








关注我,让你轻松学会数据可视化
背景:决策树方法在分类、预测、规则提取等领域有着广泛应用。20世纪70年代后期和80年代初期,机器学习研究者J.Ross Quinlan提出了ID3算法以后,决策树在机器学习、数据挖掘领域得到极大的发展。Quinlan后来又提出了C4.5,成为新的监督学习算法。1984年,几位统计学家 提出了CART分类算法。ID3和CART算法几乎同时被提出,但都是采用类似的方法从训练样本中学习决策树。——《Python数据分析与挖掘实战》
一、决策树介绍
决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
从数据产生决策树的机器学习技术叫做决策树学习,通俗说就是决策树。
一个决策树包含三种类型的节点:
- 决策节点:通常用矩形框来表示
- 机会节点:通常用圆圈来表示
- 终结节点:通常用三角形来表示
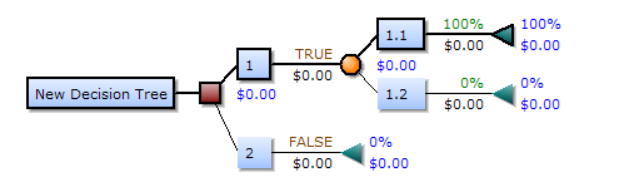
决策树视图
决策树是一树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。对于非纯的叶节点,多数类的标号给出到达这个节点的样本所属的类。构造决策树的核心问题是在每一步如何选择适当的属性对样本做拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下,分而治之的过程。
二、决策树的算法

决策树算法分类
三、信息熵的介绍

05:19
如上视频可能没有字幕,请打开网盘中的内容可以看到字幕:
链接:https://pan.baidu.com/s/1AY3Bz_2FBRlxnfwVbcbT0A
提取码:r7cg
在这里介绍两个概念,分别是信息熵的公式和条件熵的公式:
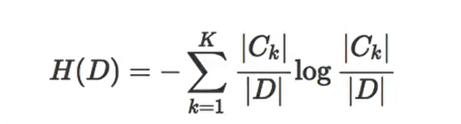
信息熵

条件熵
决策树的划分依据是信息增益:
所谓的信息增益是指特征A对训练数据集D的信息增益g(D,A)定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
�(�,�)=�(�)−�(�|�)
备注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。
四、举例说明信息增益
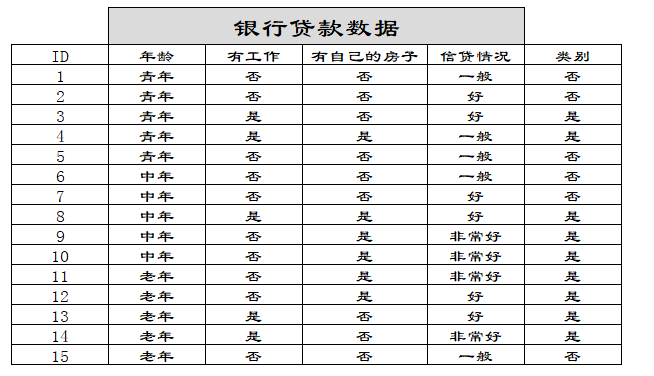
举例数据
假设是二叉树的时候,决策树一般决策结果为如下图:

决策树
在这里,为什么有自己的房子应该放在最开始的地方呢?我们可以通过信息增益的大小可知,根据上面信息增益的公式,我们套用一下:
�(�)=−(9/15)���(9/15)−(6/15)���(6/15)=0.971
然后我们让A1,A2,A3,A4分别表示年龄、有工作、有自己的房子和信贷情况四个特征,则计算出年龄的信息增益为:
�(�,�1)=�(�)−[(5/15)�(�1)+(5/15)�(�2)+(5/15)�(�3)]
�(�1)=−(2/5)���(2/5)−(3/5)���(3/5)
�(�2)=−(3/5)���(3/5)−(2/5)���(2/5)
�(�3)=−(4/5)���(4/5)−(1/5)���(1/5)
同理我们可以计算出g(D,A2)=0.324,g(D,A3)=0.420,g(D,A4)=0.363,相比较来说特征A3的信息增益最大,所以放在最前面。
五、sklearn决策树的API
sklearn.tree.DecisionTreeClassifier(criterion='gini',max_deepth=None,random_state=None)- 在python中决策数中默认的是gini系数,也可以选择信息增益的熵'entropy'
- max_depth:树的深度大小
- random_state:随机数种子
如下我们使用泰坦尼克号的数据举例说明:
# 首先导入需要的包
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import classification_report
from sklearn.tree import DecisionTreeClassifier, export_graphviz
import pandas as pd使用决策树进行预测:
def descision():
"""
决策树对泰坦尼克号进行预测生死
:return:None
"""
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
# 处理数据,找出特征值和目标值
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
print(x)
# 缺失值处理
x['age'].fillna(x['age'].mean(), inplace=True)
# 分割数据集到训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 进行处理(特征工程)
dict = DictVectorizer(sparse=False)
x_train = dict.fit_transform(x_train.to_dict(orient="records"))
print(dict.get_feature_names())
x_test = dict.transform(x_test.to_dict(orient="records"))
print(x_train)
# 用决策树进行预测
dec = DecisionTreeClassifier()
dec.fit(x_train, y_train)
# 预测准确率
print("预测的准确率为:", dec.score(x_test, y_test))
# 导出决策树的结构
export_graphviz(dec, out_file="./tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', 'sex=female', 'sex=male'])
if __name__=="__main__":
descision()可以看到得出的结果:

六、决策树的优缺点
优点:
- 简单的理解和解释,树木可以可视化;
- 需要很少的数据准备,其他技术通常需要归一化。
缺点:
- 决策树学习者可以创建不能很好的推广数据的过于复杂的数,因为会产生过拟合。
改进:
- 随机森林
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









