









课程Github地址:https://github.com/wrk666/VSLAM-Course/tree/master
0. 内容

对应于十四讲中的第5讲和第6讲
回顾十四讲P24-26

1. 针孔相机模型

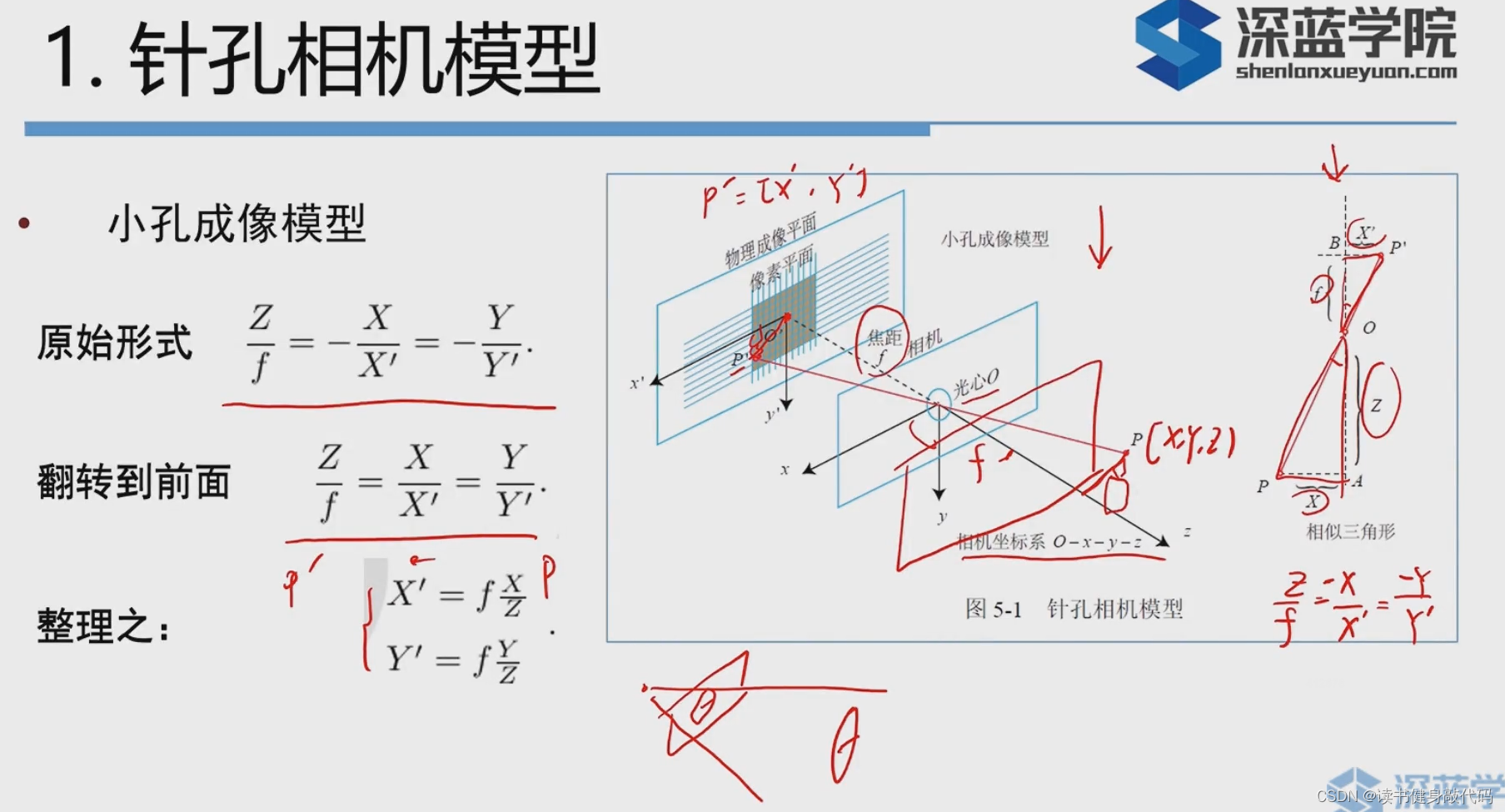

但是针孔镜头会引入畸变:
1.单目相机

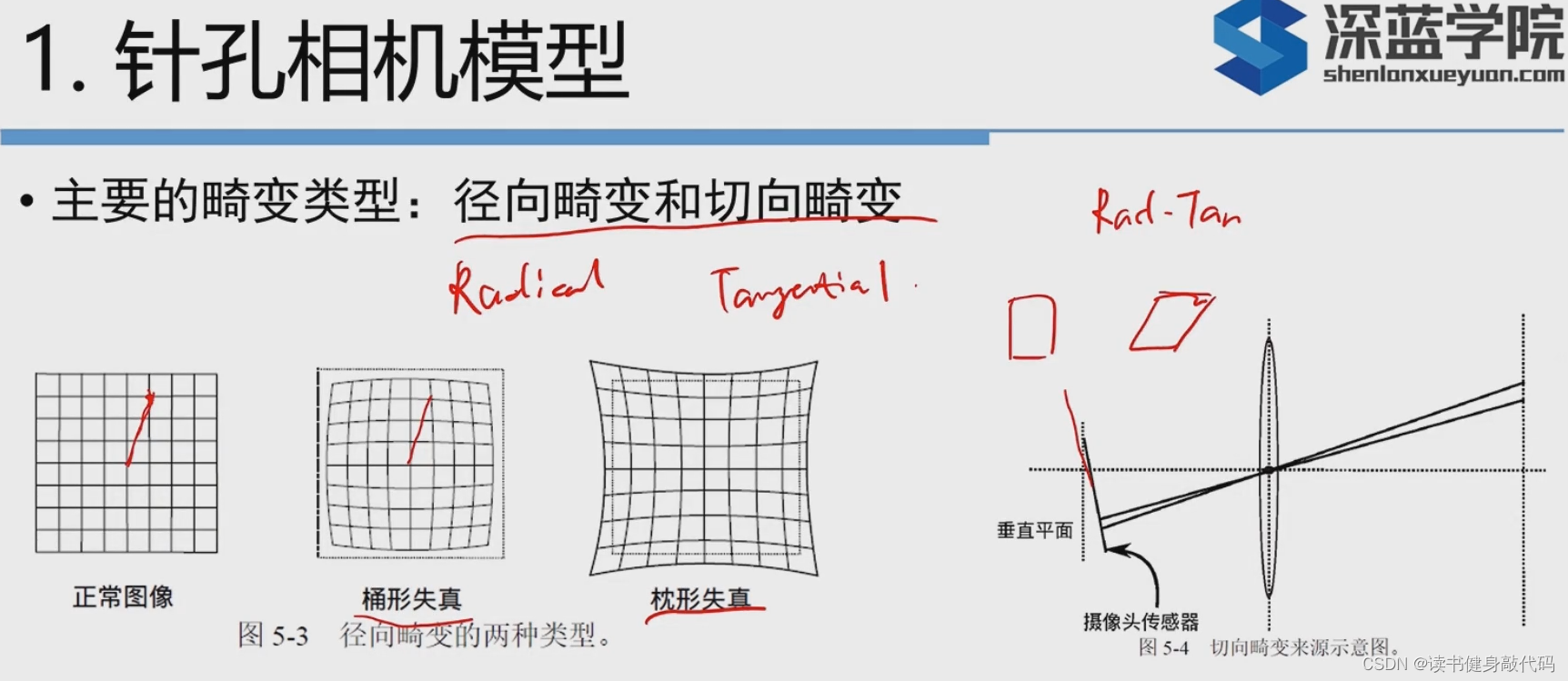

上面使用了5个畸变项,实际中可以灵活选用,如只使用
k
1
,
p
1
,
p
2
k_1,p_1,p_2
k1,p1,p2。在SLAM中通常选择先对图像去畸变,再讨论图像上的点

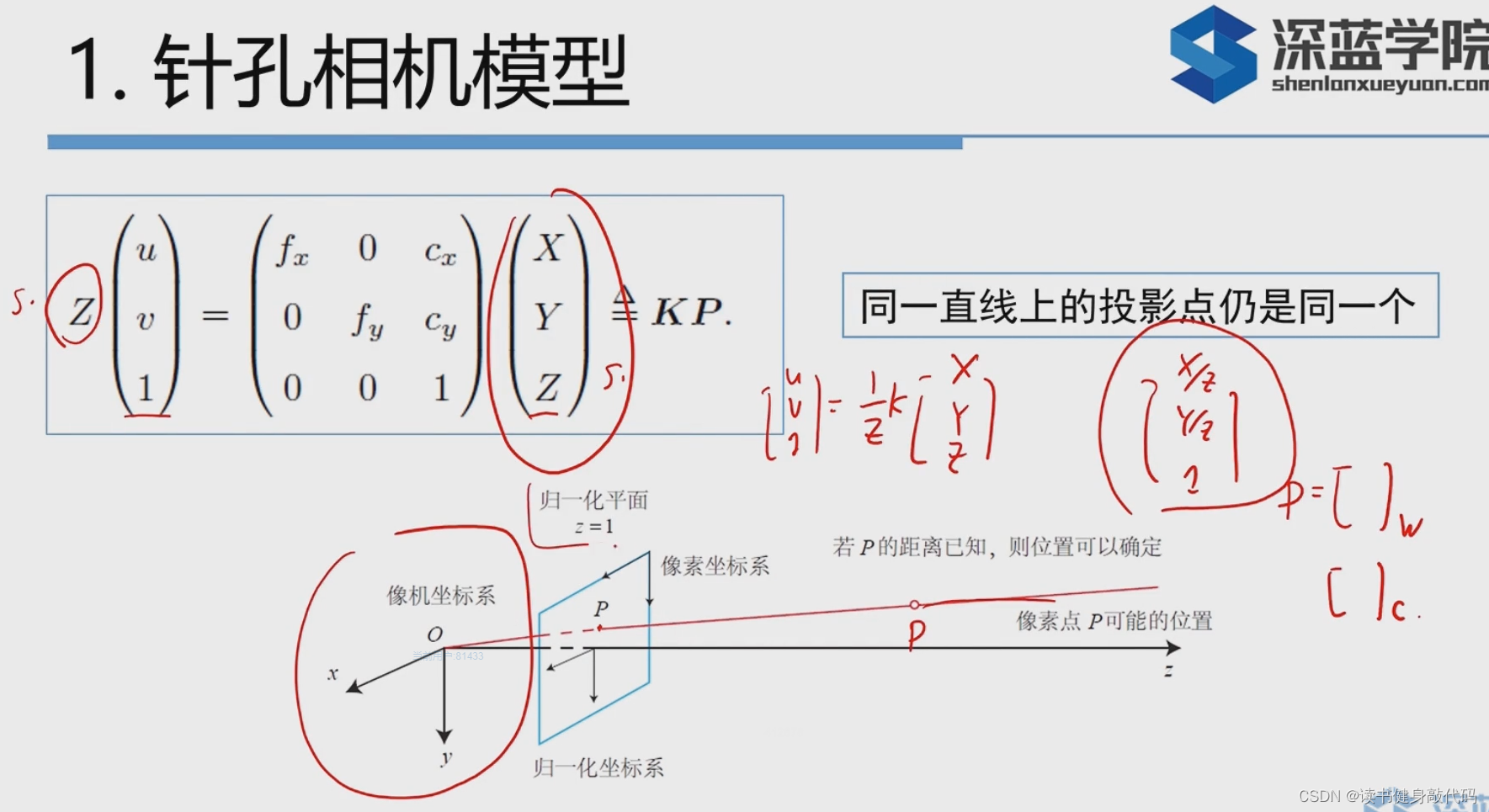
小结:
\quad
由世界坐标系中的点的坐标
P
w
(
X
,
Y
,
Z
)
P_w(X,Y,Z)
Pw(X,Y,Z)转换到像素的坐标
P
u
v
P_{uv}
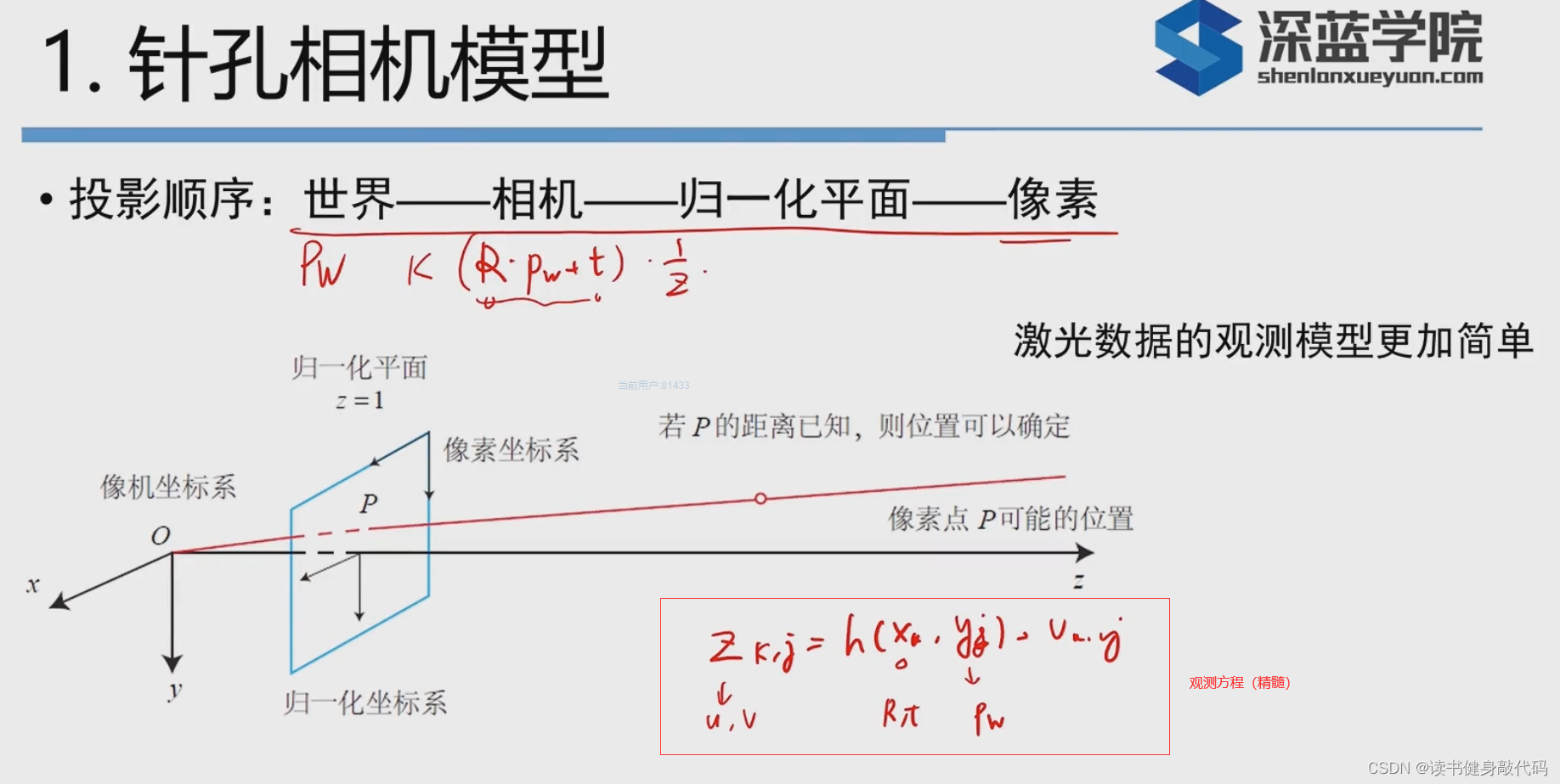
Puv要经历以下的变换:
1.
\quad
世界
P
w
P_w
Pw->
2.
\quad
相机
R
P
w
+
t
RP_w+t
RPw+t->
3.
\quad
归一化平面
1
Z
(
R
P
w
+
t
)
=
(
X
′
,
Y
′
)
\frac{1}{Z}(RP_w+t)=(X', Y')
Z1(RPw+t)=(X′,Y′)->
4.
\quad
若有畸变则加入畸变模型
P
′
=
(
X
′
,
Y
′
)
P'=(X', Y')
P′=(X′,Y′)->
(
X
d
i
s
t
o
r
t
e
d
,
Y
d
i
s
t
o
r
t
e
d
)
(X_{distorted},Y_{distorted})
(Xdistorted,Ydistorted)->
5.
\quad
像素:
P
u
v
=
K
P
′
=
{
u
=
f
x
x
d
i
s
t
o
r
t
e
d
+
c
x
v
=
f
y
y
d
i
s
t
o
r
t
e
d
+
c
y
P_{uv}=KP'= \left\{ \begin{array}{l} u=f_xx_{distorted}+c_x \\ v=f_yy_{distorted}+c_y \end{array} \right .
Puv=KP′={u=fxxdistorted+cxv=fyydistorted+cy
\quad
其中
K
K
K是相机内参,T是外参,也是我们SLAM中待估计的目标。
2. 双目相机
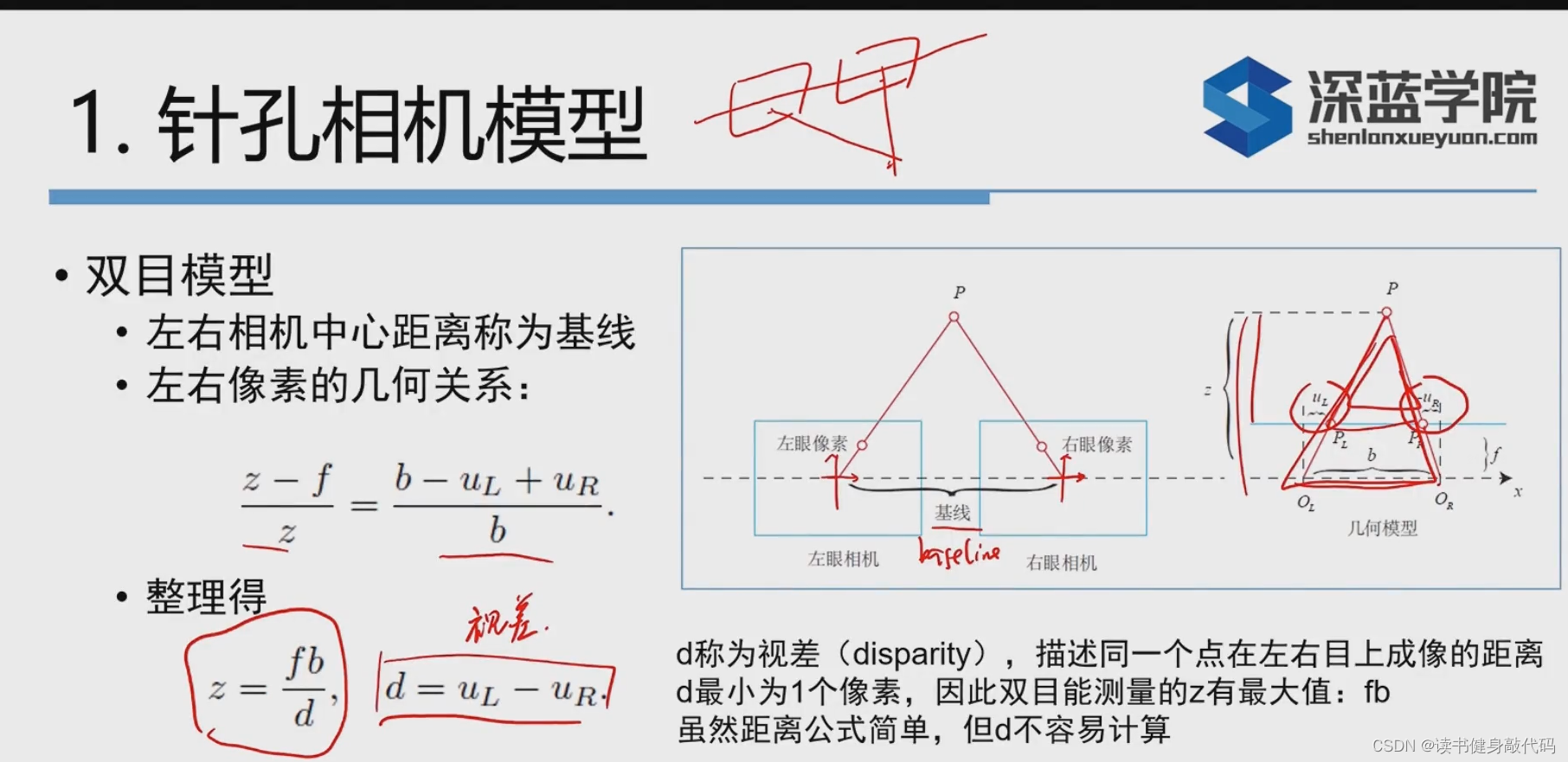
对于一个相机,bf不变,视察disparity
d
=
f
b
z
d=\frac{fb}{z}
d=zfb,深度越大(距离越远),视察越小。与人的直觉相符,越远的物体两只眼睛看起来的差异越小。

2. 图像
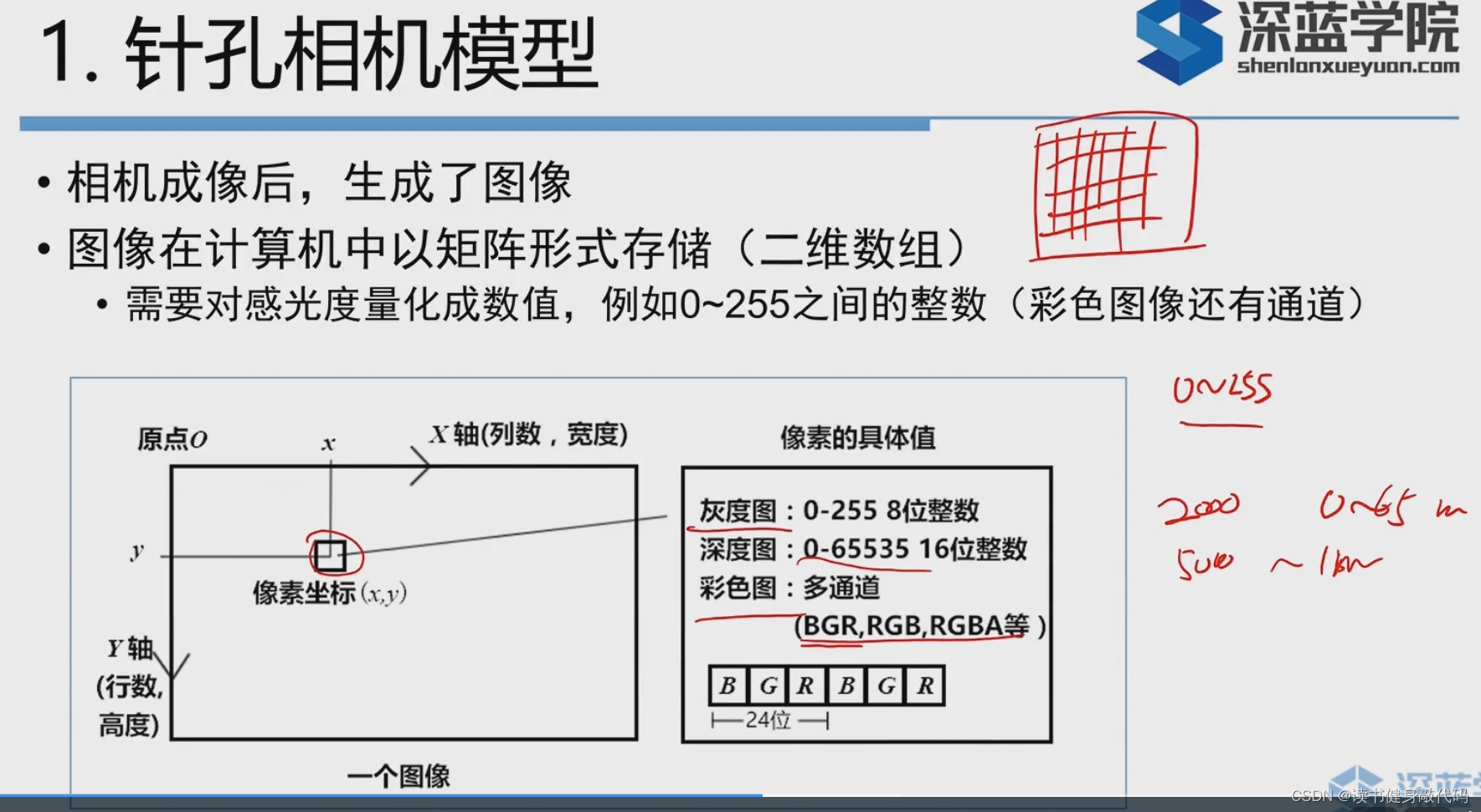
看数据集的时候需要关注倍数值是多少,eg: 5000->1米
大倍数距离近,精确;小倍数,看得更远,精确度较低。
3. 批量状态估计问题

状态估计有两种方法:批量和增量(递归,滤波器)的方法。
批量简单,先讲批量。
MAP(最大后延估计)和MLE(最大似然估计)

这个最小二乘的引入妙啊:

直观上讲:整体思路就是调整状态的估计使得误差最小,因为误差有分部,就有了调整的方向。
问题结构:
- ∑ \sum ∑范数,每项只有两个变量;
- 用李代数就转换为无约束LSP,相反,如果使用旋转矩阵还得保证 R T R = 1 , d e t ( R ) = 1 R^TR=1,det(R)=1 RTR=1,det(R)=1等麻烦问题,李代数的优势。
- 用二次型来度量误差,五擦汗的分布将影响此项在整个问题中的权重。如某次观测很精确,那么协方差矩阵就会“小”,信息矩阵就会“大”(后面再讨论)。

当
J
(
x
)
J(x)
J(x)很复杂的时候,对
J
(
x
)
J(x)
J(x)求导很难解,于是就使用迭代带方式求解。(鞍点既不是极值点也不是最值点)



不直接对F(x)进行近似,而是对f(x)进行近似,然后展开目标函数。对比和对F(x)进行近似的式子,发现使用
J
T
J
≈
H
J^TJ\approx H
JTJ≈H。但是
J
T
J
J^TJ
JTJ是半正定的,不一定可逆,所以
Δ
x
=
H
−
1
g
\Delta x=H^{-1}g
Δx=H−1g不一定成立。

先确定方向,再确定步长,使用
ρ
\rho
ρ来表示近似程度,

如果实际下降比近似下降更大,证明近似较好,扩大近似范围;
反之,如果实际下降比近似下降小,说明近似教差,缩小近似范围。
数学:最优化,数值优化。
4. 实践
本部分对应到14讲的代码中是ch5和ch6。
1. opencv使用
toturial有很多,可以自己入门,核心是一些图像处理,别的都是一些算法等,提取特征,标定,learning等功能。
还有opencv contrib库,不包含在正式库中,但是也有很多常用的功能。
关于遍历图像的部分,这里的image是一个二维矩阵,先遍历行(y),再遍历行(x),重点是算出对应位置的像素的地址,一个像素3通道(BGR),算出该像素的手通道的地址ptr,然后依次ptr[0],ptr[1],ptr[2]访问该像素的所有通道的值,在这个例程中前面的值都一样,因为图片左上角部分的都是一样的.

不过,换张我天选姬的图片就不一样了,虽然每个像素间变化还是很小
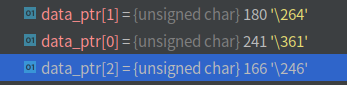
// 遍历图像, 请注意以下遍历方式亦可使用于随机像素访问
// 使用 std::chrono 来给算法计时
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
for ( size_t y=0; y<image.rows; y++ )
{
// 用cv::Mat::ptr获得图像的行指针
unsigned char* row_ptr = image.ptr<unsigned char> ( y ); // row_ptr是第y行的头指针
for ( size_t x=0; x<image.cols; x++ )
{
// 访问位于 x,y 处的像素
unsigned char* data_ptr = &row_ptr[ x*image.channels() ]; // data_ptr 指向待访问的像素数据(像素的第一个通道的地址)
// 输出该像素的每个通道,如果是灰度图就只有一个通道
for ( int c = 0; c != image.channels(); c++ )
{
unsigned char data = data_ptr[c]; // data为I(x,y)第c个通道的值
}
}
}
2. ceres曲线拟合
ceres有toturial。
cmake ..的时候出现类似下面的问题,搞了半天不知道这个gflags到底出啥问题了,反正也没用到这个库,搞不清楚问题就先删掉
cd /usr/local/lib
sudo rm -rf libgflags*
再cmake ..就通过了,后面如果再用到gflags再说吧,不过真心感觉这个google三件套没啥用。
实践部分主要是使用ceres求解曲线拟合问题,求解出a,b,c参数,这里调用ceres需要重载一个函数对象用于计算误差,重载的()要重载为函数模板,因为要传进来很多不同类型的数据:
// 代价函数的计算模型
struct CURVE_FITTING_COST
{
CURVE_FITTING_COST ( double x, double y ) : _x ( x ), _y ( y ) {}
// 残差的计算(()运算符重载,函数模板形式)
template <typename T>
bool operator() (
const T* const abc, // 模型参数,有3维
T* residual ) const // 残差
{
residual[0] = T ( _y ) - ceres::exp ( abc[0]*T ( _x ) *T ( _x ) + abc[1]*T ( _x ) + abc[2] ); // y-exp(ax^2+bx+c) 计算残差
return true;
}
const double _x, _y; // x,y数据
};
然后在这里调用:
problem.AddResidualBlock ( // 向问题中添加误差项
// 使用自动求导,模板参数:误差类型,输出维度,输入维度,维数要与前面struct中一致
new ceres::AutoDiffCostFunction<CURVE_FITTING_COST, 1, 3> (
new CURVE_FITTING_COST ( x_data[i], y_data[i] )
),
nullptr, // 核函数,这里不使用,为空
abc // 待估计参数
);
3. 使用g2o库求解
g2o有文档(没有ceres写得好,是论文的样子)。
是另一个库,基于图优化的库,有一个关于g2o的pdf文档
slambook的代码中G2O这部分中用的是老版本的G2O,我装了新的支持C++11特性的G2O,编译不通过,所以用slambook2中的代码编译,可以成功。
G2O相关的一些解释目前还不是很理解,但是这个库是非常重要的,对于图不是很了解,所以它的误差的计算也不懂,书上的意思大概是:
读取每条边所连接的顶点当前的估计值,根据曲线模型计算出观测值,然后两项作差就是误差。
但是如何体现出是使用图优化呢?(后面慢慢学习)
三个方法比较:手写GN最快,G2O其次,Ceres最慢。
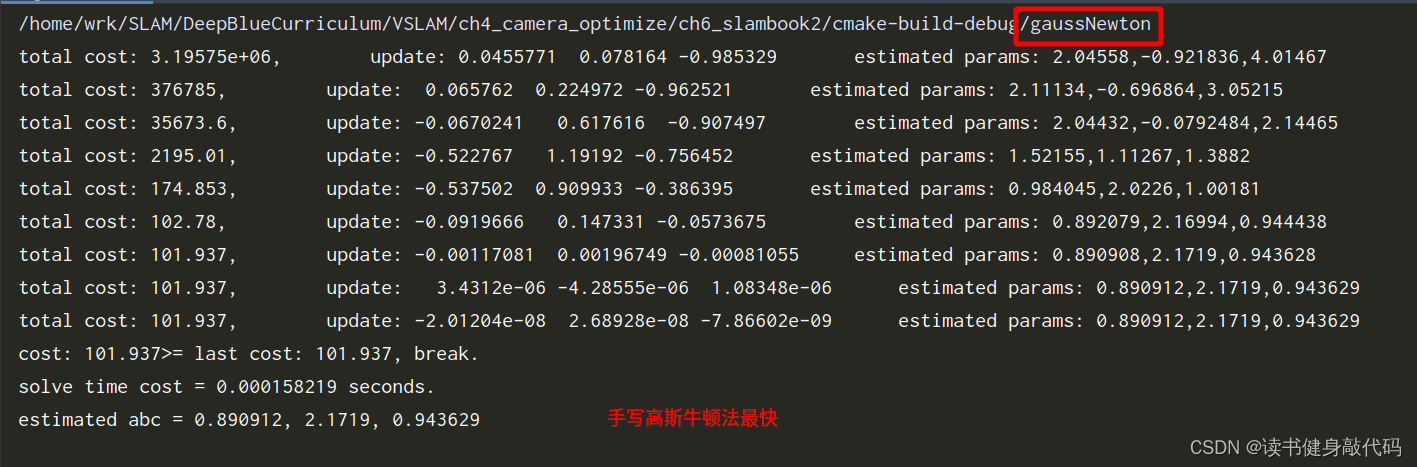
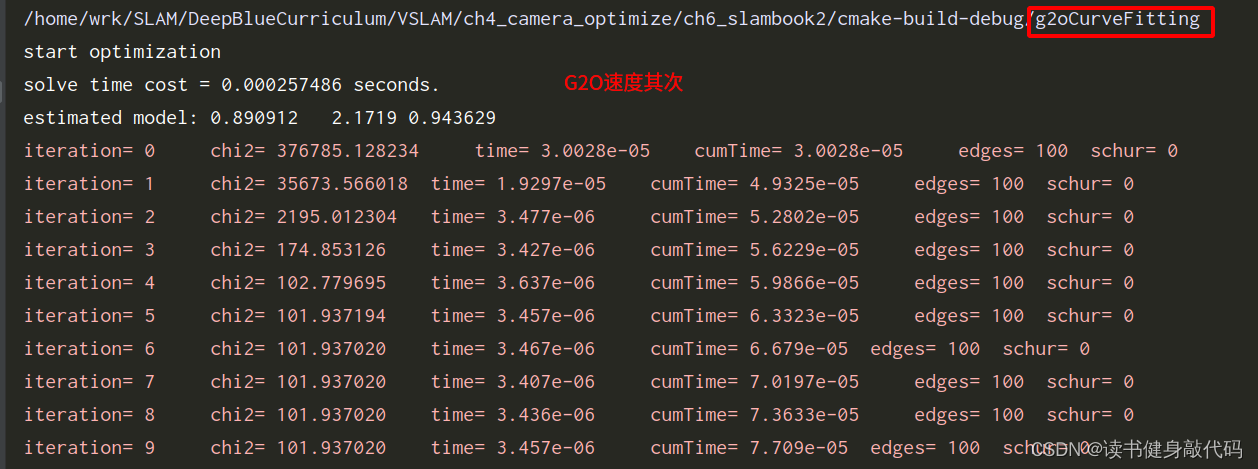
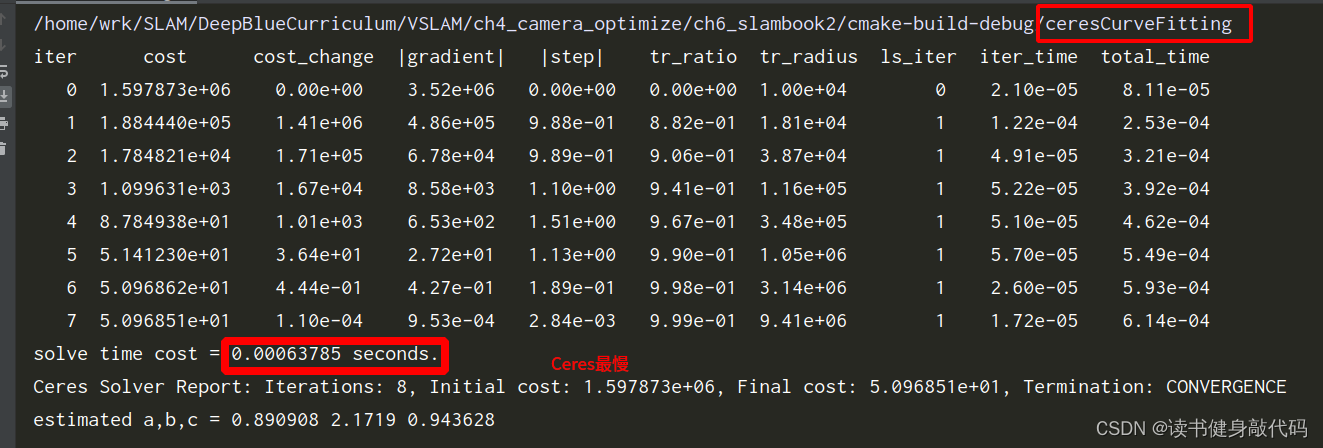
4. 3D视觉
4.1 双目视觉
贴上SLAM14讲中的代码
#include <opencv2/opencv.hpp>
#include <vector>
#include <string>
#include <Eigen/Core>
#include <pangolin/pangolin.h>
#include <unistd.h>
using namespace std;
using namespace Eigen;
// 文件路径
string left_file = "../left.png";
string right_file = "../right.png";
// 在pangolin中画图,已写好,无需调整
void showPointCloud(const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud);
int main(int argc, char **argv) {
// 内参
double fx = 718.856, fy = 718.856, cx = 607.1928, cy = 185.2157;
// 基线
double b = 0.573;
// 读取图像
cv::Mat left = cv::imread(left_file, 0);
cv::Mat right = cv::imread(right_file, 0);
cv::Ptr<cv::StereoSGBM> sgbm = cv::StereoSGBM::create(
0, 96, 9, 8 * 9 * 9, 32 * 9 * 9, 1, 63, 10, 100, 32); // 神奇的参数
cv::Mat disparity_sgbm, disparity;
sgbm->compute(left, right, disparity_sgbm);
disparity_sgbm.convertTo(disparity, CV_32F, 1.0 / 16.0f);
// 生成点云
vector<Vector4d, Eigen::aligned_allocator<Vector4d>> pointcloud;
// 如果你的机器慢,请把后面的v++和u++改成v+=2, u+=2
for (int v = 0; v < left.rows; v++)
for (int u = 0; u < left.cols; u++) {
if (disparity.at<float>(v, u) <= 0.0 || disparity.at<float>(v, u) >= 96.0) continue;
Vector4d point(0, 0, 0, left.at<uchar>(v, u) / 255.0); // 前三维为xyz,第四维为颜色
// 根据双目模型计算 point 的位置
double x = (u - cx) / fx; //和单目一样,只是这里可以计算深度信息,所以可以构建点云
double y = (v - cy) / fy;
double depth = fx * b / (disparity.at<float>(v, u)); //z=fb/d
point[0] = x * depth;
point[1] = y * depth;
point[2] = depth;
pointcloud.push_back(point);
}
cv::imshow("disparity", disparity / 96.0); //不明白这里的为什么要/96,看程序的意思应该是视差最大是96
cv::waitKey(0);
// 画出点云
showPointCloud(pointcloud);
return 0;
}
void showPointCloud(const vector<Vector4d, Eigen::aligned_allocator<Vector4d>> &pointcloud) {
if (pointcloud.empty()) {
cerr << "Point cloud is empty!" << endl;
return;
}
pangolin::CreateWindowAndBind("Point Cloud Viewer", 1024, 768);
glEnable(GL_DEPTH_TEST);
glEnable(GL_BLEND);
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
pangolin::OpenGlRenderState s_cam(
pangolin::ProjectionMatrix(1024, 768, 500, 500, 512, 389, 0.1, 1000),
pangolin::ModelViewLookAt(0, -0.1, -1.8, 0, 0, 0, 0.0, -1.0, 0.0)
);
pangolin::View &d_cam = pangolin::CreateDisplay()
.SetBounds(0.0, 1.0, pangolin::Attach::Pix(175), 1.0, -1024.0f / 768.0f)
.SetHandler(new pangolin::Handler3D(s_cam));
while (pangolin::ShouldQuit() == false) {
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
d_cam.Activate(s_cam);
glClearColor(1.0f, 1.0f, 1.0f, 1.0f);
glPointSize(2);
glBegin(GL_POINTS);
for (auto &p: pointcloud) {
glColor3f(p[3], p[3], p[3]);
glVertex3d(p[0], p[1], p[2]);
}
glEnd();
pangolin::FinishFrame();
usleep(5000); // sleep 5 ms
}
return;
}
其中最核心也是最难的部分是视差的计算,例程中用了SGBM算法来计算左右图像的视差,计算完视差 d d d之后使用 z = f b d z=\frac{fb}{d} z=dfb来计算深度,然后转换成单目相机的模型来计算像素->相机系下的坐标,对应到这块:
// 根据双目模型计算 point 的位置
double x = (u - cx) / fx; //和单目一样,只是这里可以计算深度信息,所以可以构建点云
double y = (v - cy) / fy;
double depth = fx * b / (disparity.at<float>(v, u)); //z=fb/d
point[0] = x * depth;
point[1] = y * depth;
point[2] = depth;

有些参数看不懂,在学中理解。
4.2 RGB-D视觉
4.1 QT安装
参考博客1,PCL库安装参考博客2
QT安装在/usr/local/include/qtcreater下
编写脚本语言直接打开,不用每次找目录:
#!/bin/sh
export QT_HOME=/usr/local/qtcreator/Tools/QtCreator/bin
$QT_HOME/qtcreator $*
有时间学习一下脚本语言,能方便很多。
4.2 VTK安装
下载VTK,直接安装9.1版本。
下载完成后,安装
tar -zvxf VTK-9.1.0.tar.gz
cd VTK-9.1.0
mkdir build && cd build
cmake ..
make -j8
sudo make install
4.3 PCL安装
看有人说PCL用源码安装(官网下载PCL然后cmake;git clone然后cmake)可能会遇到别的问题,所以就先采用简单的安装方式:
sudo apt install libpcl-dev
安装时间较长,安装完之后用上面博客的代码进行了测试:
CMakeLists.txt:
find_package(PCL 1.2 REQUIRED)
include_directories(${PCL_INCLUDE_DIRS})
add_executable(main main.cpp)
target_link_libraries (main ${PCL_LIBRARIES})
main.cpp:
#include <iostream>
#include "pcl/common/common_headers.h"
#include "pcl/io/pcd_io.h"
#include "pcl/visualization/pcl_visualizer.h"
#include "pcl/visualization/cloud_viewer.h"
#include "pcl/console/parse.h"
using namespace pcl;
int main(int argc, char **argv) {
std::cout << "Test PCL !!!" << std::endl;
pcl::PointCloud<pcl::PointXYZRGB>::Ptr point_cloud_ptr (new pcl::PointCloud<pcl::PointXYZRGB>);
uint8_t r(255), g(15), b(15);
for (float z(-1.0); z <= 1.0; z += 0.05)
{
for (float angle(0.0); angle <= 360.0; angle += 5.0)
{
pcl::PointXYZRGB point;
point.x = 0.5 * cosf (pcl::deg2rad(angle));
point.y = sinf (pcl::deg2rad(angle));
point.z = z;
uint32_t rgb = (static_cast<uint32_t>(r) << 16 |
static_cast<uint32_t>(g) << 8 | static_cast<uint32_t>(b));
point.rgb = *reinterpret_cast<float*>(&rgb);
point_cloud_ptr->points.push_back (point);
}
if (z < 0.0)
{
r -= 12;
g += 12;
}
else
{
g -= 12;
b += 12;
}
}
point_cloud_ptr->width = (int) point_cloud_ptr->points.size ();
point_cloud_ptr->height = 1;
pcl::visualization::CloudViewer viewer ("test");
viewer.showCloud(point_cloud_ptr);
while (!viewer.wasStopped()){ };
return 0;
}
结果证明PCL安装成功:
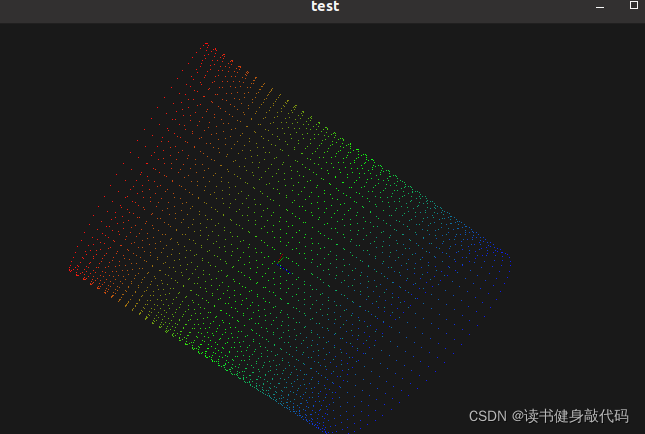
2024.1.20更新
Ubuntu 22.04系统安装PCL教程见博客
4.4 RGB-D视觉例程
编译SLAM14讲ch5的joinMap工程还是有错误,报错说
error: #error PCL requires C++14 or above
之类的一大堆错误,参考博客3说在CMakeLists.txt中添加一些编译选项即可:
ADD_COMPILE_OPTIONS(-std=c++11 )
ADD_COMPILE_OPTIONS(-std=c++14 )
set( CMAKE_CXX_FLAGS "-std=c++11 -O3" )
# 或不规定cmkae编译带有c++11特性等均可以编译成功。
然后make成功,运行完了之后生成一个map.pcd文件,然后使用pcl_viewer出图
pcl_viewer map.pcd

是一个房间的地图。
注意:给的位姿是 T w c T_{wc} Twc而不是 T c w T_{cw} Tcw,通常情况下是 T c w T_{cw} Tcw。
尝试过用 T w c K − 1 Z P u v T_{wc}K^{-1}ZP_{uv} TwcK−1ZPuv来直接计算出世界坐标,但是像素坐标那里还是有点没理解好,没有实现,先放在这里,继续往后学。
5. 课后题
5. RGB-D的标定

6. 遍历图像的方式
参考:SLAM14讲第5章课后题
3种遍历图像的方式:行指针、at访问像素、iterator(at最快,行指针齐次,iterator最慢)
//使用行指针遍历图像,这种遍历方式亦可使用于随机像素访问(速度居中)
// 使用 std::chrono 来给算法计时
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
for (size_t y = 0; y < image.rows; y++) {
// 用cv::Mat::ptr获得图像的行指针
unsigned char *row_ptr = image.ptr<unsigned char>(y); // row_ptr是第y行的头指针
for (size_t x = 0; x < image.cols; x++) {
// 访问位于 x,y 处的像素
unsigned char *data_ptr = &row_ptr[x * image.channels()]; // data_ptr 指向待访问的像素数据
// 输出该像素的每个通道,如果是灰度图就只有一个通道
for (int c = 0; c != image.channels(); c++) {
unsigned char data = data_ptr[c]; // data为I(x,y)第c个通道的值
}
}
}
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast < chrono::duration < double >> (t2 - t1);
cout << "image.ptr行指针 遍历图像用时:" << time_used.count() << " 秒。" << endl;
//通过下标和at函数来访问,也是3个一组(速度最快,也可随机访问)
chrono::steady_clock::time_point t3 = chrono::steady_clock::now();
for (int y=0; y<image.rows; y++)
{
for (int x=0; x<image.cols; x++)
{
for (int c=0; c<image.channels(); c++)
{
unsigned char data=image.at<cv::Vec3b>(y , x)[c];
}
}
}
chrono::steady_clock::time_point t4 = chrono::steady_clock::now();
chrono::duration<double> time_used2 = chrono::duration_cast < chrono::duration < double >> (t4 - t3);
cout << "at访问 遍历图像用时:" << time_used2.count() << " 秒。" << endl;
//一个像素就是一个迭代器(3通道,即3个一组),通过迭代器迭代来访问(速度最慢)
chrono::steady_clock::time_point t5 = chrono::steady_clock::now();
cv::MatConstIterator_<cv::Vec3b> it_in=image.begin<cv::Vec3b>();
cv::MatConstIterator_<cv::Vec3b> itend_in=image.end<cv::Vec3b>();
while(it_in!=itend_in)
{
for (int c=0; c<image.channels(); c++)
{
unsigned char data=(*it_in)[c];
}
it_in++;
}
chrono::steady_clock::time_point t6 = chrono::steady_clock::now();
chrono::duration<double> time_used3 = chrono::duration_cast < chrono::duration < double >> (t6 - t5);
cout << "iterator访问 遍历图像用时:" << time_used3.count() << " 秒。" << endl;
image.ptr行指针 遍历图像用时:6.9e-08 秒。
at访问 遍历图像用时:5.1e-08 秒。
iterator访问 遍历图像用时:0.00106578 秒。














 1190
1190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









