










目录
4.1 两个智能体协作( Two-agent Collaboration)
4.2 单智能体回环(Single Agent with Loop)
姿态图优化(Pose Graph Optimization)
内存和运行时分析(Memory and Runtime Analysis)
接上篇
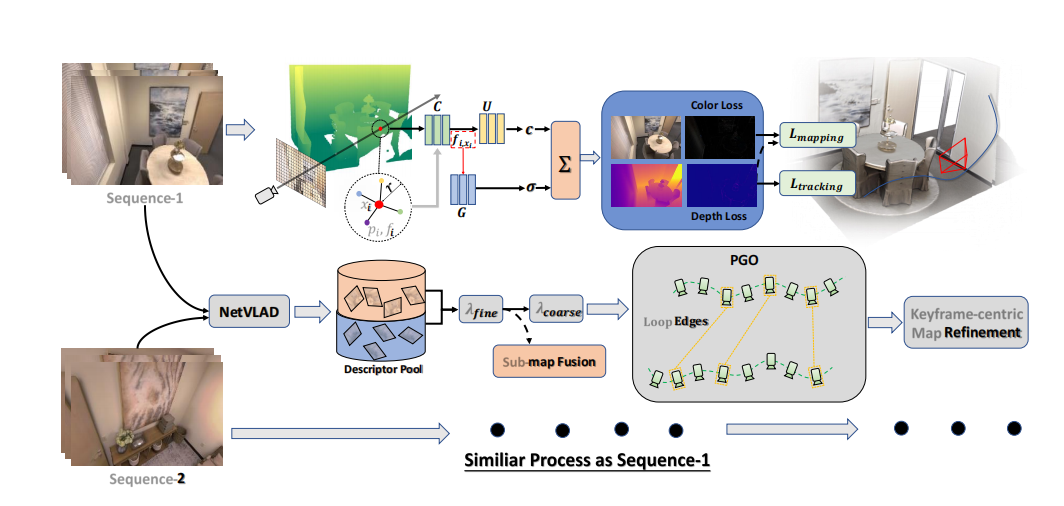
4 CP-SLAM 实验
CP-SLAM系统支持单一智能体和多智能体模式。因此,我们在两个方面评估了我们提出的协作SLAM系统,即带有闭环的单一智能体实验和包含不同大小和复杂性的两个智能体实验。
对于单一智能体方面,我们基于Replica [35]场景生成数据集,然后将我们的方法与最近的神经和传统RGB-D SLAM方法进行比较。对于两个智能体方面,由于迄今为止还没有出现协作神经SLAM工作,我们的方法与传统方法进行比较。我们还进行了消融研究,以展示所提出系统中各模块的重要性。
实施细节(Implementation Details)
CP-SLAM系统在NVIDIA RTX3090 GPU上运行RGB-D序列。在两个智能体实验中,我们需要额外的RTX3090作为中央服务器。为了在推断期间对原始邻居特征fi和相对距离∥pi−x∥施加位置编码,我们使用1和7的顺序。我们利用FRNN库在GPU上查询K = 8个最近邻居。在我们的所有实验中,我们设置Nnear = 16,Nuni = 4,λ1 = 0.2,Dl = 0.001m,r = 0.15m,ρ = 0.14m,M1 = 3000,M3 = 3136,M2 = 1500。我们每50帧提取一个关键帧,并每10帧执行一次地图优化和点云补充。对于单一智能体实验,我们对神经场进行200次迭代的优化。对于两个智能体实验,考虑到锚定在神经点上的特征在子图融合后无需从头开始训练,我们将迭代步骤的数量减少到150。更多的实现细节可以在我们的补充材料中找到。
基线(Baselines)
在单一智能体实验中,由于我们使用了渲染的闭环数据,我们主要选择最先进的神经SLAM系统,如NICE-SLAM [50],Vox-Fusion [44]和ORB-SLAM3 [4],以在闭环数据集上进行比较。对于两个智能体实验,我们将我们的方法与传统方法进行比较,例如CCM-SLAM [33],Swarm-SLAM [17]和ORB-SLAM3 [4]。
数据集(Datasets)
为了进行重建评估,我们使用了合成数据集Replica [35],配备了高质量的RGB-D渲染SDK。我们生成了8个RGB-D序列的集合,其中4个代表单一智能体轨迹,每个包含1500个RGB-D帧。其余的4个集合设计用于协作SLAM实验。每个集合分为2部分,每个部分包含2500帧,其中Office-0-C每部分包含1950帧。
指标(Metrics)
作为一种密集的神经隐式SLAM系统,我们定量和定性地测量其制图和跟踪能力。对于制图,我们评估了从我们的神经点场渲染的196个均匀采样的深度图与地面实况深度图之间的L1损失。此外,在3D三角网格方面,我们计算了网格重建精度。对于跟踪,我们使用ATE RMSE,均值和中值综合测量轨迹准确性,以防止极端异常值造成的负面影响。
ATE RMSE代表平均轨迹误差的均方根误差(Root Mean Square Error)。ATE是Absolute Trajectory Error(绝对轨迹误差)的缩写,表示实际轨迹和估计轨迹之间的平均距离误差。
RMSE是均方根误差,是一种用于度量估计值与真实值之间差异的指标。它通过计算误差的平方、取平均值,再开平方根来得到。对于轨迹误差,RMSE提供了平均误差的度量,即平均轨迹误差的平方根。
在SLAM系统的评估中,ATE RMSE通常用于衡量SLAM算法对相机轨迹的准确性。它表示在整个轨迹上,实际相机轨迹和SLAM系统估计的相机轨迹之间的平均距离误差的均方根值。ATE RMSE的值越小,表示SLAM系统的相机轨迹估计越准确。
4.1 两个智能体协作( Two-agent Collaboration)
我们提供了在四个场景(包括Replica [35]的Apartment-0、Apartment-1、Apartment-2(多房间)和Office-0-C(单房间))上进行的两个智能体实验的定量结果。我们选择RGB-CAM-SLAM [33]、RGBD-CAM-SLAM [17]和传统的ORB-SLAM3 [4]进行比较。表1报告了不同方法的定位准确性。
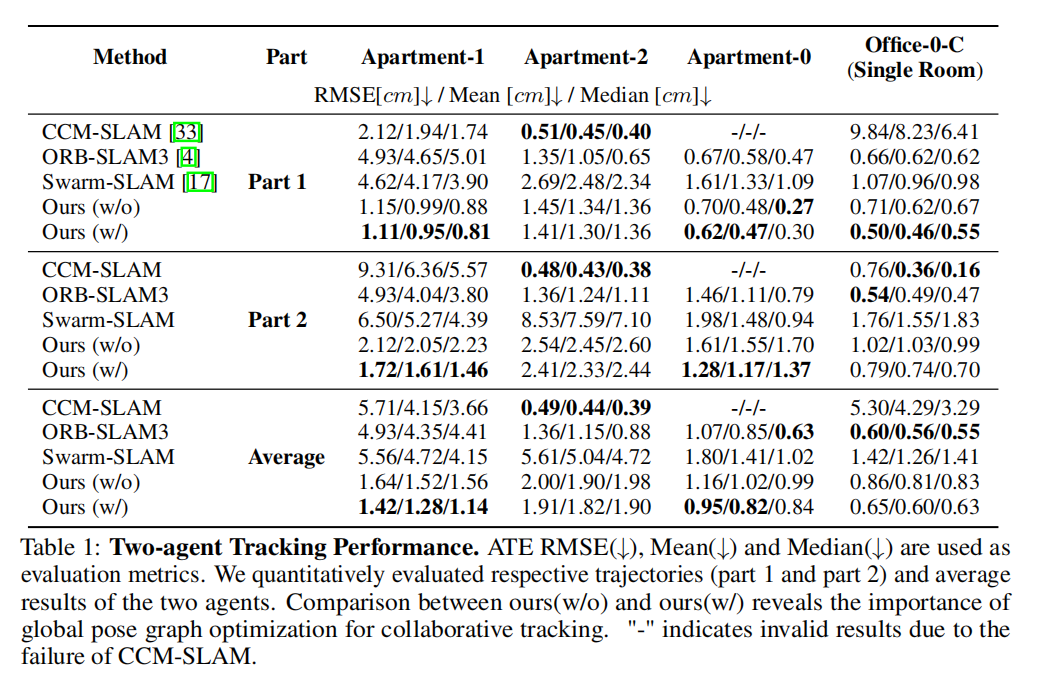
在复杂的多房间序列中,尽管受到环境的影响,提出的系统通常比其他方法表现更好。
值得注意的是,ORB-SLAM3并不是一个协作SLAM系统。它缺乏同时处理多个序列的能力,因此无法克服在场景探索中的效率瓶颈。
具体而言,我们将多个图像序列连接起来,输入到ORB-SLAM3中,利用其用于多序列处理的“atlas”策略。
此外,可以看到CCM-SLAM在一些场景中失败,因为传统的基于RGB的方法在无纹理环境中特别容易出现特征匹配问题。
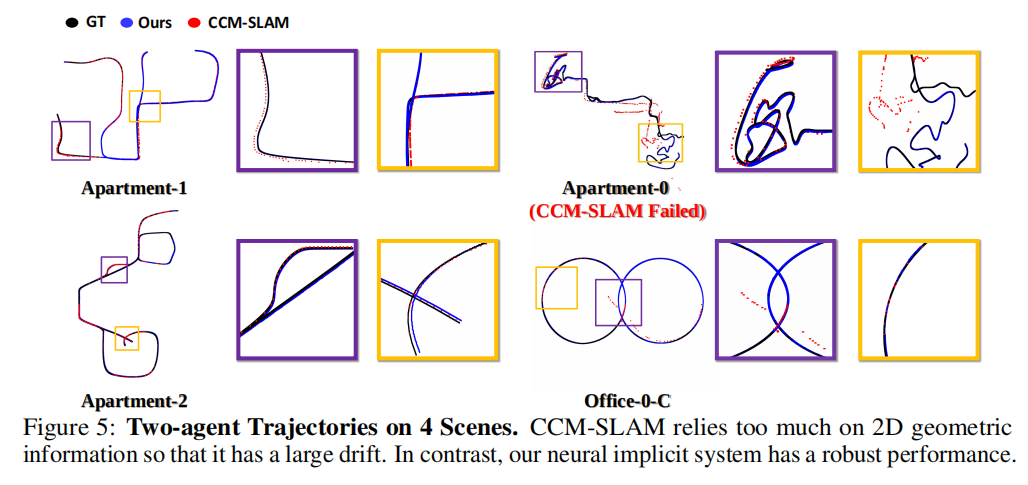
图5展示了每个智能体的轨迹。一旦两个子图被融合,只需要进行低成本的微调,就可以将两个神经场和相应的MLP调整到一个共享的域中。然后,这两个智能体可以重复使用彼此的先前观测并继续进行准确的跟踪。共享的MLP、神经场以及接下来的全局位姿图优化使CP-SLAM系统成为一个紧密协作的系统。
4.2 单智能体回环(Single Agent with Loop)
在表2中,我们展示了我们的系统在单智能体模式下在4个回环闭环数据集上的定位性能。我们的方法在定位性能上明显优于最近的方法,包括基于NeRF的方法和传统方法,这主要归功于前端和后端处理的并发集成,以及神经点表示的引入。
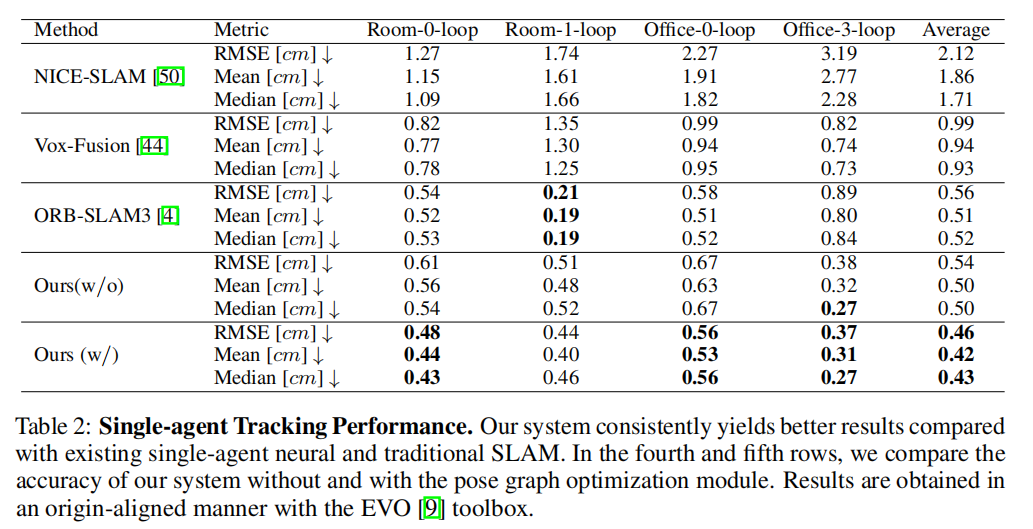
在定性方面,我们在图6中展示了NeRF-based方法在Room-0-loop和Office-3-loop上的轨迹。实验结果表明,围绕采样点的密度能量的集中程度对神经SLAM至关重要。
 NICE-SLAM [50]使用密集的体素网格,其中包含大量的空白空间,并且在这些空白空间中的采样点几乎没有贡献梯度传播。
NICE-SLAM [50]使用密集的体素网格,其中包含大量的空白空间,并且在这些空白空间中的采样点几乎没有贡献梯度传播。
Vox-Fusion [44]引入了一个重要的修改,实现了一个根据特定场景定制的稀疏网格,而不是一个密集的网格。然而,网格节点只能大致放置在物体附近,这对于跟踪是不利的。
在我们的基于神经点的方法中,我们确保神经场很好地适应了真实场景。特征嵌入可以准确地包含场景信息。集中分布的采样点和基于神经点的表示为姿势反向传播提供了更精确的梯度,使我们能够在更低的分辨率和内存使用率下超越NICE-SLAM和Vox-Fusion。
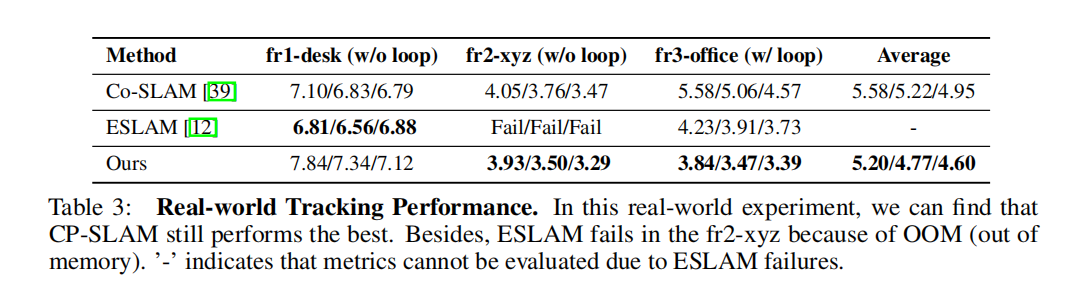
此外,我们在TUM-RGBD真实世界数据集上进行了实验,与Co-SLAM [39]和ESLAM [12]进行了比较。表3中的结果表明,我们的方法在真实世界环境中也取得了最先进的性能,并且回环检测和位姿图优化对于真实世界场景同样有效。
4.3 地图构建(Map Reconstruction)
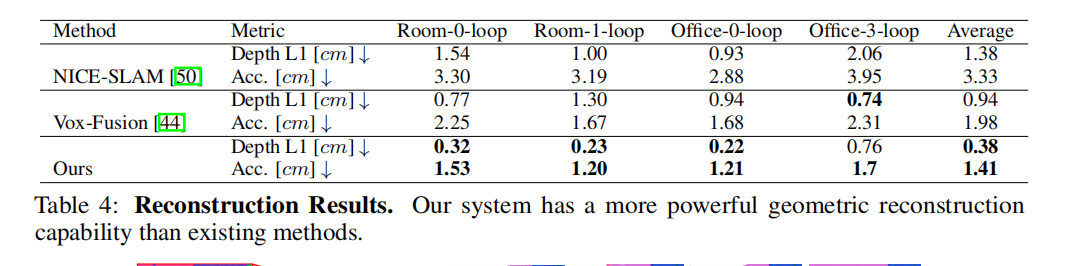
表4中的结果对比了我们提出的系统与NICE-SLAM [50]和Vox-Fusion [44]在几何重建方面的定量分析。
在我们的方法中,我们在整个预测轨迹中的每10帧渲染深度图和彩色图,并利用TSDF-Fusion(Open3D [49]库中的内置函数)构建网格地图。
在NICE-SLAM中,用于地图评估的有深度L1损失、网格准确性、完成度和完成度比等多个指标。
在我们的回环数据集中,场景并没有完全被扫描到,导致了网格重建中的空洞。因此,我们的比较实验主要关注深度L1损失和网格准确性。
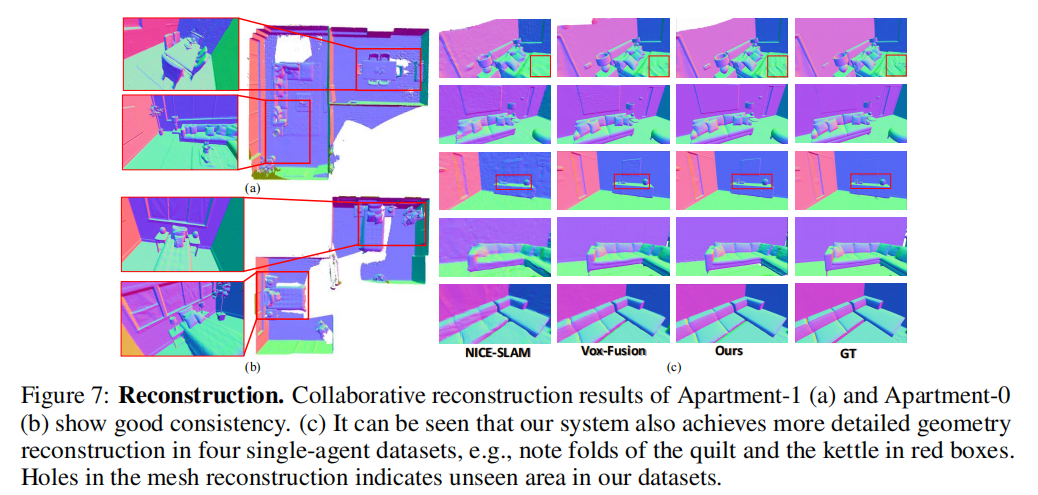
图7在定性上比较了三种方法的单智能体重建结果,并展示了我们的协作映射结果。显然,我们的方法在所有数据集上都实现了更详细的几何重建。
4.4 消融实验
我们对我们系统中的一些模块和设计进行了检查,以证明它们的重要性和我们流程的合理性。
姿态图优化(Pose Graph Optimization)
在这一部分,我们对PGO模块进行了消融实验。
表1和表2分别报告了我们单一智能体和双智能体情况下的带PGO和不带PGO的结果。在PGO模块的帮助下,单一智能体实验中的平均定位精度下降了10%,而双智能体实验中的下降了13%。
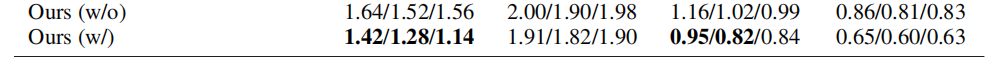

地图细化(Map Refinement)
如图8(a)所示,我们在MeshLab中定性地展示了地图细化前后的神经点云布局。我们可以观察到,经过细化的神经点云更好地适应了地面真实的网格。
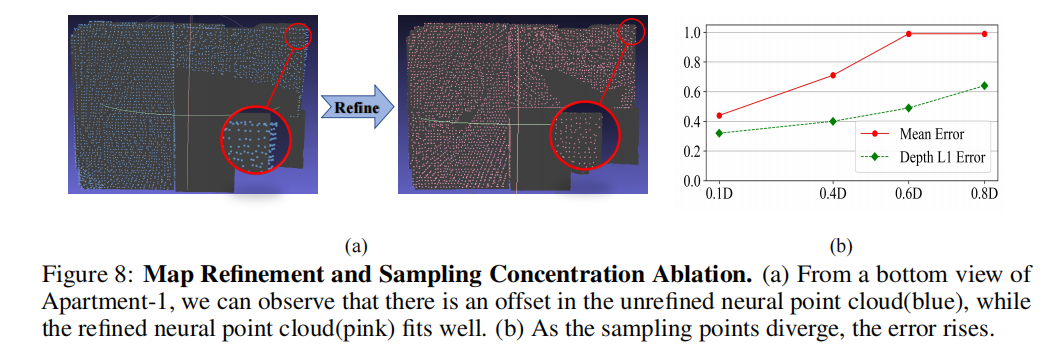
采样浓度(Sampling Concentration)
采样点附近的密度浓度是决定神经SLAM性能的关键点。我们在Replica Room-0-Loop序列上设计了一组不同采样间隔长度的实验。
如图8(b)所示,随着采样点逐渐分散,跟踪精度和深度L1损失持续下降至1.0厘米和0.6厘米。这个实验证明了第4.2节中的理论。
神经点密度(Neural Point Density)
在CP-SLAM中,我们采用了一个固定大小的立方体单元格,在过滤策略中调整神经点,即只保留距离一个立方体单元格中心最近的神经点。为了进一步探讨点云密度对跟踪精度的影响,我们在原始的Replica Room0场景中比较了不同尺寸的立方体网格的性能。
表5中的消融研究结果表明,当神经点数量较小时,由于场景表示不足,它们不足以编码详细的场景几何和颜色。相反,过多的神经点显然会延长学习时间以收敛。

我们经验性地发现,在我们的实验中,对于不同复杂性的所有测试场景,设置ρ = 14cm一直表现良好。
内存和运行时分析(Memory and Runtime Analysis)
我们在Replica Office-0-loop场景上评估了我们系统的运行时和内存消耗,与NICE-SLAM和Vox-Fusion进行了比较。我们报告了单帧跟踪和映射时间、MLP的大小以及整个神经场的内存占用量。表6中NICE-SLAM中巨大的特征大小是由于其密集的分层特征网格。

5 CP-SLAM 结论
本文提出的CP-SLAM,这是第一个基于新颖的神经点表示的稠密协作神经SLAM框架,它保留了完整的前端和后端模块,就像传统的SLAM系统一样。
系统的流程使我们的框架在定位和重建方面胜过了现有方法。
我们方法的一个局限性是它需要大量的GPU资源来处理多个图像序列。
此外,我们的系统在未观察到的区域中的孔洞填充能力略弱于基于特征网格的方法,这是因为神经点分布在观察到的对象表面周围,在固定半径球内编码周围场景信息。
此外,环路闭合中的相对姿态计算依赖于现有的基于渲染的优化,对于大视角变化可能不准确,从而导致地图融合漂移。因此,未来可以设计一个轻量级系统,进行从粗到细的姿态估计,这是一个有趣的方向。















 2071
2071











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











