










 本文详细介绍了随机森林在分类分析中的应用,包括randomForest包的使用、参数调优、特征变量筛选及模型评估。通过调参,分类错误率从69.44%降低至35.71%,并进一步通过特征重要性分析和Boruta算法优化特征,以提高模型准确率。文章还讨论了随机森林的基础理论、优缺点及与其他方法的对比。
本文详细介绍了随机森林在分类分析中的应用,包括randomForest包的使用、参数调优、特征变量筛选及模型评估。通过调参,分类错误率从69.44%降低至35.71%,并进一步通过特征重要性分析和Boruta算法优化特征,以提高模型准确率。文章还讨论了随机森林的基础理论、优缺点及与其他方法的对比。
此文主要涉及随机森林分类分析,主要包含以下几部分内容:
1)随机森林基础知识
2)randomForest()认识及构建分类判别模型;
3)随机森林参数调优
4)随机森林模型评估
classification rate、Sensitivity和specificity和ROC curve/AUC value
5)特征变量重要性筛选及绘图
重要性指数排序、交叉验证及Boruta算法筛选
一、 准备数据
此处使用的包含分类信息的虚构微生物otu数据,用于构建随机森林分类模型。主要分析目的:1)构建准确率高的随机森林分类模型,2)检测分类水平间重要的OTUs(biomarkers)。
# 1.1 导入数据
setwd("D:\\EnvStat\\公众号文件\\随机森林分析") # 设置工作路径
#dir()
#file.show("otu.csv")
otu = read.csv("otu.csv",row.names = 1,header = TRUE,check.names = FALSE,stringsAsFactors = FALSE) # 微生物组数据
dim(otu)
head(otu)
# 1.2 计算相对丰度
spe = otu
spe[3:ncol(spe)] <- sweep(spe[3:ncol(spe)],1,rowSums(spe[3:ncol(spe)]),'/')*100
spe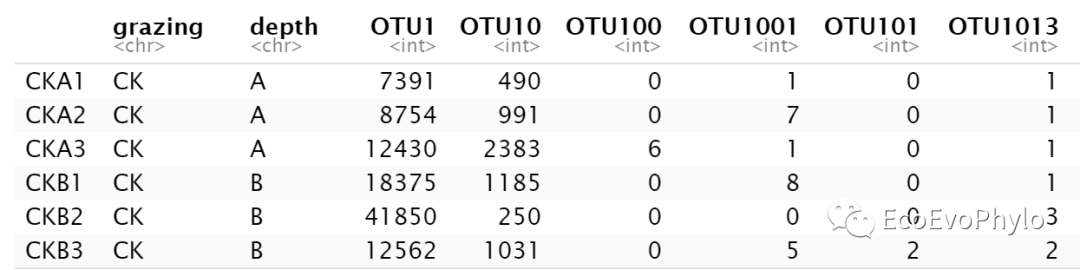
图1|原始otu表,otu.csv。前;两列为分类信息,后面分析只使用depth分类信息。
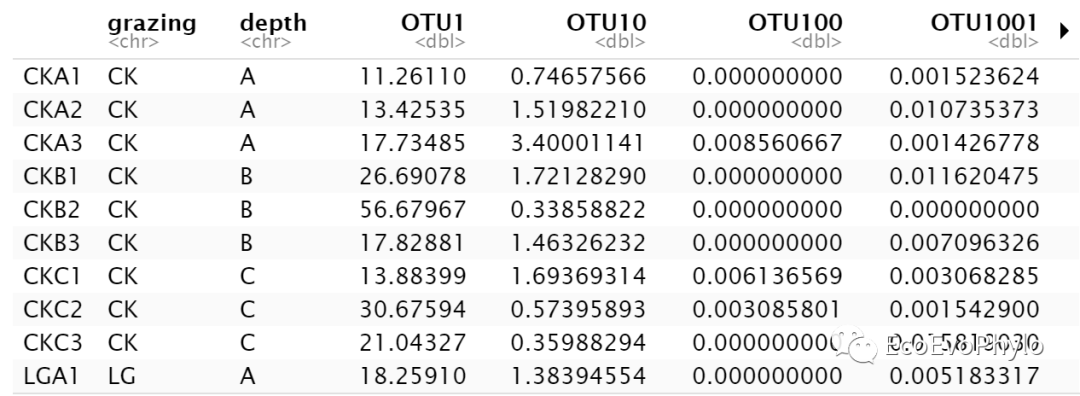
图2|相对丰度otu表,spe。
二、随机森林判别分析
基于随机森林的判别和回归分析。随机森林,构建决策树只使用部分输入特征(自变量),这样每颗决策树不会总是受到强预测特征强烈影响,其它预测变量有更多的作用机会,有助于去除决策树间的关联(decorrelates)。更多详细基础理论,在推文最后。
2.1 randomForest包进行随机森林判别分析及输出结果简介
每个参数以及结果的意义,都进行了标注。如果特征变量中包含分类变量,则应该先将其转为因子数据(as.factor())。
#install.packages("randomForest")
library(randomForest)
library(rfPermute) #可用于补齐缺失值,计算混淆矩阵及置信区间
library(caret)
#spe$grazing = as.factor(spe$grazing)
set.seed(12345)
RF = randomForest(x = spe[-c(1:2)],
y = factor(spe[[2]]), # y为因子数据,进行判别分析;为null则进行无监督分析。
mtry= floor(sqrt(ncol(spe[-c(1:2)]))),# 设置每颗决策树中的自变量数量。判别默认自变量数量的平方根。回归默认自变量数量的1/3.
ntree = 500, # 设置决策树数量,默认500
importance=TRUE,# 评估预测变量的重要性
localImp = TRUE, # 计算自变量对样本的重要性。
proximity = TRUE,# 计算行之间的接近度
oob.prox = TRUE,#只根据袋外数据来计算接近度
norm.votes = TRUE, # 默认以比例显示投票结果,FALSE以计数形式展示。
na.action=na.omit, # 缺失值处理方式,对于缺失数据,R语言的randomForest软件包通过na.roughfix函数用中位数(对于连续变量)或众数(对于分类变量)来进行替换。
keep.inbag=TRUE,
sampsize= nrow(spe[-c(1:2)]), # 用于构建决策树的样本数量。replace=TRUE,则默认为所有样本,否则则为ceiling(.632*nrow(x))。如果有设置分层因子,采样样本可以根据分层因子提取。
nodesize = 1, # 设置终端节点的最小值,分类判别默认为1,回归默认为5.数值越大,树生长的越小,决策树构建时间越少。
maxnodes = NULL, # 设置决策树最多可拥有的终端节点。
nPerm=1,# 设置每个树中OOB数据的置换次数,以评估变量的重要性。值大于1可以给出稍微稳定的估计,但不是很有效。
do.trace=FALSE, # 设置为TRUE,输出更详细的运行过程到控制台。
corr.bias=FALSE,# 设置对回归进行偏差校正,目前功能还在测试阶段。
xtest=NULL,# 设置测试集自变量数据框
ytest = NULL, # 设置测试集因变量
weights=NULL, # 因变量权重
replace = TRUE, # 有放回的样品抽样
classwt = NULL, # 设置分类的先验值,分类先验值不需要加起来=1。
cutoff = c(1/3,1/3,1/3), # 为每个分类水平设置分类阈值。即,一个样本的投票率最高的分类,需要高于该分类的阈值,才能作为属于该类的样本。默认1/分类数。
strata=NULL,# 用于样本分层的因子变量
)
print(RF) # 默认参数计算出的OOB error rate为69.44%。
#summary(RF)
RF$call #运行命令
RF$type #分析类型:分类
RF$classes # 分类信息
RF$y # 因变量数据,此处即为分类变量信息
RF$ntree # 设置及产生的决策树数量
RF$mtry # 构建决策树的自变量数量。
RF$inbag # 每个样本在构建每棵决策树时的使用情况。
RF$predicted # 样本预测结果
RF$forest # 随机森林中的决策树
k1 = getTree(RF, k=1, labelVar=TRUE) # 提取指定第一棵(k=1)决策树
k1 # 输出结果包含6列数据。
#left daughter the row where the left daughter node is; 0 if the node is terminal
#right daughter the row where the right daughter node is; 0 if the node is terminal
#split var which variable was used to split the node; 0 if the node is terminal
#split point where the best split is; see Details for categorical predictor
#status is the node terminal (-1) or not (1)
#prediction the prediction for the node; 0 if the node is not terminal
RF$test # 如果设置了测试集xtest或ytest,结果包含预测结果、OOB分类错误率和混肴矩阵等结果。
RF$err.rate # Out-Of-Bag(OOB)分类错误率,oob error(袋外误差) = 被分类错误数/总数。随机森林判别分析才包含此结果。
RF$confusion # 混淆矩阵(confusion matrix),比较了预测分类与真实分类的情况,显示判别分析的误差率。行名表示实际的类别,行数值之和是该类别包含样本数,列名表示随机森林判定的类别,class.error代表了错误分类的样本比例。A类别共有12个样本,只有2个样本分类正确,分类错误率(class error)为10/12=0.8333。整体class error=mean(RF$confusion[,4])=0.6944,随机森林判别分析才包含此结果
RF$votes # 行为样本,列为分类信息,数据为随机森林分析中袋外数据各样本在所有决策树中"投票"给各分类的比例或数量。如CKA1在所有决策树中被预测为A的比例为0.3976。随机森林判别分析才包含此结果。
RF$oob.times # 每个样本作为袋外数据,计算OOB error的次数。
RF$importance # 包含分类数+2列数据,每个自变量对每个分类的平均正确性降低值(mean descrease in accuracy),后两列分别为变量对所有分类的MeanDecreaseAccuracy和MeanDecreaseGini。
RF$importanceSD # 变量重要值的置换检验的标准误,最后一列为MeanDecreaseAccuracy置换检验的p值。
RF$localImportance # 行为自变量,列为样本。[i,j]值表示第i个自变量对第j个样本正确分类的重要性。
RF$proximity # 样本相似性测量值,基于每对样本同时出现在决策树终端节点的比例。生成树时没有用到的样本点所对应的类别可由生成的树估计,与其真实类别比较即可得到袋外预测(out-of-bag,OOB)误差,即OOB estimate of error rate,可用于反映分类器的错误率。此处为为69.44%,显示分类器模型的精准度是不高的,不能有效识别分组。
图3|randomForest默认参数随机森林模型构建结果,print(RF)。误差率高达69.44%,模型性能不佳。Confusion matrix比较了预测分类与真实分类的情况,class.error代表了错误分类的样本比例,A 组的12个样本中只有2个正确分类。
2.2 randomForest包进行随机森林分类分析调优参数
ntree(构建决策树数量),mtry(用于构建决策树的变量数)和maxnodes(最大终端节点数)是随机森林分析中影响分析结果的重要参数。这些参数的值都不是越大越好,都需要找到一个合适的值,调参的最终目的就是要降低分类或回归错误率。
2.2.1 最佳终端节点数、变量数和决策树数量分别调节
使用for循环或sapply可用于单独调整maxnode、mtry和ntree其中一个或两个参数。此步可用于寻找maxnode、mtry和ntree三者最佳组合时,用于设置三者的测试值区间。调参时,非调参参数,必须与构建模型时的参数设置一致,否则可能调优参数构建的模型与调参过程产生的模型结果不一致。我分析过程中发现randomForest()中的importance的设置会导致模型结果不一致,所以调参时一定要设置importance=TRUE。
# ntree调参
## 方法1:计算最佳ntree,选择一个较大的ntree数目,然后计算error rate最小的ntree数目
##随机森林分析结果从混淆矩阵(confusion)计算的class error和OOB error rate结果有些微差别##
##所以调参的时候,要使用统一的标准进行调整##
##绘制error rate图,
set.seed(12345);
rf = randomForest(x = spe[-c(1:2)],
y= factor(spe[[2]]),
importance=TRUE,# 评估预测变量的重要性,调参时必须设置
ntree = 10000
)
# 计算袋外误差最小的ntree
#rf$err.rate
##第一列为整体OOB error rate,后面为每个分类因子的OOB error rate##
which.min(rf$err.rate[,1])
rf$err.rate[which.min(rf$err.rate[,1]),]
##在其它参数默认的情况下,1棵决策树时,error rate最低=0.5333。##
#summary(rf) # 绘制分类正确率
plot(rf) # 也可绘图查看趋势,但是不太直观
legend("bottomright",legend = colnames(rf$err.rate),pch=20,col = c(1:4))
##但是此种方法没有输出ntree=5时对应的混淆矩阵,不能计算ntree=5的class error##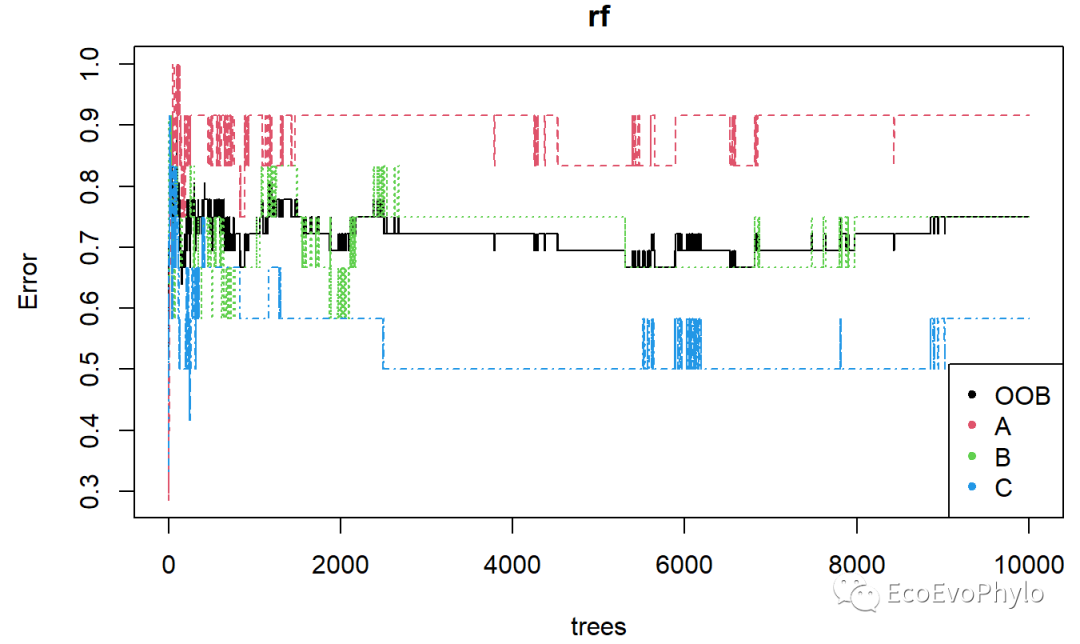
图4|error rate随ntree值的变化图。随机森林分析结果从混淆矩阵(confusion)计算的class error和OOB error rate结果可能有些微差别
## 方法2:ntree[1:100]区间循环检测最佳ntree,根据class error进行判断。
detect_ntree = function(i,...){
set.seed(12345);
rf = randomForest(x=spe[-c(1:2)],y=factor(spe[,2]),
importance=TRUE,# 调参时必须设置
ntree = i,...);
res = data.frame(ntree = i,class.error = mean(rf$confusion[,4]));
return(res);
}
ntree = sapply(seq(1,100,1),
detect_ntree
)
#ntree
ntree[,which.min(ntree[2,])]# ntree=1时,class error也是最低=0.4825class error与error rate都是基于OOB数据计算的,所以class error与error rate的值虽有些微差别,但是趋势是一致的,error rate最低时,class error值也最低。所以实际调参时使用方法1即可,运行速度更快。
# maxnode调参
##从3开始,按1递增maxnode到样本数,计算class error
maxnode = data.frame(row.names =seq(3,nrow(spe),1))
for (i in seq(3,nrow(spe),1)){
set.seed(12345);
rf = randomForest(x = spe[-c(1:2)],
y= factor(spe[[2]]),
maxnodes = i,
importance=TRUE,# 调参时必须设置
ntree = 1
)
maxnode[paste(i,"",sep = ""),1] = mean(rf$confusion[,4])
}
## 计算袋外误差最小的ntree
library(dplyr)
maxnode = arrange(maxnode,V1)
maxnode # maxnode=3的分类错误率最低=0.4635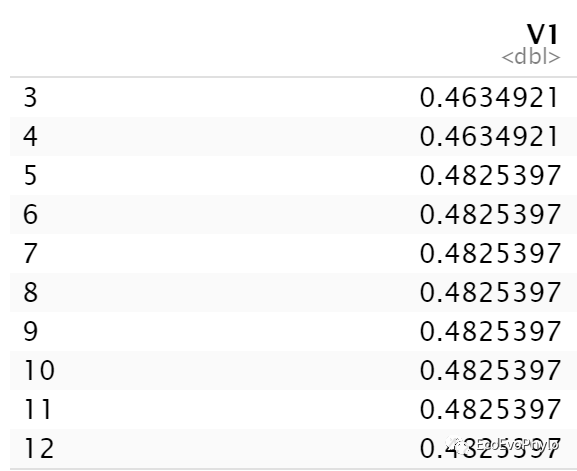
图5|maxnodes调参结果,maxnode。maxnodes=3的分类错误率最低=0.4635
# maxnode调参
##从3开始,按1递增maxnode到样本数,计算class error
maxnode = data.frame(row.names =seq(3,nrow(spe),1))
for (i in seq(3,nrow(spe),1)){
set.seed(12345);
rf = randomForest(x = spe[-c(1:2)],
y= factor(spe[[2]]),
maxnodes = i,
importance=TRUE,# 调参时必须设置
ntree = 1
)
maxnode[paste(i,"",sep = ""),1] = mean(rf$confusion[,4])
}
## 计算袋外误差最小的ntree
library(dplyr)
maxnode = arrange(maxnode,V1)
maxnode # maxnode=3的分类错误率最低=0.4635## 方法2:使用caret包中的train函数检测最佳mtry
### ?trainControl,查看各参数意义
cntrl = trainControl(
method = "repeatedcv", # 可改用OOB error rate方法
number = 4, # 设置k-folds,此值对最后的结果影响很大。样本量较少时。此值可设置小一些。
repeats =6, # 设置检测重复次数
#p = 2/3, # the training percentage
search = "random", # 可选"grid"
verboseIter = FALSE,
returnData = FALSE,
returnResamp = "final"
) # 设置方法
set.seed(12345)
model <- train(x=spe[-c(1:2)],
y=spe[,2],
method = "rf",
trControl = cntrl
)
### 查看最佳mtry
model$bestTune # 最佳mtry=220
##search设置不同,结果差异悬殊。私以为当数据噪声大的时候,不适合用此方法调优##
##可以在对特征变量筛选过后,使用此方法调优mtry##随机森林的决策树数量肯定要大于1,如果决策树数量为1,其实相当于做决策树分析。随机森林分析中不会用所有特征变量构建决策树,如果构建模型时使用了所有特征变量,其实相当于做bagging。
2.2.2 确定最佳终端节点数、变量数和决策树数量组合
根据我的经验,对ntree、mtry和maxnodes参数分别调参(固定其中2个值,寻找另一个值的最佳参数),再组合三个参数进行随机森林分析,得到的error rate不一定是最低值,反而可能没有其中一个参数为最优时,得到的error rate低。所以我都是寻找在三个参数的最佳组合,但是这样运行花费的时间会多一些。可以使用sapply()进行循环运算或者parallel进行多线程运算,节省时间。
# 寻找maxnode、mtry和ntree的最佳组合
##参数的数值区间,可以根据单个参数的调参结果设置,可以节省时间。
##从3开始,按1递增maxnodes=36
##从2开始,按1递增mtry=100
##从1开始,按1递增ntree=50 # 前面的检测结果显示在较低的ntree,得到更低的class error
##节省时间,也可将决策树设置为一个固定值,然后计算每个maxnode和mtry组合对应最小error rate的树集。
name =c()
for (i in seq(3,nrow(spe),1)){
name = c(name,paste(i,seq(2,100,1),sep = "_"));
}
length(name) #3366个组合
#err = lapply(strsplit(name,"_"),as.numeric)
##ntree设置为固定值,则使用此err数据,计算error rate。##
##使用此组合,计算速度更快,此处只是介绍一下如何使用循环计算class error,
##后面都统一使用error rate调参。
names = c()
for (i in name){
names = c(names,paste(i,seq(2,50,1),sep = "_"))
}
length(names) #164934个组合
# 将maxnode、mtry和ntree拆分,将数据以列表形式储存
err = lapply(strsplit(names,"_"),as.numeric)
##计算class error时使用##
## 检测最佳终端节点数、变量数和决策树数量的组合函数
detect_para = function(err){
#library(randomForest);
set.seed(12345); #保证结果可重复
rf = randomForest(x = spe[-c(1:2)], # 此处需要替换为自己的数据
y= factor(spe[[2]]),# 此处需要替换为自己的数据
importance=TRUE,# 调参时必须设置
maxnodes = err[[1]],
mtry = err[[2]],
#ntree = err[[3]] # 计算class error时使用,需要~14min
ntree = 50 # 计算error rate时使用,需~23s。
)
res = data.frame(maxnode = err[[1]],
mtry = err[[2]],
#ntree = err[[3]], # class error
#class.error = mean(rf$confusion[,4]) # class error
ntree = which.min(rf$err.rate[,1]),# 计算error rate时使用
error.rate = rf$err.rate[which.min(rf$err.rate[,1]),1]# OOB error rate
)
return(res)
}
#test = detect_para(err[[1]])
# parallel多核运行函数--加快运行速度
library(parallel);
cores = detectCores()-2;
cl = makeCluster(cores);
clusterExport(cl, c("spe"));
clusterEvalQ(cl, library(randomForest));
system.time(
{
results <- parSapply(cl, err, detect_para); # 10 tasks
}
)
stopCluster(cl);# 组合越多,花的时间越长。
##stopCluster(cl),并行运算的最后一步,必须运行此命令,否则CPU会一直被占用,下次使用时会报警告信息。
results[,which.min(results[4,])] 逐一循环ntree设置ntree= err[[3]]时,结果:maxnode=5,mtry=80,ntree=3时class error最低=0.3641。
设置ntree= 50时,结果:maxnode=5,mtry=80,ntree=3时error rate最低=0.3571。
使用确定的调优参数,构建随机森林模型。很多时候模型参数会经过不止一次的调整。先看一下第一次调优之后,模型的性能有没有提高。
袋外误差可以使用1)Cross-validation(交叉验证);2)the validation 验证集方法)进行验证。随机森林分析使用2/3的样本用于构建决策树,1/3样本作为袋外数据(out-of-bag,OOB)进行模型验证。在树集足够大的情况下,OOB方法等同于cross-validation。随机森林一般不用分训练集和测试集进行分析,如果需要与其它模型进行比较,可以在分析时随机选择部分样本作为训练集构建模型,然后使用在函数中设置测试集或predict()函数预测测试集样本分类准确性。
# 基于最佳参数组合,将数据划分为训练集与测试集,检测模型准确性
##随机森林分析使用2/3的样本用于构建决策树,1/3样本作为袋外数据(out-of-bag,OOB)进行模型验证。在树集足够大的情况下,OOB方法等同于cross-validation。随机森林一般不用分训练集和测试集进行分析,如果需要与其它模型进行比较,可以在分析时随机选择部分样本作为训练集构建模型,然后使用在函数中设置测试集或predict()函数预测测试集样本分类准确性。
set.seed(12345)
sa = sample(2,nrow(spe),prob=c(2/3,1/3),replace = TRUE) #2/3作为训练集,1/3作为测试集。
##随机种子必须在运行randomForest()的前一句运行,中间穿插其它函数会影响结果的可重复性##
set.seed(12345)
train = randomForest(x=spe[sa == 1,-c(1:2)],y=factor(spe[sa == 1,2]),
###randomForest()可以直接设置测试集,结果中的train$test会包含测试集的预测结果###
xtest = spe[sa==2,-c(1:2)],ytest = factor(spe[sa==2,2]),
importance=TRUE,
maxnodes = 5,
mtry = 80,
ntree = 3)
train$predicted #只包含训练集样本的预测结果
mean(train$confusion[,4])
##训练集分类错误率为0.8194,比默认参数的class error = 0.6944高。
train$test$predicted # 测试集预测结果
mean(train$test$confusion[,4])
##测试集预测class error=0.8,错误率很高。所以,构建模型的数据集有任何变动,都应该重新调参。如果数据要分训练集和测试集,一开始就只能使用训练集进行调参。另外如果样本数量不多,不宜划分训练集和测试集进行随机森林,训练集每个分类有>30-50样本更好。
##现在使用所有数据构建模型,然后预测测试数据集
set.seed(12345)
RF.best = randomForest(x=spe[-c(1:2)],y=factor(spe[,2]),
importance=TRUE,# 调参时必须设置
maxnodes = 5,
mtry = 80,
ntree = 3)
#rfPermute::confusionMatrix(RF) # 未调参随机森林模型,分类准确率为30.56%。
rfPermute::confusionMatrix(RF.best) # 分类准确率为64.29%
set.seed(12345)
sa = sample(2,nrow(spe),prob=c(2/3,1/3),replace = TRUE) #1/3作为测试集。
##预测测试集样本属于某类别的概率
#pred = predict(RF.best,newdata = spe[sa==2,-c(1:2)],type = "prob")
### 预测测试集样本属于那个类别
pred = predict(RF.best,newdata = spe[sa==2,-c(1:2)],type = "class")
pred
pred.res = table(pred,spe[sa==2,2]) # 混淆矩阵
Accur.rate = round(sum(pred.res[row(pred.res) == col(pred.res)])/sum(pred.res),2)
Accur.rate #分类准确率达到100%,但是因为构建模型也使用了测试集数据,结果只能说明模型对模型内样本的分类准确性很高。
##或者使用confusionMatrix()计算混淆矩阵
library(caret) # caret包可用于计算分类和回归模型中变量的重要性,及使用重采样评估模型调整参数对性能的影响。
caret::confusionMatrix(pred,factor(spe[sa==2,2])) # 只能用于“class”的预测结果,输出结果中还有Kappa指数等信息。
通过调参随机森林判别分析的分类准确率比使用默认参数的分类准确率提高了33.73%左右,但是~35.71%的class error还是很高,所以后面根据变量重要性排序后,重新筛选变量进行随机森林分析,看能否进一步降低分类误差率。
随机森林在某些噪音较大的分类或回归分析中可能会过拟合(overfitting)。为了得到一致假设而使假设变得过度复杂称为过拟合(overfitting),过拟合表现在训练好的模型在训练集上性能表现好,但是在测试集上性能表现差。模型复杂度过低、特征变量过少,模型在训练集和测试集中的效果都差,则为欠拟合(underfitting),反之,在训练集和测试集中的效果都好,则为适度拟合(right fitting)。

图6|第一次调优参数后随机森林模型的分类准确率及置信区间,rfPermute::confusionMatrix(RF.best) 。
2.3 筛选构建模型变量:Variable Importance Measures
确定最佳参数,构建完随机森林模型后,为进一步提高模型准确率,可以根据特征变量重要性排序,进一步筛选变量(重要性较低特征变量可能对模型构建存在负效应),然后重新进行随机森林分析。
变量筛选方法:
1) 根据随机森林分析重要性值排序,选取top特征变量(可以选择跟调参mtry相同数量的变量,还有推文推荐选取大于0.05的OTU;对于组间差异较小的样本,该值可能会降至0.03,https://mp.weixin.qq.com/s/58VAF03uO3nBPfp7eboqUA?);
2) 交叉验证选择重要特征变量数量;
3) 使用Boruat包通过随机森林进行特征选择。
2.3.1 特征变量重要性排序
随机森林判别分析使用Gini index,回归分析使用RSS指数对用于构建模型的变量进行重要性分析。两者表示模型加上某个变量后,RSS或Gini index降低的数量,值越大表示该变量越重要(参考:https://blog.sciencenet.cn/blog-661364-728330.html)。randomeForestI()提供了MeanDecreaseAccuracy和MeanDecreaseGini两个指数,对特征变量的重要性进行排序。
# 使用调参后参数,进行随机森林分析
set.seed(12345); #保证结果可重复
RF.best = randomForest(x = spe[-c(1:2)], # 此处需要替换为自己的数据
y= factor(spe[,2]),# 此处需要替换为自己的数据
importance=TRUE,# 调参时必须设置
maxnodes = 5,
mtry = 80,
ntree = 3,
localImp = TRUE, # 计算自变量对样本的重要性。
proximity = TRUE,# 计算行之间的接近度
oob.prox = TRUE,#只根据袋外数据来计算接近度
norm.votes = TRUE, # 默认以比例显示投票结果,FALSE以计数形式展示。
Perm = 100
)
rfPermute::confusionMatrix(RF.best) # 分类准确率=64.29%。
summary(RF.best) # 会同时绘制分类准确率折线图,如图所示,此模型对A类别分类效果较差。
# 变量重要性值
##RF.best$importance #包含分类数+2列数据,
##每个自变量对每个分类的平均正确性降低值(mean descrease in accuracy),
##后两列分别为变量对所有分类的MeanDecreaseAccuracy和MeanDecreaseGini(节点不纯度减少值)。
##两个值越大,变量的重要性越大。
##提取每个变量对样本分类的重要性
RF.best$importanceSD # 变量重要值的置换检验的标准误,最后一列为MeanDecreaseAccuracy置换检验的p值。
impor = data.frame(importance(RF.best),MDA.p = RF.best$importanceSD[4])
head(impor) # 提取变量重要性值及置换检验p值.
#localim = data.frame(RF.best$localImportance) # 变量对某个样本分类正确性的影响。
## 将变量按重要性降序排列
#impor = impor[with(impor,order(MeanDecreaseGini,MeanDecreaseAccuracy,decreasing =TRUE)),]
impor = arrange(impor,desc(MeanDecreaseAccuracy),desc(MeanDecreaseGini)) # 优先考虑那个指数,就把该指数放在前面。
head(impor)
varImpPlot(RF.best) # 绘制森林图,默认绘制重要性top30的变量。MeanDecreaseAccuracy衡量把一个变量的取值变为随机数,随机森林预测准确性的降低程度。该值越大表示该变量的重要性越大。MeanDecreaseGini通过基尼(Gini)指数计算每个变量对分类树每个节点上观测值的异质性的影响,从而比较变量的重要性。该值越大表示该变量的重要性越大。
MeanDecreaseGini通过基尼(Gini)指数计算每个变量对分类树每个节点上观测值的异质性的影响,从而比较变量的重要性。该值越大表示该变量的重要性越大。
基尼不纯度(Gini Impurity):根据节点中样本的分布对样本分类时,从节点中随机选择的样本被分错的概率。节点n的基尼不纯度是1减去每个类(二元分类任务中是2)的样本比例的平方和。具体可参考:独家 | 一文读懂随机森林的解释和实现(附python代码)-阿里云开发者社区 (aliyun.com)。
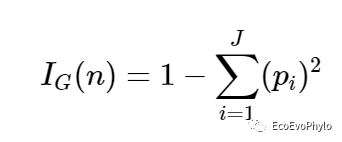
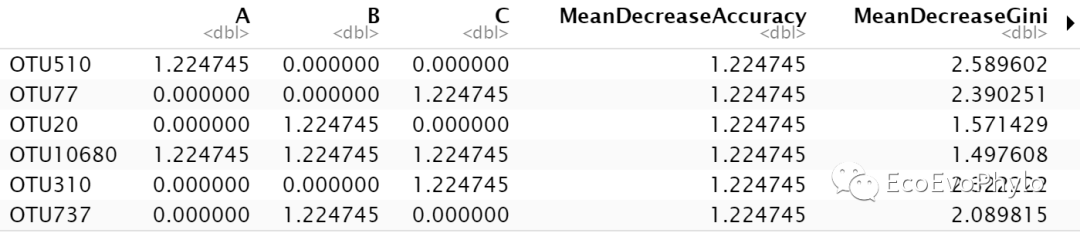
图7|按MeanDecreaseAccuracy降序排列的特征量重要性排序,impor。
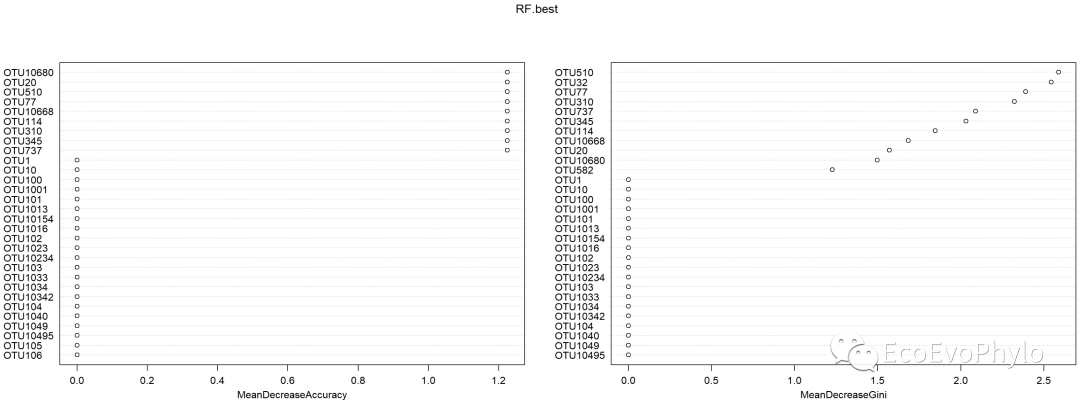
图8|top30变量重要性排序图,varImpPlot(RF.best)。
# 使用top30变量重新构建模型
#keep.data = subset(spe[,-c(1:2)],select = rownames(impor[1:30,]))
set.seed(12345)
RF.best2 = randomForest(x=spe[rownames(impor[1:30,])],
y=factor(spe[,2]),
importance = TRUE
)
library(rfPermute)
rfPermute::confusionMatrix(RF) # 未筛选变量,默认参数,模型分类正确率为30.56%
rfPermute::confusionMatrix(RF.best2) # 返回包括置信区间的混淆矩阵。
## 筛选完变量后,未调参,使用默认参数,分类正确率为36.11%,升高了5.55%,表明进行变量筛选是有必要的。
summary(RF.best2) # 会同时绘制分类准确率折线图,如图所示,此模型对B类别分类效果较差。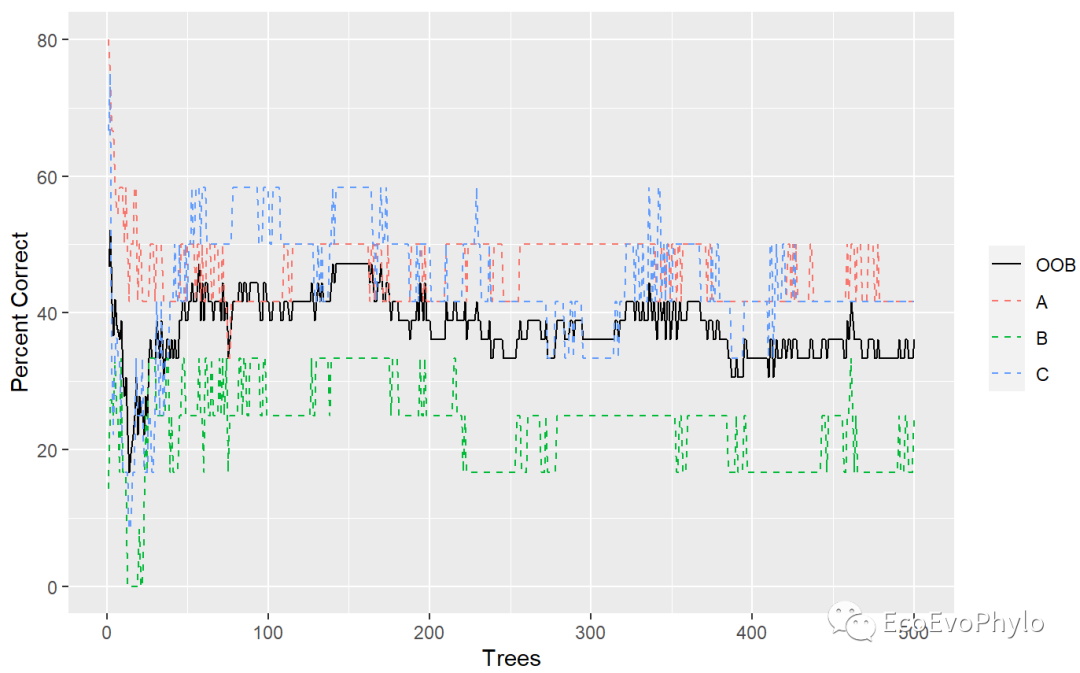
图9|top30变量构建模型分类准确率图,summary(RF.best2)。
2.3.2 交叉验证筛选构建模型变量
# 交叉验证重新筛选构建模型变量
## 交叉验证是指将数据分为不同的训练集/测试集,训练集用于构建模型,然后使用测试集计算模型分类准确性。
## 使用replicate()函数重复10次交叉验证
##step = 0.5,scale="log"设置交叉验证每步移除变量的比例,分析时从所有变量逐步移除到只剩一个变量。
##cv.fold设置交叉验证的fold数
#rfcv(spe[-c(1:2)], factor(spe[,2]), scale="log",cv.fold = 10,step = 0.5) # 单次交叉验证
##step= -10,scale=FALSE,设置交叉验证每步移除的变量数,分析时从所有变量每步减少10个变量,直到剩余变量<=10为止。
set.seed(12345)
cv.res <- replicate(10, rfcv(spe[-c(1:2)], factor(spe[,2]), scale=FALSE,cv.fold = 10,step = -10), simplify = FALSE)
#print(cv.res)
cv.res[[1]]$n.var # 交叉验证每步使用的变量数量。
cv.res[[1]]$error.cv # 交叉验证每步的error rate。
cv.res[[1]]$predicted # 一个包含交叉验证每步样本预测结果的列表
error.cv <- data.frame(sapply(cv.res, "[[", "error.cv"),
mean= rowMeans(sapply(cv.res, "[[", "error.cv"))) # 提取10次交叉验证每步的误差率,并计算均值,构成数据表。
##error.cv[which.min(error.cv[,11]),] # 误差率最小(0.6056)的变量数=320.
## 绘制10次重复的cv error(绿色显示)及cv error的均值(红色显示)
matplot(cv.res[[1]]$n.var, error.cv, type="l",
lwd=c(rep(1, 10), 2),
col=c(rep("green", 10), "red"), lty=1, log="x",
xlab="Number of variables", ylab="CV Error")
##图中可以看出10次重复交叉验证的一致性不高,我认为这表明数据中存在的分类噪音很高,
##对变量进行进一步筛选是很有必要的,可以只保留上面调参后mtry=80个变量,也可以保留此步的320个变量。
##此数据集样本只有36个,变量数量远超样本数,这里选择top30或者80更好。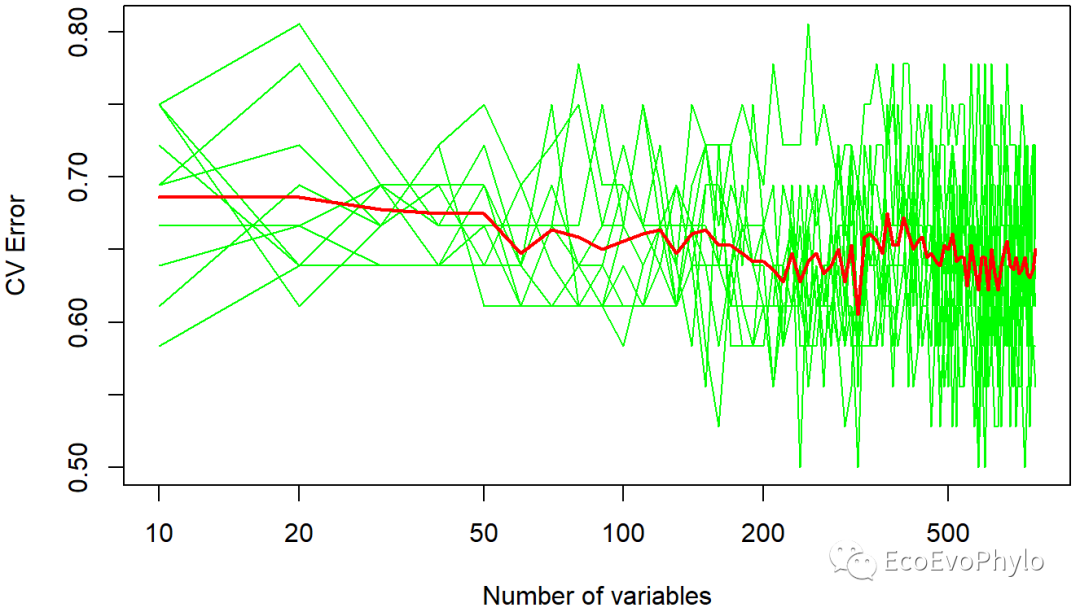
![]() 图10|10次交叉验证的error rate图,matplot。图中10次重复交叉验证的一致性不高,我认为这表明数据中存在的分类噪音很高。
图10|10次交叉验证的error rate图,matplot。图中10次重复交叉验证的一致性不高,我认为这表明数据中存在的分类噪音很高。
2.3.3 交叉验证筛选构建模型变量
在更高层次上,Boruat算法会复制所有输入特征(变量),并对特征中的观测顺序进行重新组合,以去除相关性。从而创建“影子特征”。然后使用所有输入特征创建一个随机森林模型,并计算每个特征(包括影子特征)的正确率损失均值的Z分数。如果某个特征的Z分数显著高于影子特征的Z分数,那么这个特征就被认为是重要的;反之这个特征就被认为是不重要的。然后去除影子特征和那些已经确定了重要性的特征,重复上述步骤,直到所有特征都被赋予一个表示重要性的值。方法比较消耗计算机资源。算法结束后,每个特征会被标记为"Confirmed"、"Tentative"或"Rejected"。对于"Tentative"特征,需要分析人员自己抉择是否用于建模。有两种方法进行选择:
1)改变随机种子数,重复运行算法k次,使用k次都标记为“Confirmed”的特征用于建模;
2)将训练数据分为k 折(fold),在每折数据上分别进行算法迭代,然后选择那些在所有k折数据上,都被标记为“Confirmed“的特征。
Boruta在只剩下已confirmed的属性或者迭代次数到了的情况下停止。如果Boruta迟迟不能收敛,可以对Boruta对象使用TentativeRoughFix(),判断特征属性。
#install.packages("https://cran.r-project.org/bin/windows/contrib/4.3/Boruta_7.0.0.zip",
#repos = NULL,
#type = "source")
library(Boruta)
set.seed(12345)
fs = Boruta(spe[-c(1:2)],factor(spe[,2]),
###通过降低pValue或增加maxRuns,可以更好的区分tentative特征###
pValue = 0.05,# 筛选阈值,默认0.01
### 迭代最大次数,先试运行一下,如果迭代完之后,还留有变量,则下次运行,增大迭代次数。##
maxRuns = 1200,
mcAdj = TRUE, # Bonferroni方法进行多重比较校正
doTrace = 1,# 跟踪算法进程
holdHistory = TRUE, # TRUE,则将所有运行历史保存在结果的ImpHistory部分
##getImp设置获取特征重要性值的方法,可以赋值为自己写的功能函数名##
##需要设置优化参数,?getImpLegacyRf,查看更多参数设置注意事项##
getImp = getImpLegacyRfGini,
##getImpRfZ()使用ranger进行随机森林分析,获得特征重要性值,默认返回mean decrease accuracy的Z-scores。##
##getImpRfRaw()使用ranger进行随机森林分析,默认返回原始置换重要性结果##
##getImpRfGini()使用ranger进行随机森林分析,默认返回Gini指数重要性结果##
##getImpLegacyRfZ()使用randomForest进行随机森林分析,默认返回均一化的分类准确性重要性结果##
##getImpLegacyRfRaw()使用randomForest进行随机森林分析,默认返回原始置换重要性结果##
##getImpLegacyRfGini()使用randomForest进行随机森林分析,默认返回Gini指数重要性结果##
##getImpFerns()使用rFerns包进行Random Ferns importance计算特征的重要性。它的运行速度比随机森林更快,必须优化depth参数,且可能需要的迭代次数更多##
##另外还有getImpXgboost,getImpExtraGini,getImpExtraZ,getImpExtraRaw等设置选项##
##参数设置为之前随机森林的调参结果,参数会传递给RandomForest函数##
importance = TRUE,
#ntree=3,maxnodes=7, # 注释掉此句,使用默认参数进行变量筛选
#mtry = 80
##随着迭代的进行,剩余特征变量数<80后,函数会报警告信息,后续的迭代mtry将恢复默认值##
##介意warning信息,可以不用设置mtry##
)
table(fs$finalDecision)
#设置调参后参数,结果有2个变量("OTU521" "OTU86")标记为Confirmed,3个标记为Tentative,765个变量被Rejected #使用默认参数,结果有2个变量("OTU139" "OTU148")标记为Confirmed,0个标记为Tentative,768个变量被Rejected
##holdHistory = TRUE,则可使用attStats()获取特征的重要性统计信息。
#attStats(fs)
#plot(fs)
#plotImpHistory(fs)
select.name = getSelectedAttributes(fs) # 获取标记为Confirmed的特征名。
select.name # 随机森林参数设置不同,结果有明显区别。选择分类正确率高的参数。
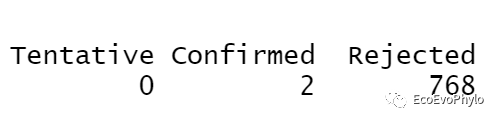
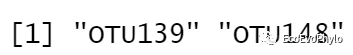
图11|Boruta算法筛选的重要特征变量,table(fs$finalDecision) 和select.name 。
# 下面使用Boruta筛选的特征构建随机森林模型
set.seed(12345)
RF.boruta = randomForest(spe[select.name],factor(spe[,2]),
importance = TRUE)
rfPermute::confusionMatrix(RF.boruta)
##未调参前的分类正确率为50.00%,比使用top30的正确率高。
##要更好的比较的话,还需要进一步对两者进行调参,比较分类正确率。
# Boruta获得的2个特征,是否存在于前面随机森林重要性top30特征呢?
intersect(c("OTU521","OTU86"),rownames(impor[1:30,]))
intersect(c("OTU139","OTU148"),rownames(impor[1:30,]))
##两者的交集为空,可能与数据噪声大或随机森林的参数设置差异有关。
##如果不想漏掉组间差异的重要性特征,可以取两者并集,用于后续分析。
##但此数据集,用两种方法合并的筛选变量,调参后,构建模型的分类准确率反而降低了##
##所以还是要以分类准确率为标准,仔细选择变量组合##
#keep = union(select.name,rownames(impor[1:30,]))如果分析目的只是要鉴定类别间重要的特征变量,进行到此步即可。如果目的是为了构建分类准确率更高的模型,则还需继续进行分析。
2.4 重新构建随机森林及模型评估
2.4.1 保留特征变量,调优参数构建随机森林模型
保留的特征变量,对构建的随机模型的准确率影响很高。而且不同筛选变量方法,会保留不同的特征变量。为了构建性能更好的模型,针对不同的保留的变量组合,应该分别调优参数,构建模型,然后选择模型评测指标更优的变量组合。
# 使用保留的特征变量,进行随机森林调参
#keep = rownames(impor[1:30,]) # maxnode=9,mtry=10,ntree=1时error rate最低=0.2。因为只有一棵决策树,所以后面不使用此参数。
#keep = union(select.name,rownames(impor[1:80,])) # # maxnode=6,mtry=32,ntree=1时error rate最低=0.2667。
#keep = rownames(impor[1:80,]) # maxnode=13,mtry=3,ntree=7时error rate最低=0.3529
#keep = c("OTU521","OTU86") # maxnode=10,mtry=2,ntree=20时error rate最低=0.3056
#keep = c("OTU139","OTU148") # maxnode=4,mtry=2,ntree=12时error rate最低=0.4167
#keep = c("OTU521","OTU86","OTU139","OTU148") # maxnode=10,mtry=3,ntree=18时error rate最低=0.2222
##经过多次变量晒选和模型调参,针对此数据集,基于调参后随机森林参数,使用Boruta筛选的变量构建的模型分类准确性更高,可以使用不同种子数多次筛选或使用replicate(),然后使用特征变量并集,进行随机森林模型构建##
set.seed(12345)
Boruta.rep = replicate(10, Boruta(spe[-c(1:2)],factor(spe[,2]),
pValue = 0.05,
maxRuns = 1200,
mcAdj = TRUE,
doTrace = 0,
holdHistory = TRUE,
getImp = getImpLegacyRfGini,
importance = TRUE,
ntree=3,maxnodes=7,
mtry = 80
), simplify = FALSE)
keep = unique(unlist(sapply(Boruta.rep,getSelectedAttributes)))# maxnode=7,mtry=2,ntree=182时error rate最低=0.1944
length(keep) # 保留了9个变量
keep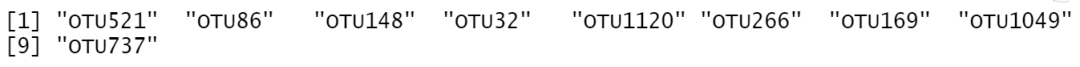
图12|保留特征变量名,keep。
## 寻找maxnode、mtry和ntree的最佳组合
##参数的数值区间,可以根据单个参数的调参结果设置,可以节省时间。
##从3开始,按1递增maxnodes=36
##从2开始,按1递增mtry=length(keep)
##设置ntree=500,然后计算每种maxnode和mtry组合中的,error rate最低的ntree值。
name2 =c()
for (i in seq(3,nrow(spe),1)){
name2 = c(name2,paste(i,seq(2,length(keep),1),sep = "_"));
}
length(name) # 3366个组合
# 将maxnode和mtry拆分,将数据以列表形式储存
err2 = lapply(strsplit(name2,"_"),as.numeric)
detect_para = function(err){
set.seed(12345); #保证结果可重复
rf = randomForest(x = spe[keep], # 此处需要替换为自己的数据
y= factor(spe[[2]]),# 此处需要替换为自己的数据
importance = TRUE,# 必须设置此参数
maxnodes = err[[1]],
mtry = err[[2]],
ntree = 500
)
res = data.frame(maxnode = err[[1]],
mtry = err[[2]],
ntree = which.min(rf$err.rate[,1]),
error.rate = rf$err.rate[which.min(rf$err.rate[,1]),1]# OOB error rate
)
return(res)
}
# parallel多核运行函数--加快运行速度
library(parallel);
cores = detectCores()-2;
cl = makeCluster(cores);
clusterExport(cl, c("spe","keep"));
clusterEvalQ(cl, library(randomForest));
system.time(
{
results <- parSapply(cl, err2, detect_para); # 10 tasks
}
)
stopCluster(cl)
results[,which.min(results[4,])] #结果显示:maxnode=7,mtry=2,ntree=182时error rate最低=0.1944。
##变量组合没选好,可能筛选变量,反而使error rate升高。##
##所以需要使用多种变量筛选方法,提取不同变量组合,然后构建参数调优随机森林结果进行比较,选择error rate较低的模型##

图13|基于保留变量的随机森林最优参数组合,results[,which.min(results[4,])]。
## 重新构建随机森林模型
set.seed(12345)
RF.best3 = randomForest(
x = spe[keep],y = factor(spe[,2]),
maxnodes = 7,mtry = 2,ntree = 182,
importance=TRUE,# 评估预测变量的重要性
localImp = TRUE, # 计算自变量对样本的重要性。
proximity = TRUE,# 计算行之间的接近度
oob.prox = TRUE,#只根据袋外数据来计算接近度
norm.votes = TRUE, # 默认以比例显示投票结果,FALSE以计数形式展示。
nPerm = 100
)
rfPermute::confusionMatrix(RF.best) # 准确率为64.29%
rfPermute::confusionMatrix(RF.best3) # 准确率为80.56%,分类准确率增加了16.27%。
summary(RF.best3) # 会同时绘制分类准确率折线图,模型对C类别分类效果更好。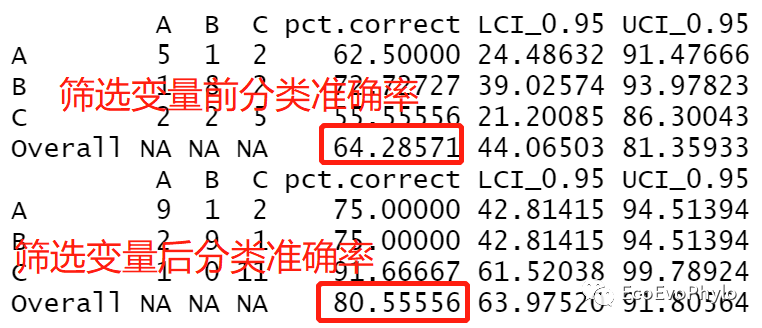
图14|筛选变量前后随机森林模型分类准确率比较。
2.4.2 构建模型性能评估
分类判别模型的性能评测指标包括classification rate,sensitivity和specificity,以及ROC curve下面积。
机器学习模型常用probability methods进行模型性能评估,比如 cross-validation和bootstrap sampling。
# 测试数据准备
##我构建模型的时候没有分训练集与测试集,这里只是使用部分样本,介绍一下如何评估模型性能。
##构建了三个不同测试数据集
library(splitstackshape)
test1 = data.frame(ID = rownames(spe),spe[c("depth",keep)])# stratified提取后,样本名会消失,先提取样本名,重新构建数据框。
table(test1$depth) # 使用所有样本进行测试
set.seed(12345)
test2 = stratified(test1, group=c("depth"),size=10,replace=FALSE)
table(test2$depth) # 每个分类提取的样本数一致。
set.seed(12345)
test3 = test2[sample(nrow(test2),size = nrow(test2)*0.5,replace =TRUE,prob = NULL),]
table(test3$depth)
#test4 = test1[!(test1$ID %in% test3$ID),]
#table(test4$depth)# classification rate评估模型
##RF.best3模型用于预测上述三个测试集
##test1
pred1 = as.data.frame(predict(RF.best3,newdata = test1[,3:ncol(test1)],type="prob"))
pred1 # 获得样本属于某分类的概率
###计算分类矩阵
#apply(pred1,1,which.max) # 样本属于那个分类的概率大,则将该样本判别为该分类。
res1 = as.data.frame(cbind(test1$depth,apply(pred1,1,which.max)))
res1
colnames(res1) = c("Actual_Class","Predicted_Class")
res1$`Predicted_Class`[res1$`Predicted_Class` == 1] = "A"
res1$`Predicted_Class`[res1$`Predicted_Class` == 2] = "B"
res1$`Predicted_Class`[res1$`Predicted_Class` == 3] = "C"
res1
cmat1 = as.matrix(table(Actual = res1$Actual_Class,Predicted = res1$Predicted_Class))
cmat1
cat("Number of classes: ",nrow(cmat1))
cat("Number of Cases: ",sum(cmat1))
cat("Number of Correct Classification: ",diag(cmat1))
cat("Number of Cases per class: ",apply(cmat1,1,sum))
cat("Number of Cases per predicted class: ",apply(cmat1,2,sum))
cat("Distribution of actuals: ",apply(cmat1,1,sum)/sum(cmat1))
cat("Distribution of predicted: ",apply(cmat1,2,sum)/sum(cmat1))
cat("Correct Classification rate: ",sum(diag(cmat1))/sum(cmat1))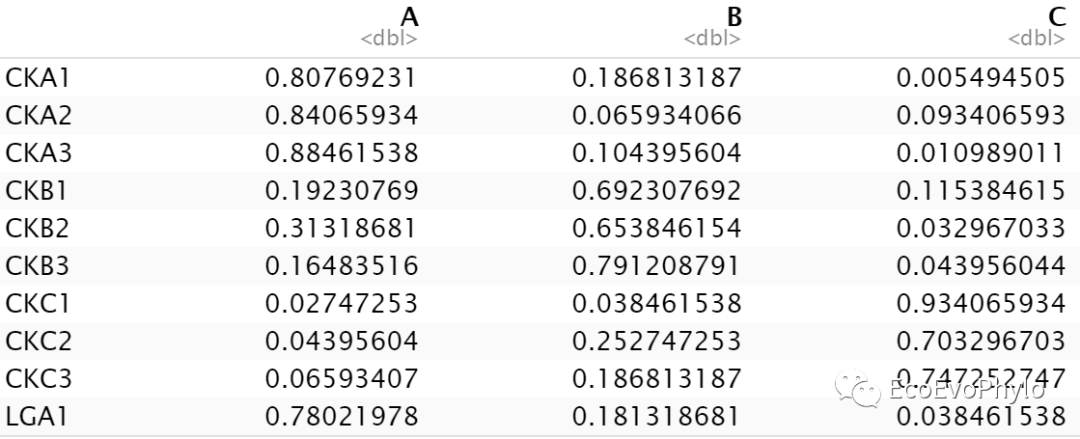
图15|RF.best3模型预测test1样本属于某个分类的概率,pred1。
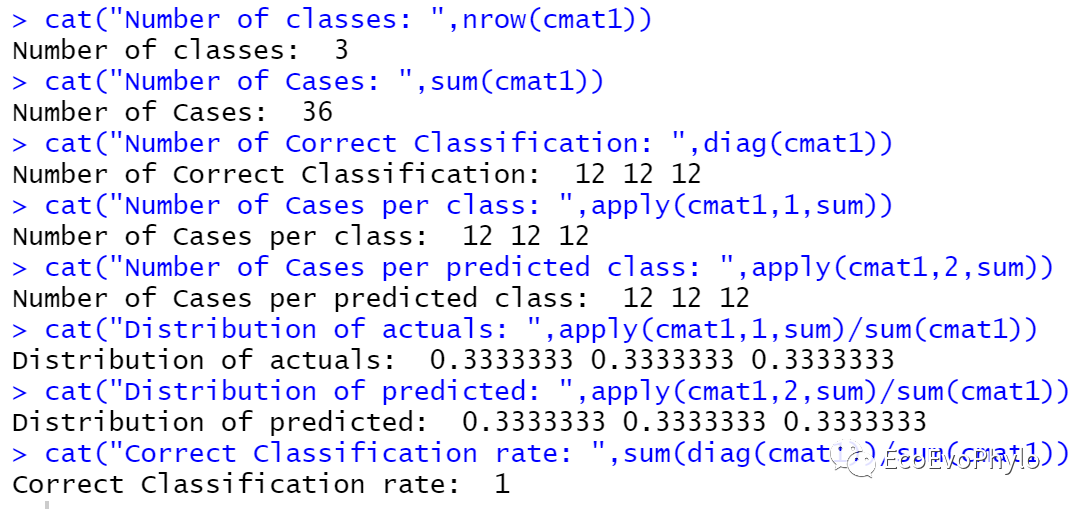
图16|classification rate计算。模型对test1的分类准确率为100%。说明构建的性能高,模型中本身构建过程中的分类错误,在执行预测的时候得到了校正。
Sensitivity&Specificity和ROC curve(或AUC value)是针对二分类(一类为阳性,一类为阴性)模型的概念。多分类模型则需要重构建为二分类模型,然后再绘制ROC曲线。
但多分类模型在使用predict()执行预测功能时,设置type="class"或"response",即可使用caret::confusionMatrix()计算出混淆矩阵、综合统计信息(Accuracy、No Information Rate、 Kappa、binom.test计算95%置信区间单边测验P-value,以及McNemar‘s p-value等)以及基于分类的TPR、TNR等信息。或者直接传递混淆矩阵给caret::confusionMatrix(),不需要再重构为二分类模型
Sensitivity是指正确分类的阳性样本数占所有阳性样本数的比例,也称为True Positive Rate(TPR)。计算方式是:
TP, True Positive,真阳性,正确分类的阳性样本。
FN,False Negative,假阴性,错误分类阳性样本。
TN,True Negative,真阴性,正确分类的阴性样本。
FP,False Positive,假阳性,错误分类的阴性样本。
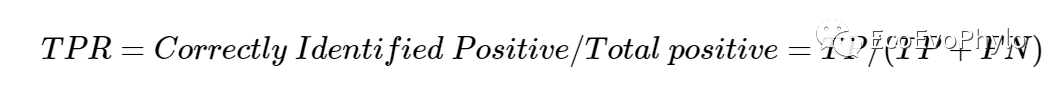
Specificity是指正确分类的阴性样本数占所有阴性样本数的比例,也称为True Negative Rate (TNR) 。
一般好的拟合模型,希望TPR与TNR值越大越好。
# Sensitivity(敏感性)和specificity(特异性)评估模型
## 将test1计算好的混淆矩阵传递给caret::confusionMatrix
CM1 = caret::confusionMatrix(cmat1)
CM1
##test2
pred2 = predict(RF.best3,newdata = test2[,3:ncol(test2)],type="class")
CM2 = caret::confusionMatrix(pred2,factor(test2$depth))
#?caret::confusionMatrix #查看各指数的计算公式
# No Information Rate是指样本最大分类样本所占比例,此处=12/36。
##模型对test2的分类准确率为100%
CM2$table # 混淆矩阵
CM2$positive # 作为阳性样本的分类,三分类水平为NULL。
CM2$overall #accuracy和Kappa统计值向量
CM2$byClass # 每个分类的的sensitivity, specificity, positive predictive value, negative predictive value, precision, recall, F1, prevalence, detection rate, detection prevalence和balanced accuracy统计值。
##test3
pred3 = stats::predict(RF.best3,newdata = test3[,3:ncol(test3)],type="response")
CM3 = caret::confusionMatrix(pred3,factor(test3$depth))
##模型对test3的分类准确率为100%。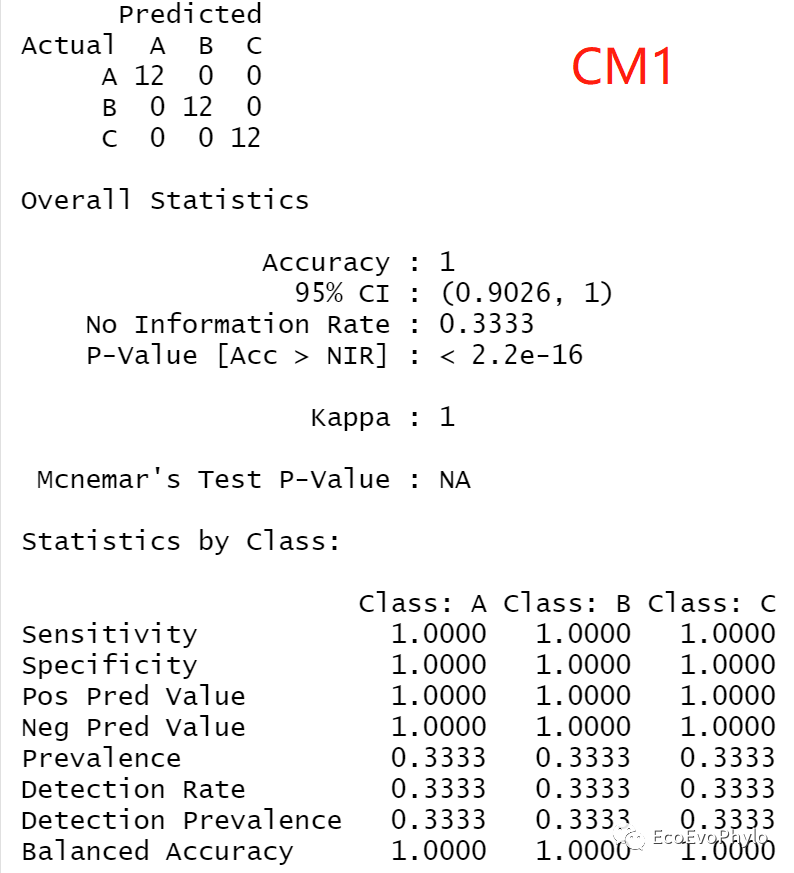
图17|评估指数计算结果,CM1。Kappa或Cohen'Kappa系数是衡量观测精度和预期精度之间关系的统计量,指数的值越大,构建的模型与随机构建模型的一致性越高。Kappa系数低,可能是因为两种情况,1)构建模型比随机模型性能差;2)构建模型比随机模型性能异常强。
• Fair agreement when Kappa is 0.20 to 0.40
• Moderate agreement when Kappa is 0.40 to 0.60
• Good agreement when Kappa is 0.60 to 0.80
• Very good agreement when Kappa is 0.80 to 1.00
Ramasubramanian, Karthik, 和Abhishek Singh. Machine Learning Using R: With Time Series and Industry-Based Use Cases in R. Berkeley, CA: Apress, 2019. https://doi.org/10.1007/978-1-4842-4215-5.p541
Receiver Operating Characteristic (受试者工作特征,ROC) curve,是展示二分类模型性能的图形,其基于分类模型的性能对其进行可视化、组织和选择(Fawcett 2006)。一般ROC图的X轴是假阳性率((1-specificity), FPR),Y轴是真阳性率(sensitivity,TPR),曲线的最高点 是分类概率最大化的阈值点。(《精通机器学些:基于R》)

绘制好ROC curve后,即可求出Area Under the Curve (AUC,曲线下面积) value。AUC表示模型对随机一个样本,能正确鉴定出阳性样本的概率,是一个衡量分类模型性能的有效指标。如果模型没有FPR,则ROC图是一条从(0,0)垂直上升的线,如果模型的预测与随机选择的概率没有差别,则是一条从左下角到右上角的对角线。
ROCR包与pROC都可进行ROC curve分析。但pROC绘制ROC曲线的X轴为真阴性率(specificity,TNR),Y轴为假阳性率(sensitivity, FPR),与常见ROC图的X轴坐标区间有差异。
# ROC curve and Area Under the Curve (AUC) value
##ROC曲线,作为分类变化的阈值。
##pROC中的roc()用于二分类模型,multiclass.roc()用于多分类模型。
##pROC是使用
library(pROC)
## 多分类模型
## direction = ">"表示controls > t >= cases
## levels =c(),可用于指定测试的分类因子。
roc2 = multiclass.roc(test1$depth,pred1,
plot = TRUE,
levels=base::levels(as.factor(test2$depth)),
percent=FALSE, direction = ">")
roc2 # 计算出的AUC值=1
## 因为这个模型的预测准确率是100%。用于绘制ROC不直观,这里直接更改一下预测结果,用于ROC分析。
fpred1 = pred1
fpred1[1,] = c(0.2,0.5,0.3)
fpred1[4,] = c(0.6,0.1,0.3)
fpred1[7,] = c(0.6,0.15,0.25)
froc2 = multiclass.roc(test1$depth,fpred1,
plot = TRUE,
levels=base::levels(as.factor(test2$depth)),
percent=FALSE, direction = ">")
froc2
froc2$response # 样本真实分了你
froc2$predictor # 样本预测分类概率矩阵
froc2$levels # 分类因子
froc2$rocs # 三个分类水平两两ROC分析结果列表
froc2$auc # AUC值,输出三个分类水平的综合AUC值=2/(count * (count - 1))*sum(aucs),aucs所有两两ROC的AUC值,count是指分类水平数量。
froc2$call # 运行代码
froc2$percent # 结果以百分比显示,还是以分数显示
#library(ROCR) # 官方教程只有应用于二分类模型,这里就不用这个函数了。
##多分类模型则需要重构建为二分类模型,然后再绘制ROC曲线。
#??ROCR # 查看官方教程

图18|pROC计算的多分类模型AUC值,roc2。AUC value==2/(count * (count - 1))*sum(aucs),aucs所有两两ROC的AUC值,count是指分类水平数量。
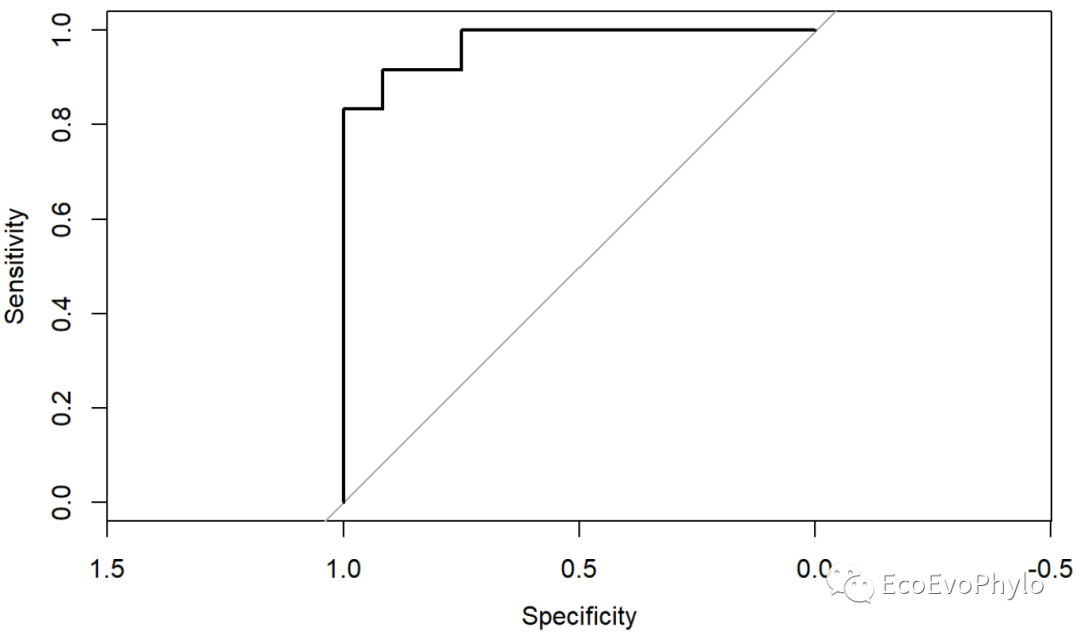
图19|pROC输出的A vs. B的ROC曲线,froc2。
# 变量筛选后数据,分训练集和测试集进行随机森林分析,误差率会不会降低呢?
## 将数据按照2:1分为训练集与测试集,只保留的筛选的特征变量。
set.seed(12345)
sa = sample(2,nrow(spe),replace = TRUE,prob = c(2/3,1/3))
train.data = spe[sa==1,c("grazing","depth",keep)]
test.data = spe[sa==2,c("grazing","depth",keep)]
dim(train.data)
dim(test.data)
set.seed(12345)
RF.best4 = randomForest(
x = train.data[keep],y = factor(train.data[,2]),
xtest = test.data[keep],ytest = factor(test.data[,2]),
maxnodes = 7,mtry = 2,ntree = 182,
importance=TRUE,# 评估预测变量的重要性
nPerm = 100
)
RF.best4$test
caret::confusionMatrix(train$test$predicted,factor(test.data$depth))
# 未筛选变量,测试集预测正确率为23.08%
caret::confusionMatrix(RF.best4$test$predicted,factor(test.data$depth))
# 筛选变量后,模型准确率为76.92%,分类准确率增加了53.84%。综上,可以看到保留变量构建的模型准确率很高,可见构建模型的变量能有效的表征样本分类差异。下面可以绘制美化变量重要性排序图。
RF.best3$importance # 特征变量
## 绘制变量整体重要性
pdf("varimp.pdf",width = 4.5,height = 4.5,family = "Times")
varImpPlot(RF.best3,
sort=TRUE,
type=1, # 选择重要性指数,1 = MeanDecreaseAccuracy,2=MeanDecreaseGini。
n.var = 9,
scale = FALSE, # 使用原始MeanDecreaseAccuracy绘图。TRUE则为标准化后结果。MeanDecreaseGini则无差别。
main = "Variable Importance",
pt.cex = 1.5, # 设置点大小
cex = 1,
color = "black",
pch = 16,
)
dev.off()
## 绘制变量对指定分类的重要性
varImpPlot(RF.best3,
sort=TRUE,
type=1, # 选择重要性指数,1 = MeanDecreaseAccuracy,2=MeanDecreaseGini。
n.var = 9,
main = "Variable Importance",
class = c("A","B")# 可用于绘制变量对指定分类的重要性。
)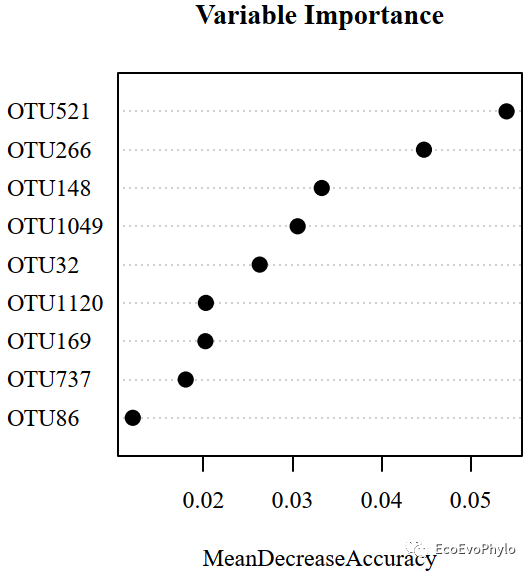
图20|特征变量重要性散点图,varimp.pdf。
随机森林还可以给出每个特征变量对分类变量的作用。
# 偏相关图展示了变量对分类概率(分类)或响应(回归)的边际效应(marginal effect)。##模型构建时需要设置keep.forest=TRUE。p.OTU521 = randomForest::partialPlot(RF.best3, test1[-c(1:2)],x.var = OTU521, col = "red",which.class = "A",main="marginal effect",xlab="OTU521", ylab="Variable effect")p.OTU521 # 输出x,y轴坐标信息# 结果表示低丰度OTU521更易归类为类别A。
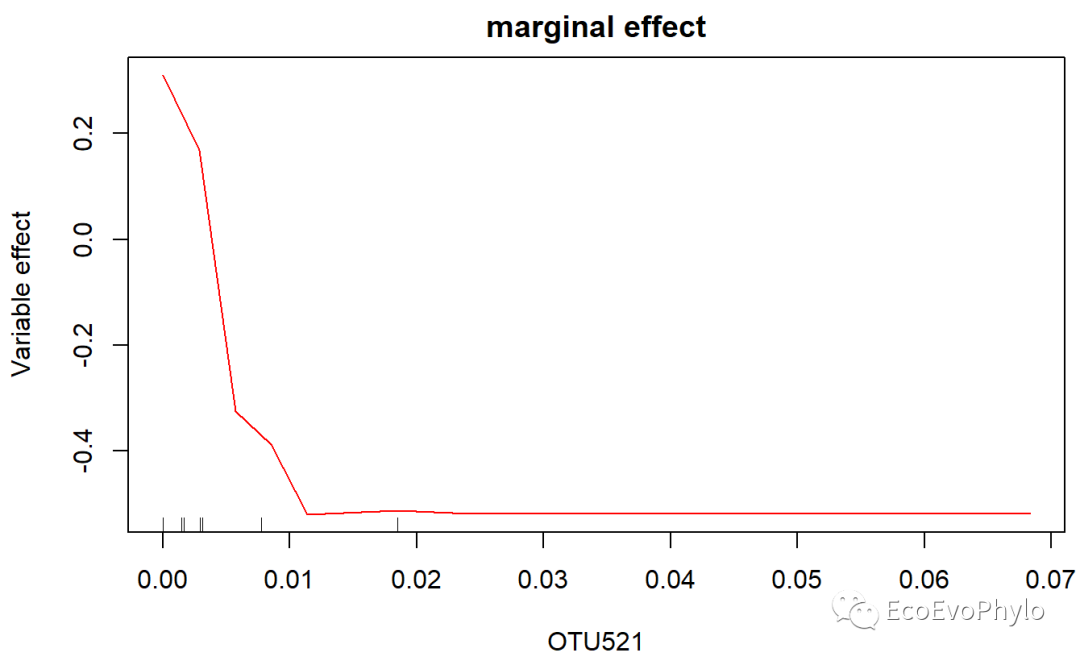
图21|特征变量OTU521对类别A的边际效应。
数据表和代码文件,EcoEvoPhylo公众号留言:平台名称+“random forest”获取。
三、随机森林基础知识
3.1 随机森林简介
随机森林(Random Forest,https://easyai.tech/ai-definition/random-forest/)是一种由决策树构成的集成算法(Ensemble Learning,机器学习方法之一),是一种有监督学习方法。随机森林由很多决策树(Decision Tree,https://easyai.tech/ai-definition/decision-tree/)构成,不同决策树之间没有关联。
随机森林通过对样本和变量进行抽样构建预测模型,即随机生成多个决策树,并依次对样本进行分类。最后将各决策树的分类结果汇总,所有预测类别中的众数类别即为随机森林所预测的该对象的类别,分类准确率提升。
随机森林分析一般将数据分成两组,一组用于构建模型,一组用于验证模型的准确性。最关键的是构建模型。随机森林包含判别或回归分析。1. 随机森林判别分析:一组特征变量和一组分类变量用于构建模型,构建好的模型可用于判别样本的分类信息。2. 随机森林回归分析:一组特征变量和一组定量因变量用于构建模型,构建好的模型可以根据样本的特征变量信息预测样本的因变量指标信息。随机森林分析是非线性分类器,可以挖掘变量之间复杂的非线性的相互依赖关系。在微生物生态中可用于找出导致组间差异的关键成分/生物标志物(Biomarker,物种/代谢物等)。参考:一文读懂“随机森林”在微生态中的应用 (qq.com)
假设训练集中共有N个样本,M个物种,想要用物种的丰度信息预测某个指标(如土壤类型等)。参考:(人工智能(AI)在微生物组中的应用-随机森林分类与回归预测 (qq.com))
(1)首先训练集中随机有放回地抽取N个样本构建决策树,称为自助抽样法(bootstrapping)。
(2)在每一个节点随机抽取m个特征(m<M),将其作为分割该节点的候选特征,每一个节点处的特征数应一致;分类设置为sqrt(n_features),回归设置为1/3,这意味着如果有16个特征,则在每个树中的每个节点处,只考虑4个随机特征来拆分节点。(随机森林也可以在每个节点处考虑所有的特征,则为bagging)。
(3)重复(1)-(2)过程,获得大量决策树;然后对预测进行平均的过程称为bootstrap aggregating(bagging)。bagging与随机森林的差别就是bagging使用所有变量构建决策树,而随机森林只使用部分变量。
(4)利用Out-Of-Bag(OOB)方法检验所有决策树投票权重及评估决策树的准确度。OOB error rate = 被分类错误数 / 总数
(5)对于测试数据集,用所有的树对其进行分类,其类别由众数决定原则生成。
3.1 随机森林名词解释
决策树:if-then-else,类似分类树,通过一系列数据,对样本进行分类或得到回归情况下的连续值。一种直观的模型,可根据询问有关特征值的一系列问题做出决策。具有低偏差和高方差的特征,这会导致过拟合训练数据。
自助抽样法:有放回地对观察值进行随机采样。
随机特征子集:考虑对决策树中每个节点的分割时,选择一组随机特征。
随机森林:使用自助抽样法,随机特征子集和平均投票来进行预测的由许多决策树组成的集合模型。
偏差方差权衡:机器学习中的核心问题,描述了具有高灵活性(高方差),即可以很好地学习训练数据,但以牺牲泛化新数据的能力的模型,与无法学习训练数据的不灵活(高偏差)的模型之间的平衡。随机森林减少了单个决策树的方差,从而可以更好地预测新数据。
基尼不纯度(Gini Impurity):根据节点中样本的分布对样本分类时,从节点中随机选择的样本被分错的概率。节点n的基尼不纯度是1减去每个类(二元分类任务中是2)的样本比例的平方和。在每个节点,决策树要在所有特征中搜索用于拆分的值,从而可以最大限度地减少基尼不纯度。(拆分节点的另一个替代方法是使用信息增益)。然后,它以贪婪递归的过程重复这种拆分,直到达到最大深度,或者每个节点仅包含同类的样本。树每层的加权总基尼不纯度一定是减少的。每个节点的基尼不纯度按照该节点中来自父节点的点的比例进行加权,最终,最后一层的加权总基尼不纯度变为0,也意味着每个节点都是完全纯粹的,从节点中随机选择的点不会被错误分类。虽然这一切看起来挺好的,但这意味着模型可能过拟合,因为所有节点都是仅仅使用训练数据构建的。
3.3 随机森林优缺点
3.3.1 随机森林优点
-
它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
-
它可以判断特征的重要程度。
-
可以判断出不同特征之间的相互影响,包括了变量的交互作用(interaction),即X1的变化导致X2对Y的作用发生改变
-
不容易过拟合
-
训练速度比较快,容易做成并行方法
-
实现起来比较简单
-
对于不平衡的数据集来说,它可以平衡误差。
-
如果有很大一部分的特征遗失,仍可以维持准确度。
-
随机森林对离群值不敏感,在随机干扰较多的情况下表现稳健。
-
随机森林通过袋外误差(out-of-bag error)估计模型的误差。对于分类问题,误差是分类的错误率;对于回归问题,误差是残差的方差。在训练过程中,随机森林的误差近似于袋外误差(out-of-bag error, OOB error)。每棵子决策树都建立在不同的引导样本上,而引导样本会随机舍弃约三分之一的样本。这些被舍弃的样本称为OOB样本。对于已经生成的随机森林,将OOB样本代入随机森林分类器,并将结果与正确的分类相比较。进而,OOB error =分类错误的数目/OOB样本的数目。调参的关键因素就是要让OOB error最低。
-
没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。
3.3.2 随机森林缺点
-
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合(overfitting,为了得到一致假设而使假设变得过度复杂称为过拟合(overfitting),过拟合表现在训练好的模型在训练集上效果很好,但是在测试集上效果差。)。
-
随机森林的缺点是它的算法倾向于样本较多的类别。
-
对于有不同取值的特征变量的数据,取值划分较多的特征变量会对随机森林产生更大的影响,所以随机森林在这种数据上产出的特征变量权值是不可信的。随机森林中水平较多的分类属性的特征变量比水平较少的分类属性的特征变量对模型的影响大。
-
需要的样本量较大,单组样本>30-50
代码及数据链接:链接:https://pan.baidu.com/s/1aEpivP61HZ8dNp3Jg2AOfA?pwd=7k83
提取码:7k83
参考资料:
Ramasubramanian, Karthik, 和Abhishek Singh. Machine Learning Using R: With Time Series and Industry-Based Use Cases in R. Berkeley, CA: Apress, 2019. https://doi.org/10.1007/978-1-4842-4215-5.
https://www.stat.berkeley.edu/~breiman/RandomForests/
随机森林 算法过程及分析:BIGBIGBOAT, http://www.cnblogs.com/liqizhou/archive/2012/05/10/2494558.html
基于MATLAB的随机森林(RF)回归与变量重要性影响程度排序 (qq.com)
独家 | 一文读懂随机森林的解释和实现(附python代码)-阿里云开发者社区 (aliyun.com)
科学网—用随机森林模型替代常用的回归和分类模型 - 李欣海的博文 (sciencenet.cn)
欠拟合的原因以及解决办法(深度学习)_Yellow0523的博客-CSDN博客_欠拟合
R语言randomForest包的随机森林分类模型以及对重要变量的选择(变量选择及交叉验证): https://cloud.tencent.com/developer/article/1870681
一文读懂“随机森林”在微生态中的应用(信息熵等):https://mp.weixin.qq.com/s/58VAF03uO3nBPfp7eboqUA?
randomForest进行随机森林分析(如何设置mtry和ntree参数,ROC):https://www.jianshu.com/p/dac7345e4ae0
人工智能(AI)在微生物组中的应用-随机森林分类与回归预测(train函数使用):https://mp.weixin.qq.com/s?__biz=MzIyNzIyNTczNA==&mid=2247491475&idx=1&sn=8b287625fc3b81f4a3e7b62f48c5e4d8&chksm=e865267adf12af6c8635c6515d5210a097c02a28301dc8923504593611d69db3d80ae2814a93&scene=21#wechat_redirect
欧易探云指南 | 随机森林分析(MeanDecreaseGini值,用来评判物种对模型分类的情况。MeanDecreaseGini 值越大,说明类别分类情况越好):https://www.oebiotech.com/index.php?c=show&id=36
比较全面的随机森林算法总结 :https://www.sohu.com/a/279136744_163476:
推荐阅读
R绘图-物种、环境因子相关性网络图(简单图、提取子图、修改图布局参数、物种-环境因子分别成环径向网络图)
R统计绘图-多变量相关性散点矩阵图(GGally::ggpairs())
R统计绘图-PCA分析绘图及结果解读(误差线,多边形,双Y轴图、球形检验、KMO和变量筛选等)
R统计绘图-corrplot热图绘制细节调整2(更改变量可视化顺序、非相关性热图绘制、添加矩形框等)

EcoEvoPhylo :主要分享微生物生态和phylogenomics的数据分析教程。
扫描二维码,关注公众号。让我们大家一起学习,互相交流,共同进步。
知乎 | 生态媛
学术交流QQ群 | 438942456
学术交流微信群 | jingmorensheng412
加好友时,请备注姓名-单位-研究方向。


















 7888
7888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











