







在CMU团队开源的全套导航系统中,点云的地面分割是在局部路径规划的前提。之前的文章已经对局部路径规划算法做了详细的介绍,包括Matlab用采样的离散点做前向模拟三次样条生成路径点,CMU团队最新开发的局部路径导航算法 localPlanner 代码详解以及如何适用于现实移动机器人。
CMU所提供的点云地面分割算法在其提供的仿真环境下,效果比较明显,可以有效的识别地面与障碍物。
首先还是对参数简单的介绍一下:
double scanVoxelSize = 0.05; --- 点云下采样
double decayTime = 2.0; --- 点云时间差阈值 大于则不会被处理
double noDecayDis = 4.0; --- 点云距离阈值 小于该阈值不考虑时间差
double clearingDis = 8.0; --- 该距离外的点会被清除
bool clearingCloud = false; --- 清除距离外的点云
bool useSorting = true;
double quantileZ = 0.25; --- 考虑地面附近高程最小值会改变
bool considerDrop = false;
bool limitGroundLift = false;
double maxGroundLift = 0.15;
bool clearDyObs = false;
double minDyObsDis = 0.3;
double minDyObsAngle = 0;
double minDyObsRelZ = -0.5;
double minDyObsVFOV = -16.0;
double maxDyObsVFOV = 16.0;
int minDyObsPointNum = 1;
bool noDataObstacle = false;
int noDataBlockSkipNum = 0;
int minBlockPointNum = 10; --- 计算有效高程的最小点云数量
double vehicleHeight = 1.5; --- 车辆的高度
int voxelPointUpdateThre = 100; --- 需要处理的体素网格点云数量最小值
double voxelTimeUpdateThre = 2.0; --- 更新体素网格时间阈值
double minRelZ = -1.5; --- 点云处理的最小高度
double maxRelZ = 0.2; --- 点云处理的最大高度
double disRatioZ = 0.2; --- 点云处理的高度与距离的比例
// terrain voxel parameters
float terrainVoxelSize = 1.0; --- 地形的分辨率
int terrainVoxelShiftX = 0; --- 地形中心与车体的偏移量
int terrainVoxelShiftY = 0; --- 地形中心与车体的偏移量
const int terrainVoxelWidth = 21; --- 地形的宽度
int terrainVoxelHalfWidth = (terrainVoxelWidth - 1) / 2;
const int terrainVoxelNum = terrainVoxelWidth * terrainVoxelWidth;
// planar voxel parameters
float planarVoxelSize = 0.2; --- 平面的分辨率
const int planarVoxelWidth = 51; --- 平面的宽度
int planarVoxelHalfWidth = (planarVoxelWidth - 1) / 2;
const int planarVoxelNum = planarVoxelWidth * planarVoxelWidth;
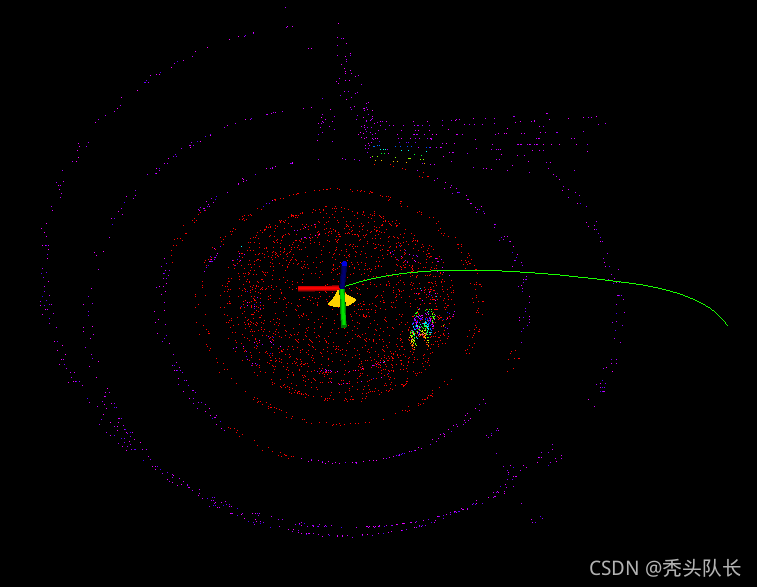
和 LocalPlanner 中一样,地形分割所接收到的点云信息同样也是在map坐标系下,因此首先要将其转换到车体坐标系下,即base_link,还包括点云的裁剪。在进行地面分割之前,做了一个点云滚动的操作。如下图所示,紫色的点云为 terrainVoxelCloud 地形,其他彩色则为分割后的结果,可发现其分割的区域并不完全是地形点云。因此猜想,这个点云滚动的操作,可能是为了同步点云和车辆的位置,毕竟点云是在map坐标下下的,比如说因为某些延迟,导致车辆与切割的点云信息存在偏差。当偏差大于 terrainVoxelSize 一个格子大小时,就通过翻滚,将车辆位置与点云位置进行配准。
while (vehicleX - terrainVoxelCenX > terrainVoxelSize) {
for (int indY = 0; indY < terrainVoxelWidth; indY++) {
pcl::PointCloud<pcl::PointXYZI>::Ptr terrainVoxelCloudPtr =
terrainVoxelCloud[indY];
for (int indX = 0; indX < terrainVoxelWidth - 1; indX++) {
terrainVoxelCloud[terrainVoxelWidth * indX + indY] =
terrainVoxelCloud[terrainVoxelWidth * (indX + 1) + indY];
}
terrainVoxelCloud[terrainVoxelWidth * (terrainVoxelWidth - 1) +
indY] = terrainVoxelCloudPtr;
terrainVoxelCloud[terrainVoxelWidth * (terrainVoxelWidth - 1) + indY]
->clear();
}
terrainVoxelShiftX++;
terrainVoxelCenX = terrainVoxelSize * terrainVoxelShiftX;
}
那么关于terrainVoxelCloud 的构建,是一个 terrainVoxelWidth 宽的正方形区域,因为其索引号为非负值,需要将接收到的点云数据,根据距离插入到对应的 Voxel 中。具体的序号计算公式如下,这里对于坐标的取整方式是四舍五入。
i
n
d
X
=
p
o
i
n
t
.
x
−
v
e
h
i
c
l
e
X
t
e
r
r
a
i
n
V
o
x
e
l
S
i
z
e
+
t
e
r
r
a
i
n
V
o
x
e
l
S
i
z
e
2
indX={point.x-vehicleX \over terrainVoxelSize}+{terrainVoxelSize \over 2}
indX=terrainVoxelSizepoint.x−vehicleX+2terrainVoxelSize
i
n
d
Y
=
p
o
i
n
t
.
y
−
v
e
h
i
c
l
e
Y
t
e
r
r
a
i
n
V
o
x
e
l
S
i
z
e
+
t
e
r
r
a
i
n
V
o
x
e
l
S
i
z
e
2
indY={point.y-vehicleY \over terrainVoxelSize}+{terrainVoxelSize \over 2}
indY=terrainVoxelSizepoint.y−vehicleY+2terrainVoxelSize对于每一个点云都需要进行处理,不过对于在车辆左侧或者后侧的序号都要减1,因为此时和坐标值为正时四舍五入计算方式不一样。对于处理后点云序号非负的数据,便加入到地形体素网格点云中。由 terrainVoxelUpdateNum 记录每一个体素网格中存入点云的数量。
int indX = int((point.x - vehicleX + terrainVoxelSize / 2) /
terrainVoxelSize) + terrainVoxelHalfWidth;
int indY = int((point.y - vehicleY + terrainVoxelSize / 2) /
terrainVoxelSize) + terrainVoxelHalfWidth;
if (indX >= 0 && indX < terrainVoxelWidth && indY >= 0 && indY < terrainVoxelWidth) {
terrainVoxelCloud[terrainVoxelWidth * indX + indY]->push_back(point);
terrainVoxelUpdateNum[terrainVoxelWidth * indX + indY]++;
}
在所有点云都被存入到体素网格内后,对其进行处理。接收到第一帧点云数据为初始系统时间 systemInitTime,点云的强度被设置为激光数据的时间差。
systemInitTime = laserCloudTime;
point.intensity = laserCloudTime - systemInitTime;
在遍历每一个网格时,仅对格内需要更新的点云数量大于 voxelPointUpdateThre 的网格进行处理。并且与上一次该网格处理的时间差大于 voxelTimeUpdateThre。
if (terrainVoxelUpdateNum[ind] >= voxelPointUpdateThre ||
laserCloudTime - systemInitTime - terrainVoxelUpdateTime[ind] >= voxelTimeUpdateThre ||
clearingCloud
)
在体素栅格中,需要被进行地面分割的点云满足以下要求,这些点云会被放入 terrainCloud ,用于地面分割。
- 点云高度大于最小阈值
- 点云高度小于最大阈值
- 当前点云的时间与要处理的点云时间差小于阈值
decayTime,或者距离小于noDecayDis - 此时不会清除距离外的点云,或者不在需要被清除的距离之内
接下来便分割地面并计算每一个点的高程信息。这里又重新创建了一个二维数组用于存放平面点高程,存入的方法和之前一样,不过分辨率从1变成了0.2。除此之外,每一个点云不只放在同一个网格中,而是复制到一个3*3的邻域。
for (int dX = -1; dX <= 1; dX++) {
for (int dY = -1; dY <= 1; dY++) {
if (indX + dX >= 0 && indX + dX < planarVoxelWidth && indY + dY >= 0 && indY + dY < planarVoxelWidth) {
planarPointElev[planarVoxelWidth * (indX + dX) + indY + dY].push_back(point.z);
}
}
}
在这一个二维数组中,找到该网格内点云高程最小值,作为该体素网格的高程,存入到体素网格 planarVoxelElev 中。此时的 planarVoxelElev 相当于保存了附近点云高程的最小值。
for (int j = 0; j < planarPointElevSize; j++) {
if (planarPointElev[i][j] < minZ) {
minZ = planarPointElev[i][j];
minID = j;
}
}
之前所做的工作都是为了点云分割,主要是用于地面分割的点云 terrainCloud ,和高程信息 planarVoxelElev ,下面才开始真正的对地面和障碍物进行分割。首先和存入到体素网格的思想一样,将点云信息和高程信息通过索引对应起来。
如果当前点云的高程比附近最小值大,小于车辆的高度,并且计算高程时的点云数量也足够多,就把当前点云放入到地形高程点云中。其中点云的强度为一个相对的高度。
if (planarVoxelDyObs[planarVoxelWidth * indX + indY] < minDyObsPointNum ||!clearDyObs) { // clearDyObs = false
float disZ = point.z - planarVoxelElev[planarVoxelWidth * indX + indY];
if (considerDrop) disZ = fabs(disZ); //considerDrop = false;
int planarPointElevSize = planarPointElev[planarVoxelWidth * indX + indY].size();
if (disZ >= 0 && disZ < vehicleHeight && planarPointElevSize >= minBlockPointNum) {
terrainCloudElev->push_back(point);
terrainCloudElev->points[terrainCloudElevSize].intensity = disZ;
terrainCloudElevSize++;
}
}
以上就是CMU开源导航算法中的地面分割,所用的思想就是计算当前位置与附近位置最小高程的一个相对高程。这样看来,在一个平滑的坡上效果表现还是可以,也可以改变邻域的大小,不过 3 ∗ 3 3*3 3∗3也有0.6m的范围了。
除此之外还有一些其他的参数,例如 noDataObstacle,clearDyObs,useSorting等,默认设置的为 false ,也就不会被执行,也就不再看了。在实际使用时,点云中心与车体中心或者说与激光雷达中心永远保持一致,则不需要通过翻滚配准。因为需要对上一帧翻滚,在源码中也没有对上一帧的点云进行清空,所以在实际使用时需要在主循环中对 terrainVoxelCloud 进行清空,否则会出现重影。可使用如下代码重置点云数据。
for (int i = 0; i < terrainVoxelNum; i++) {
terrainVoxelCloud[i].reset(new pcl::PointCloud<pcl::PointXYZI>());
}

















 334
334











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











