong Learning)的概念大致是等价的
二. 增量学习的概念
2.1. 研究领域
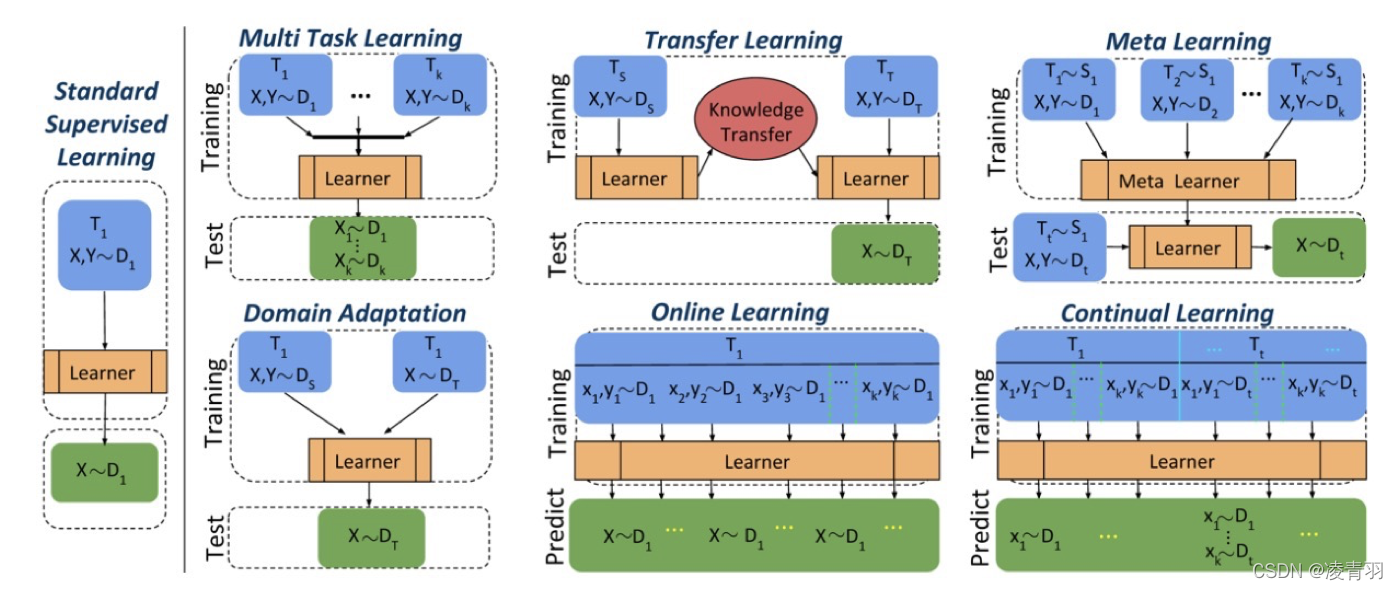
- 多任务学习(
Multi Task Learning):k个训练数据集: D 1 D_1 D1 到 D k D_k Dk(k个任务),k个对应的测试数据集,旨在能够学到k个任务的知识 - 迁移学习(
Transfer Learning):在 D s D_s Ds数据集上训练模型,旨在利用学到的知识(参数),在 D T D_T DT数据集上继续训练,能够准确地识别 D T D_T DT数据集 - 元学习(
meta Learning):将数据集分 D 1 D_1 D1~ D k D_k Dkk份数据集,旨在学习到任务之间的共性,能够识别 D t D_t Dt数据集的物体(一般在运用于小样本学习(few shot learning)中) - 跨域学习(
Domanin Adaptation):同时在 D s D_s Ds和 D T D_T DT数据集,相当于扩产了外部数据集 D s D_s Ds,帮助学习 D T D_T DT,旨在能够更好的识别 D T D_T DT - 在线学习(
Online learning):每次只能学习当前数据集 D 1 D_1 D1的一部分,每个样本只能学一次,旨在越学,越能更好地识别 D 1 D_1 D1数据集 - 持续学习(
Continual Learning):每次学习一堆数据集,从 D 1 D_1 D1到 D t D_t Dt,旨在还能识别上一次数据集
2.1. 增量学习的上下限
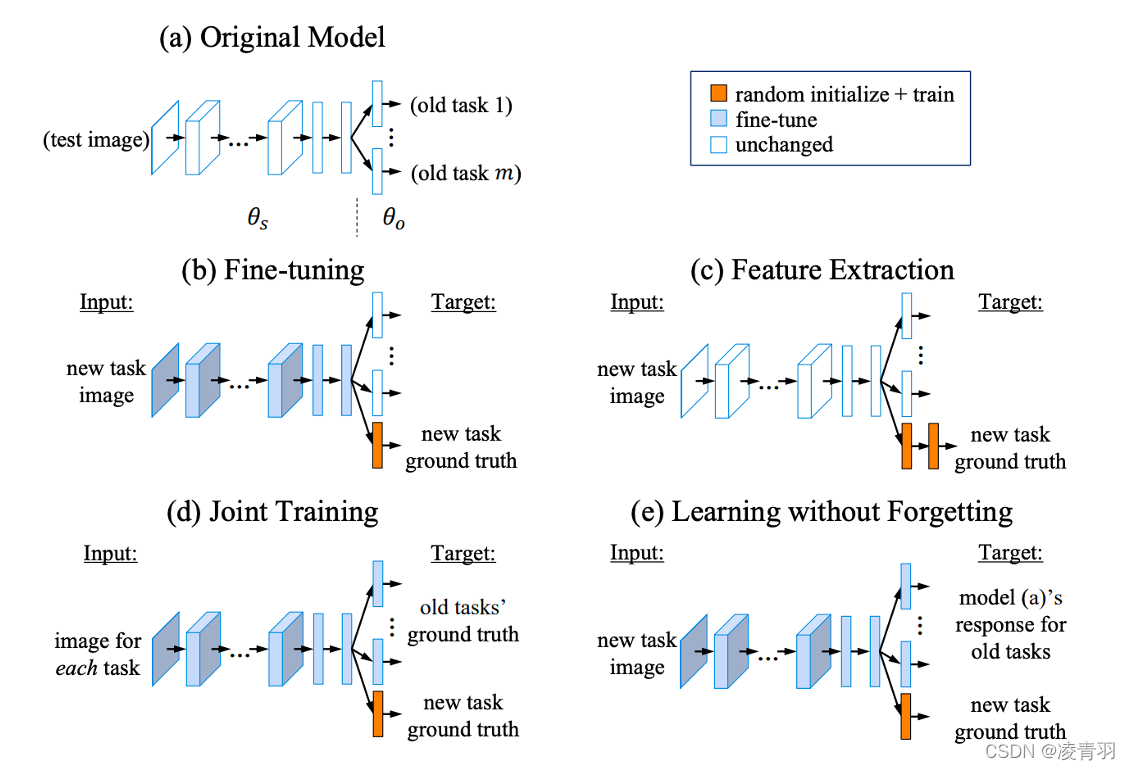
- (a)
Original Model:旧数据上训练的原模型 - (b)
Fine-tuning:不用旧数据,在新数据上继续训练,增量学习的上限 - (c)
Feature Extraction:特征提取,只更新新任务的参数 - (d)
Joint Training:联合训练,将旧数据全部加入新数据集中,一起训练模型,增量学习的上限 - (e)
Learning without Forgetting:增量学习,在新的数据集上,用部分旧数据或者不用,用策略,继续训练模型,尽量保持在旧的数据集上识别能力
增量学习和在线学习的区别:在线学习通常要求每个样本只能使用一次,且数据全都来自于同一个任务,而增量学习是多任务的,但它允许在进入下一个任务之前多次处理当前任务的数据
三. 增量学习的方法

3.1. 基于正则化的增量学习(基于Loss) --《Learning without Forgetting》 (ECCV 2016) LwF

核心操作:LwF算法先得到旧模型CNN(
θ
s
\theta_s
θs,
θ
0
\theta_0
θ0)在新任务
X
n
X_n
Xn上的预测值
Y
0
Y_0
Y0,在损失函数中引入新模型输出的蒸馏损失
L
o
l
d
L_{old}
Lold,然后用微调的方法(先冻结
θ
s
\theta_s
θs和
θ
0
\theta_0
θ0,训练
X
n
X_n
Xn,然后再联合训练)在新任务上训练模型,从而避免新任务的训练过分调整旧模型的参数而导致新模型在旧任务上性能的下降 .
公式如下:
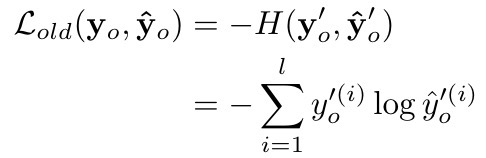
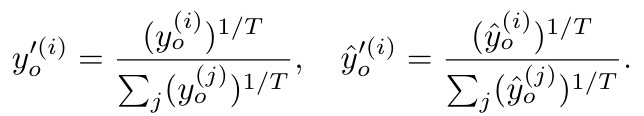
![]()
l是类别label数量- 建议
T>1,会鼓励更好的学习到类间的相似性 - λ 0 \lambda_0 λ0是权重,大多数实验设置为1
R是正则化项
方法缺点:高度依赖于新旧任务之间的相关性,当任务差异太大时会出现任务混淆的现象(inter-task confusion),并且一个任务的训练时间会随着学习任务的数量线性增长,同时引入的正则项常常不能有效地约束模型在新任务上的优化过程
3.2. 基于正则化的增量学习(基于参数约束) --《Overcoming catastrophic forgetting in neural networks》 (PNAS 2017) EWC
- 论文链接:https://arxiv.org/pdf/1612.00796v2.pdf
- 代码链接:https://github.com/ContinualAI/avalanche

目的:如上图,首先我想得到一个能够识别新任务task B,且能识别旧任务task A的模型,相当于能够模型学到task A与task B的公共解,这个解应该是存在的(我们将task A与task B合在一起训练,得到的解便是公共解),如果我们不加限制,就和蓝箭头一样,新训练的模型在task A上的准确率不足,如果我们对每个权重施加L2惩罚,会出现绿箭头的情况,因为所有权重都不能发生太大改变,模型无法充分学习task B,EWC的目标即为红箭头,此类做法和knowledge distillation的本质基本一致,只是做法不同
核心操作:利用贝叶斯求先验概率,希望求得数据集先验情况下的每个参数的概率:
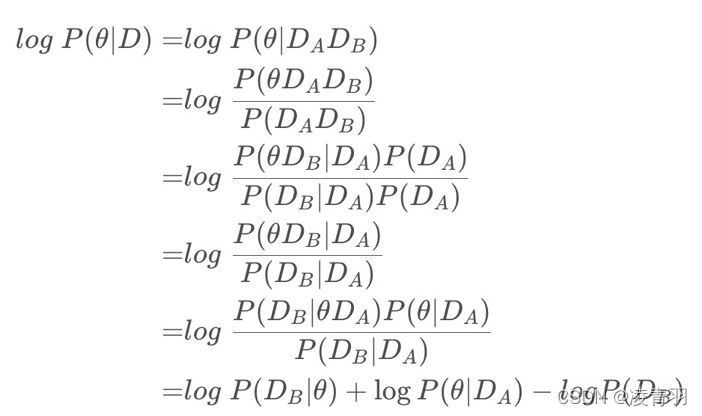
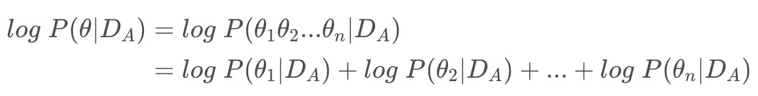
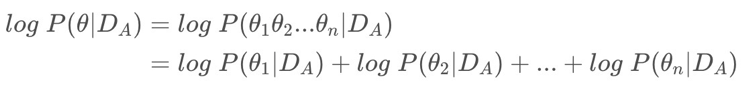
因为每个概率不好求,所以用拉普拉斯近似,在使用mini batch的前提下,则可其看成均值为
θ
A
,
i
∗
θ ^*_{A,i}
θA,i∗,方差为该参数对应的Fisher information matrix对角线上的倒数(记为
F
i
F_i
Fi)的高斯分布:
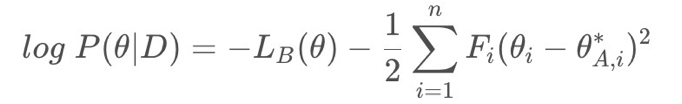
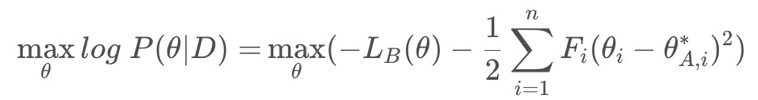
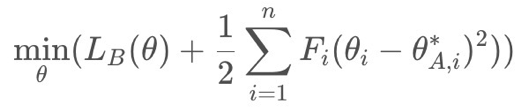
最后转化为求如下公式,即Loss:
![]()
具体可以参考这篇文章:CSDN:深度学习论文笔记(增量学习)——Overcoming catastrophic forgetting in neural networks
3.3. 基于回放的增量学习 --《iCaRL: Incremental Classifier and Representation Learning 》 (CVPR 2017)
目的:在训练新任务时,一部分具有代表性的旧数据会被保留并用于模型复习曾经学到的旧知识,因此「要保留旧任务的哪部分数据,以及如何利用旧数据与新数据一起训练模型」,就是这类方法需要考虑的主要问题
- iCaRL假设越靠近类别特征均值的样本越有代表性
- iCaRL是最经典的基于回放的增量学习模型,iCaRL的思想实际上和LwF比较相似,它同样引入了蒸馏损失来更新模型参数,但又放松了完全不能使用旧数据的限制

x是输入数据P是代表性样本集合t是样本种类的总数。- 求解当前
exemplar中,每个样本种类的均值Uy。比较输入数据与哪个样本种类的均值Uy差值最小(最接近),即把输入数据分为该样本类型。
3.4. 基于参数隔离的增量学习 --《PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning》
- 论文链接:https://arxiv.org/pdf/1711.05769v2.pdf
- 代码链接:https://github.com/arunmallya/packnet

- 训练:整体训练,之后剪枝,为了弥补剪枝带来的损失会再针对剪枝后网络进少轮次训练,任务二训练时会利用任务一的参数,但不改变他们。
- 剪枝:针对每个任务的子网络的权重进行排行,最低的百分之五十或者其他阈值被剪掉。
- 测试:使用预先存储的对应每个任务的记录矩阵对 filter 参数执行 mask,即任务 1 使用 b 图去预测。
3.5. 基于生成数据的增量学习 --《PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning》
也有一些工作将VAE和GAN的思想引入了增量学习,比如Variational Continual Learning (ICLR 2018)指出了增量学习的贝叶斯性质,将在线变分推理和蒙特卡洛采样引入了增量学习,Continual Learning with Deep Generative Replay (NIPS 2017)通过训练GAN来生成旧数据,从而避免了基于回放的方法潜在的数据隐私问题,这本质上相当于用额外的参数间接存储旧数据,但是生成模型本身还没达到很高的水平,这类方法的效果也不尽人意。
三. 方法的对比

数据集:ImageNet有200类,每类包含500个样本,分为培训(80%)和验证(20%)以及50个用于评估的样本。为了构建一个平衡数据集,在10个连续任务的序列中,每个任务分配20个随机选择的类。
- 图说明:
- 上面的图是基于正则化的方法
LwF、、EBLL(data-focud)、EWC、MAS、IMM(prior)和基于参数隔离的方法PackNet SI:33.93(15.77):33.93代表10次实验的AP均值,15.77代表相对于联合训练遗忘的AP- 下面的图是基于回放的方法
GEM、iCaRL,iCaRL 9k是iCaRL 4.5k用的旧数据多一倍 T1~T10:连续的10个任务
- 上面的图是基于正则化的方法
- 效果对比:
PackNet总体表现最好,只用了总模型的一部分参数MAS和iCaRL次之- 与两种相关方法
EWC和SI相比,MAS对超参数值的选择更具鲁棒性 - 与
Tiny Imagenet上的EWC相比,SI表现不佳 IMM与其他持续学习策略相比似乎没有竞争力

- 图说明:
33.93(15.77):33.93代表10次实验的AP均值,15.77代表相对于联合训练遗忘的AP,负数,代表策略效果比联合训练还好
- 效果对比:
Small Model:SI和finetuning遗忘的AP大于20,效果很差,EWC(绿色下划线)得益于小模型,效果更好WIDE model:SI明显好于EWC,LwF、EBLL和PackNet在使用WideModel时达到最高性能BaseModel:SIP在WideModel和Base Model上的性能最稳定。IMM在使用Base和WideModel时也表现出了更高的性能。DEEP Model(金黄色框):iCaRL在优于所有持续学习方法,MAS和iCaRL次之- 与两种相关方法
EWC和SI相比,MAS对超参数值的选择更具鲁棒性 - 与
Tiny Imagenet上的EWC相比,SI表现不佳 IMM与其他持续学习策略相比似乎没有竞争力
- 总结
- 基于正则化的方法,适合小模型
- 基于参数隔离的方法,适合大模型
- 基于回放的方法,适合深度模型



















 176
176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











