










目录
2.1 单一智能体视觉SLAM(Single-agent Visual SLAM)
2.2 协同视觉SLAM(Collaborative Visual SLAM)
2.3 神经隐式表示(Neural Implicit Representation)
3.1 神经点云里程计(Neural Point based Odometry )
3.2 循环检测和子图对齐 (Loop Detection and Sub-Map Alignment)
3.3 分布式到集中式学习(Distributed-to-Centralized Learning)
3.4 位姿图优化和全局地图细化(Pose Graph Optimization and Global Map Refinement)
论文:CP-SLAM: Collaborative Neural Point-based SLAM System | OpenReview
Thirty-seventh Conference on Neural Information Processing Systems
代码: 尚未公布
1 Abstract
这篇论文介绍了一种基于协同隐式神经网络同步定位与地图构建(SLAM)系统,输为入RGB-D图像序列,系统包括完整的前端和后端模块,包括里程计、循环检测、子地图融合和全局优化。
为了在一个统一的框架中实现所有这些模块,文章提出了一种新颖的基于神经网络的三维场景表示方法,其中每个点维护一个可学习的神经特征用于场景编码,并与特定的关键帧相关联。
此外,我们提出了一种分布式到集中式的学习策略,用于协同隐式SLAM,以提高一致性和合作。 还提出了一种新颖的全局优化框架,类似于传统的捆绑调整,以提高系统的准确性。
在各种数据集上的实验证明了所提方法在相机跟踪和地图构建方面的优越性。
2 Related Work
2.1 单一智能体视觉SLAM(Single-agent Visual SLAM)
随着无人智能的发展,视觉SLAM在过去几十年中成为一个活跃的领域。Klein等人提出了一个视觉SLAM框架[15],将跟踪和地图制作分为不同的线程。这个框架被大多数当前方法所采用。
传统的单一智能体视觉SLAM使用过滤或非线性优化来估计摄像机的姿态。
基于过滤的方法[27, 3, 23]更具实时性,但全局一致性较差。相比之下,基于优化的方法[28, 29, 31, 4, 8, 19]可以充分利用过去的信息。同时,多源信息被广泛整合到SLAM系统中,以改善特定模块,例如轻量级深度估计[48, 42]。
2.2 协同视觉SLAM(Collaborative Visual SLAM)
协同SLAM可以分为两类:集中式和分布式。
CVI-SLAM[14]是一个集中式视觉惯性框架,可以在中央服务器上共享所有信息,每个代理外包计算密集型任务。
在集中式SLAM中,服务器管理所有子地图,执行地图融合和全局捆绑调整,并将处理后的信息反馈给每个代理。这个流程在CCM-SLAM[33]中得以重现,其中每个代理配备一个简单的视觉测距,并将定位和三维点云发送到中央服务器。
在分布式系统方面,Lajoie等人开发了一个完全分布式的SLAM[18],它基于点对点通信,可以拒绝异常值以提高鲁棒性。NetVLAD[1]在[18]中用于检测环路闭合。此外,[10]提出了专门用于多智能体系统的紧凑二进制描述符。
与传统的协同系统相比,我们的系统可以使用更少的神经点执行密集映射。
2.3 神经隐式表示(Neural Implicit Representation)
神经隐式场在许多计算机视觉任务中表现出色,如新视角合成[24, 25, 38, 2]、场景完成[5, 11, 30]和对象建模[6, 22, 40, 45, 46]。
在最近的研究中,一些工作[47, 41]试图从建立的神经隐式场中反向推断相机外部参数。受到神经场不同表示方式的启发,包括体素网格[21]和点云[43],NICE-SLAM[50]和Vox-Fusion[44]选择使用体素网格进行跟踪和制图,而不是使用受表达能力和遗忘问题限制的单一神经网络。它们都是与我们最相关的工作。
此外,vMAP[16]可以在缺乏3D先验条件下有效地建模密封的对象模型。ESLAM[13]通过三面和截断有符号距离场(TSDF)来解决RGB-D SLAM。除了纯神经网络方法外,一些混合系统,如NeRF-SLAM[32]和Orbeez-SLAM[7],构建了神经地图,但使用传统方法来估计姿态。
3 Method
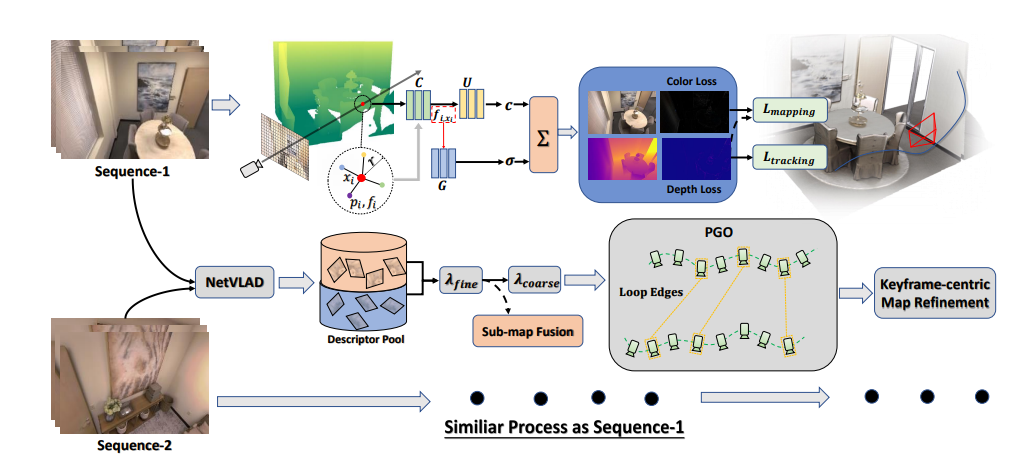
我们的协同SLAM系统概述下图所示。给定一组RGB-D序列,系统基于每个代理的神经点云表示,逐步进行跟踪和地图制作。
我们整合了一个基于学习的循环检测模块,该模块提取2D帧的唯一描述符,并通过高质量的循环约束拼接子地图。
我们设计了一个两阶段(分布式到集中式)的MLP训练策略,以提高一致性并加强协作。
为了减少制图和跟踪中的累积误差,我们利用子地图之间的共可见性进行全局位姿图优化作为后端处理,然后进行基于帧的地图精炼。
图1:系统概览。我们的系统以单个或多个RGB-D流作为输入,执行如下的跟踪和地图制作。
从左到右,我们在神经点场中进行可微分的射线体积渲染,以预测深度和颜色。为了获取沿射线的样本点的特征嵌入,我们在半径为r的球内插值邻居特征。
MLPs将这些特征嵌入解码为用于体素渲染的有意义的密度和辐射度。通过计算渲染差异损失,可以优化相机运动和神经场。
在跟踪和地图制作过程中,单一代理不断地将由NetVLAD编码的关键帧描述符发送到描述符池。中央服务器将融合子地图,并根据匹配对执行全局位姿图优化(PGO)以加深协作。
最后,我们的系统以关键帧为中心进行地图精炼,结束整个工作流程。
3.1 神经点云里程计(Neural Point based Odometry )
我们的系统从一个前端视觉测距模块开始,其中我们结合了位姿反传递更新和基于点的神经场,以执行顺序跟踪和制图。
基于点的神经场。我们将图像分为4 × 4的块,并逐步投影每个块的中心像素到其对应的3D位置。为了获取锚定在
上的特征嵌入
,将2D图像输入到一个未经训练的单层卷积神经网络。我们定义我们的神经点云为:
体素渲染。我们模拟 NeRF [26] 中的可微分体素渲染策略,其中辐射度和占用度沿着射线积分,以渲染颜色和深度图。给定一个 6DoF 姿势 和一帧的内参,我们可以从随机选择的像素发射射线并采样
点。任意采样点被定义为:
其中 是点的深度,
是单位射线方向。
在深度信息的指导下,我们可以在真实表面附近分布我们的样本。具体而言,我们在每条射线上采样个点。
对于具有有效深度 D的任何像素,在间隔
和
内均匀采样,分别生成
和
个样本点,其中
和
是当前深度图的最小和最大深度值。对于没有有效深度值的任何像素,
在间隔
内均匀采样,生成
个点。对于每个点
,我们首先在查询半径 r内查询 K 个邻居
,然后使用一个 MLP
将原始邻居特征
转换为
,其中包含相对距离信息,即
然后,一个辐射度 MLP 使用插值特征
解码位置
处的 RGB 辐射度
,该特征是根据反向距离权重和邻域特征进行加权插值得到的:
,
如果在 处找不到邻居,那么
处的占用度
被设为零。否则,我们使用位于
处的占用度 MLP
进行回归。我们采用类似于辐射度的基于反向距离的加权插值,但这里是在占用度水平进行插值。我们解码每个邻居的
并最终进行插值:
接下来,我们使用从 MLP 中回归得到的、
来估计每个点的权重
。
被视为
处的不透明度,或者说射线在该点终止的概率,
是点
的深度。
通过沿着射线计算深度和辐射度期望值,可以渲染深度图和颜色图,如下所示:
映射和跟踪。我们在映射过程中使用如下所述的渲染差异损失(Eq. 9),其中包含了几何损失和在映射过程中的光度损失。对于新来的帧,我们采样 M1 个像素来优化点锚定特征 以及 MLP
的参数。对于第一帧,我们需要以较高的代价对 M3 个像素进行良好的初始化,并进行约 3000∼5000 步的优化以确保后续处理的平滑进行。对于后续的映射,我们从当前帧和 5 个共视的关键帧中均匀选择像素。我们发现联合映射可以有效稳定跟踪过程。
映射损失(Lmapping)如下:
其中,、
表示地面真实深度和颜色图,
、
分别是对应的渲染结果,
是损失平衡权重。在跟踪过程中,我们通过反向传播进一步优化相机外参
,同时保持特征和 MLP 不变,其中
是四元数旋转,
是平移向量。我们在新来的帧上采样 M2 个像素,并假设零运动模型,其中新帧的初始姿势与上一帧相同。考虑到颜色图的强烈非凸性,跟踪损失仅包含几何部分:
3.2 循环检测和子图对齐 (Loop Detection and Sub-Map Alignment)
为了对齐子图并减小累积的位姿漂移,我们执行循环检测并计算不同子图之间的相对位姿。对于子图中的每个关键帧,我们将其与由预训练的NetVLAD [1]模型生成的描述符相关联。
我们使用描述符之间的余弦相似度作为循环检测的判断标准。
当摄像机在帧之间移动太多时,位姿优化容易陷入局部最优解,因此我们使用两个相似性阈值 和
来找到具有足够重叠并确保正确的循环相对位姿的匹配对。给定两个子图 M1 和 M2,我们找到具有最大重叠的循环帧集合
,其相似度大于
,并且找到小重叠的循环帧集合
,其相似度大于
但小于
。对于
这样的匹配对,我们将
的位姿视为初始位姿,将
视为参考帧。可以使用第3.1节描述的跟踪方法获取 {M1, M2} 之间的相对位姿测量。我们可以使用这个相对位姿对子图执行三维刚体变换,使得所有子图都设置在相同的全局坐标系中,实现子图对齐的目的,如下面图2所示:
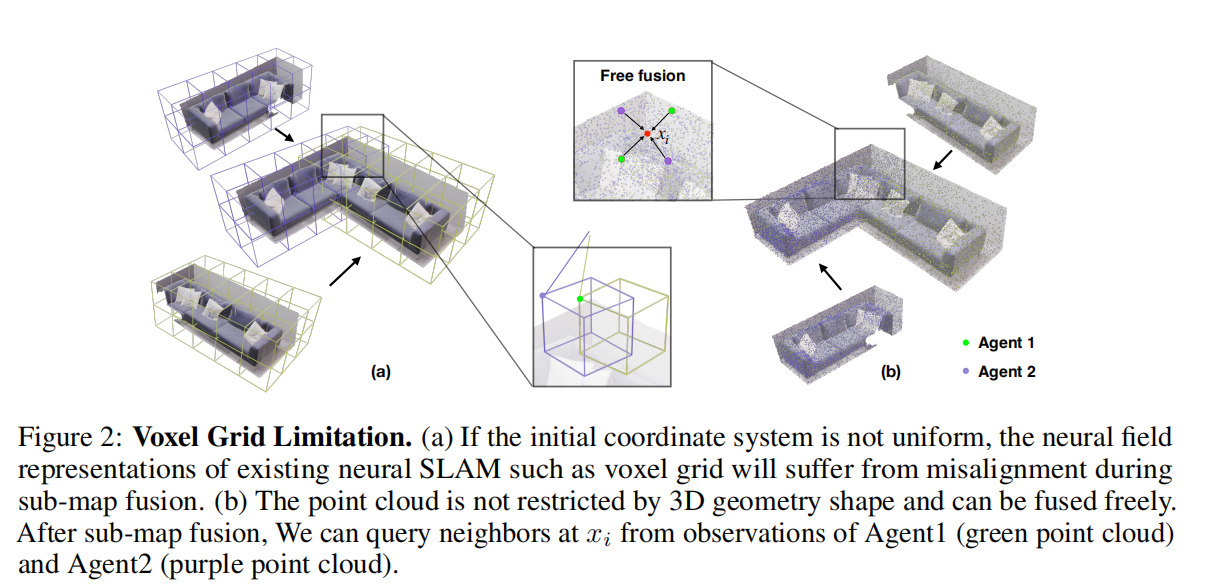
图2:体素网格限制
(a) 如果初始坐标系统不是均匀的,那么现有的神经SLAM(例如体素网格)在子图融合期间可能会因为不对齐而受到影响。
(b) 神经点云不受3D几何形状的限制,可以自由融合。在子图融合后,我们可以从Agent1(绿色点云)和Agent2(紫色点云)的观测中查询点
的邻居。
循环损失如下:
其中,是
和
之间的相对位姿,
和
分别是渲染的深度和地面真实深度。对于小重叠的循环帧集合
,我们仅使用它们执行位姿图优化(参见3.4)。
子图融合会导致特定区域的神经点冗余,给计算和内存带来负担。由于神经点云的稀疏性,我们采用基于网格的过滤策略,即根据神经点到 ρ³ 立方体中心的距离执行非极大值抑制。
3.3 分布式到集中式学习(Distributed-to-Centralized Learning)
为了增强一致性和协作性能,在协作SLAM中,我们采用了一个两阶段的MLP训练策略。在第一阶段(分布式阶段),每个图像序列被视为一个独立的个体,具有用于顺序跟踪和制图的唯一组MLPs 。在循环检测和子图融合之后,我们希望在所有序列之间共享通用的MLPs(集中式阶段)。
为此,我们引入了联邦学习机制,该机制以协作共享的方式训练单个网络。同时进行子图融合时,我们对每组MLPs进行平均,并在所有关键帧上微调平均的MLPs以统一离散的领域。随后,我们迭代地将共享的MLPs传递给每个代理进行本地训练,并将本地权重平均作为共享MLPs的最终优化结果,如下面图3所示。
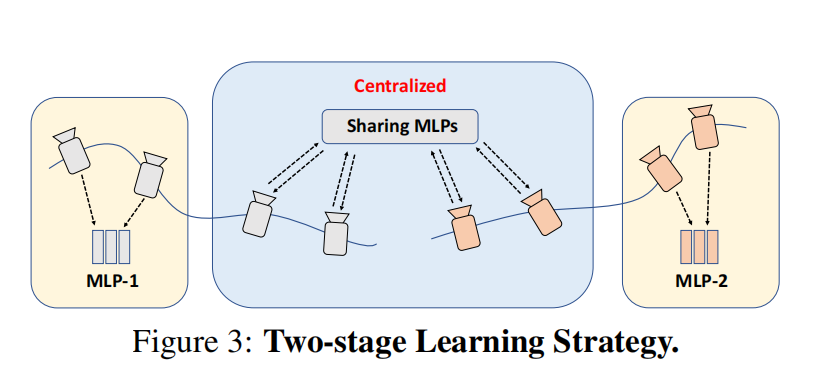
联邦学习(Federated Learning)是一种机器学习的分布式学习方法,其中模型的训练在本地设备上进行,而不是在集中式服务器上。这种方法允许设备在本地训练模型,然后将更新的权重参数传输回中央服务器,从而使全局模型在所有设备上得以改进。
联邦学习被用于协作性SLAM系统的两个阶段的训练过程中。在分布式阶段,每个图像序列被视为一个独立的个体,具有本地的MLPs(C,U,G)。在集中式阶段,为了提高一致性和合作,通过联邦学习机制,每个代理将其本地模型参数传输到中央服务器,中央服务器根据所有代理的权重更新来进行全局模型的训练。
这种方法的优势在于它允许在不共享原始数据的情况下进行模型训练,从而保护了用户的隐私。同时,它也有助于全局模型更好地适应整个系统的特性,提高一致性和协作水平。
3.4 位姿图优化和全局地图细化(Pose Graph Optimization and Global Map Refinement)
在所有序列的前端处理中,包括跟踪、制图、循环检测和子图融合,我们建立了一个全局位姿图模型,其中每帧的位姿作为节点,顺序相对位姿和循环相对位姿(sequential relative pose, and loop relative pose are edges)作为边。
位姿图模型如图4所示。我们在整个位姿图上进行全局位姿图优化,参考传统视觉SLAM,将估计的轨迹强制拉近到地面真实轨迹。
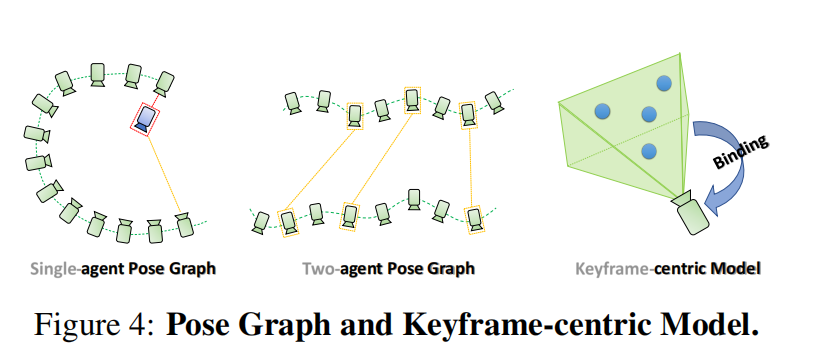
全局位姿图优化有效地减轻了累积误差,并提高了跟踪精度。我们使用Levenberg-Marquardt算法来解决由方程12描述的这个非线性全局位姿图优化问题,其中是节点的集合,
是顺序边的集合,
是循环边的集合,
表示相应边的不确定性。
显然,预期神经点云的布局应该在全局位姿图优化后重新排列。然而,一个以世界为中心的点云显然不能允许这样的调整。
为了解决这个限制,我们提出了一个以关键帧为中心的神经点场,其中每个3D点与一个关键帧关联(上图4)。
由于这个设计,我们可以根据优化后的姿势来优化我们的点云3D位置。在全局地图细化之后,我们使用基于网格的过滤来处理出现在局部区域的神经点云冗余。
考虑到全局地图细化后神经场和解码器之间轻微的不匹配,我们最终通过较少的优化迭代执行低成本的全局神经场微调。
4 实验
下一篇【论文解读】CP-SLAM: Collaborative Neural Point-based SLAM System_神经点云协同SLAM系统(下)-CSDN博客
5 结论
下一篇
【论文解读】CP-SLAM: Collaborative Neural Point-based SLAM System_神经点云协同SLAM系统(下)-CSDN博客
















 7256
7256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











