







WWW 2023
1 intro
1.1 背景
- 现有的轨迹相似度方法通常假定采样的轨迹具有统一且一致的采样率
- 如果两条轨迹能够为它们的大部分样本点形成成对匹配,就认为它们是相似的
- 然而,由于各种原因,轨迹的采样率会有所不同
- 在这种情况下,基于匹配的方法被证明是无效的
- 不仅采样率可能不同,轨迹还有可能有噪声——低质量轨迹
- 假设我们在两条低质量轨迹之间进行相似性连接任务,连接结果可能是不准确的
- 因为噪声位置点可能使两条相似的轨迹远离彼此,或者使两条大相径庭的轨迹接近
- ——>使用一个不受噪声干扰的相似性度量来处理低质量轨迹是很重要的,这样两条低质量轨迹的相似性与相应的高质量轨迹的结果相同。
- 如果一个相似性度量是不受噪声干扰的,我们称它为稳健的
- 假设我们在两条低质量轨迹之间进行相似性连接任务,连接结果可能是不准确的
- 一个好的相似性度量不仅在处理低质量轨迹时保证稳健性,而且要实现高效率
- t2vec 根据深度学习方法学习了轨迹的表示来进行相似性度量,在其中它考虑了模型的稳健性以及其效率
- 然而,在 t2vec 模型中忽略了轨迹的时间信息,使其无法在时空数据库中回答基于相似性的查询,因为轨迹的空间信息和时间信息都是不可或缺的
- ——>考虑时间信息对于相似性度量是非常重要的
- t2vec 根据深度学习方法学习了轨迹的表示来进行相似性度量,在其中它考虑了模型的稳健性以及其效率
1.2 论文研究问题
- 给定一组轨迹T={τ1,…,τn},学习它们的表示V={v1,…,vn}
- 在空间和时间维度上进行稳健的相似性计算
- 学到的表示必须能够反映轨迹的精确移动路径的隐藏时空特征
- ——>基于学到的表示 的两个轨迹的相似性 可以对低质量的轨迹(即,采样率低或有噪声的轨迹)具有稳健性
1.3 论文方法
- 论文提出了基于表示的时空相似性计算(RSTS)模型
- encoder-decoder
- 将空间和时间维度划分为单元来将每个轨迹转换为一个token序列
- 使用一个时空感知损失函数进行训练
2 问题定义
2.1 精确移动路径
- 精确移动路径R={s1,s2,…,sn} 是记录对象连续行进的位置的曲线
- si=([p1,…,pm],t)
- [p1,…,pm] 表示,表示空间特征(例如,经度和纬度)
- t表示该位置被遍历时的相应时间戳
- si=([p1,…,pm],t)
- 由于位置跟踪设备不连续记录位置,因此无法在现实中捕获精确的移动路径
- 可以使用具有相对高采样率的轨迹来表示移动对象的精确移动路径
2.2 轨迹
- 轨迹τ={s1,…,s∣τ∣} 是从对象的精确移动路径中导出的有限、时间有序的样本点序列
- si=([x,y],t)
2.2.3 轨迹表示
- 用向量v∈Rn 在欧几里德空间中表示一个轨迹 τ
- (1) 可以反映轨迹的精确移动路径
- (2) 可以用于测量轨迹之间的时空相似性
- 一个轨迹表示与另一个相近,两个相应的轨迹在空间和时间上也可以被认为是相似的
- (3) 对时空维度低质量轨迹的时空相似性测量是稳健的
2.2.4 问题陈述
给定一组轨迹T={τ1,…,τn},目标是学习它们的表示V={v1,…,vn},用于在时间维度和空间维度(空间坐标)中进行稳健的相似性计算,满足以下约束条件

3 模型
3.1 encoder-decoder架构
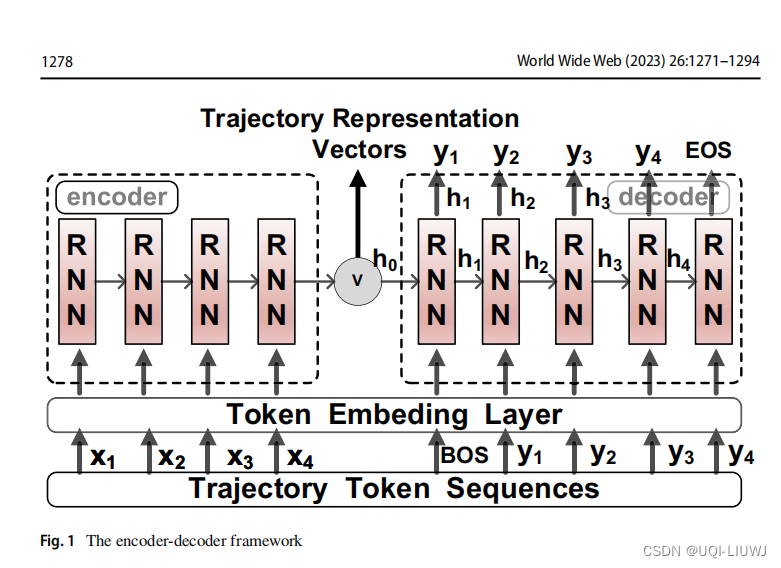
- 给定两个序列x和y,编码器被设计为将x的特征编码成一个表示向量v,而解码器试图将v的特征解码成序列y
- 解码器将v和每个目标输入yi∈y 通过前向计算压缩到隐藏状态hi中
- 对于解码器的每一层,基于上一个隐藏状态hi−1和上一个输入yi−1为每一个token分配一个概率
- 输出预测的yi 具有最大的概率
- 给定一个输入(x,y)
- 编码器-解码器模型的训练目标是最大化条件概率P(y∣x)
- 通过将x编码成v,y是在条件向量v下生成的序列。
- ——>因此,学习到的表示向量v可以有效地反映序列x和y的特征
-
论文是最大化ℙ(R|τ),即给定低质量轨迹τ,最大化对应的原始轨迹的概率
- 所以x应该是τ,y希望是R
3.1.1 轨迹tokenize
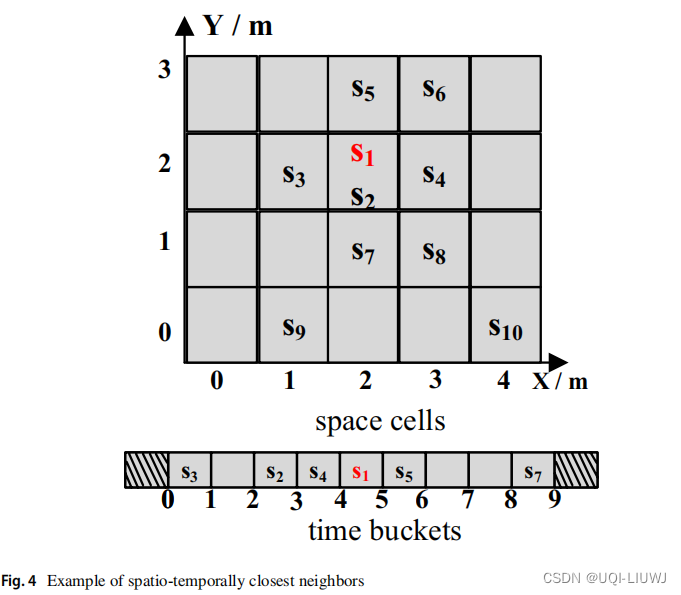
- 首先,将空间划分为等大小的网格单元
- 接下来,根据特定的时间片计数将每个空间单元划分为固定数量的时空单元
- ——》因此,轨迹的每个数据点([x,y],t) 可以用一个特定的令牌表示
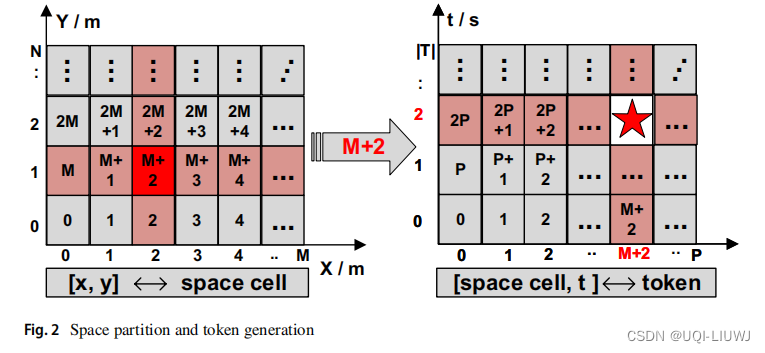
- 如上图,空间被划分为M x N个相等的网格单元。
- 给定一个样本点,如si=([2,1],2)
- 首先基于其x-y坐标为其分配一个空间单元M+2
- 然后基于其空间单元M+2和其时间片t给出一个时空单元
- ——>时空单元2P + M +2作为样本点si=([2,1],2)的token
4.2 生成低质量轨迹
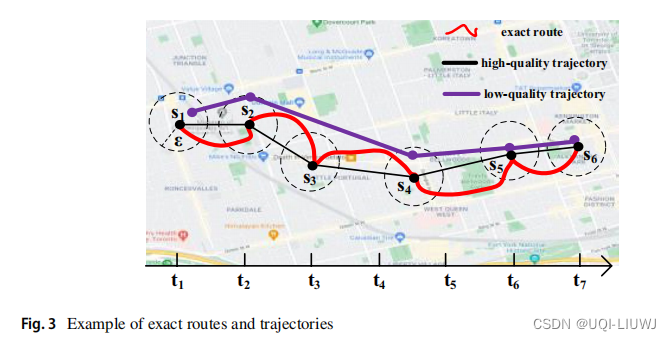
- 对于每个高质量轨迹τb={s1,…,s∣τ∣},丢弃操作随机删除τb 中的某些位置,丢弃率为预定义的 rd
- 扭曲操作随机扭曲τb 中的某些位置,扭曲率为预定义的 rt
- 通过在空间坐标中加入半径为 δs 的高斯噪声,并在时间维度中加入半径为 δt 的高斯噪声,来扭曲 τb
- 扭曲操作随机扭曲τb 中的某些位置,扭曲率为预定义的 rt
3.3 量化时空相似性
3.3.1 时空感知损失函数
- 基于每个目标单元的最近的空间和时间邻居建立了时空感知损失函数
- 在时间t 解码目标单元yt 时,预计会预测到接近yt 的邻居单元
- ——>鼓励解码器为一个接近的邻居分配更多的概率
- 如果一个单元u∈V 在空间上是与目标单元yt 最接近的前∣Ns∣ 个,并且它在时间上是最接近的前∣Nst∣,那么 u 被视为目标单元 yt 的前|Nst∣ 个空间和时间最接近的邻居
- 通常,∣Ns∣ 的值不小于 ∣Nst∣ 的值,因为选择时空最近邻是基于选定的空间最近邻
- 在时间t 解码目标单元yt 时,预计会预测到接近yt 的邻居单元
- Nst 时空邻居单元的权重:
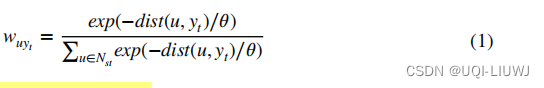
- 为了避免太多的计算,我们只考虑目标单元的一些时空最近邻,其他单元的权重可以忽略
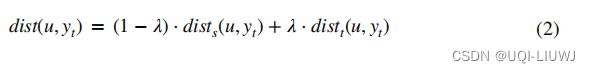
- 时空距离
- 时空感知损失函数
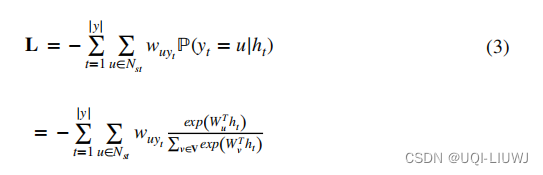
- ht 表示在编码器-解码器框架中时间 t 的隐藏状态
- V是所有时空token组成的词汇
是投影矩阵,它将 ht 从隐藏状态空间投影到词汇空间(即,时空单元空间)
- 【类似于skip-gram】NLP 笔记:Skip-gram_UQI-LIUWJ的博客-CSDN博客
- 背后的原理
- 对于一个目标单元,我们的目标是预测其时空邻居作为每一层的输出
- 损失函数鼓励编码器为这些时空邻居分配更大的概率
- 如果计算出的时空邻居的概率很小,损失就很大
3.3.2 三元组损失函数
- 为了确保快速收敛,应用三元组损失来优化编码器-解码器模型
- 给定一组锚点 a、正例 p 和负例 n ,三元组损失由(4)计算
- 给定一组锚点 a、正例 p 和负例 n ,三元组损失由(4)计算
- 两条来自相同精确移动路径 R 的轨迹 τi 和 τj 应该在向量空间中他们的嵌入vi 和 vj 之间紧密相邻,而来自不同精确移动路径的两条轨迹应该在他们的嵌入远离
- 论文为计算三元组损失生成两种不同的轨迹对(a,p,n)
- 关于每个轨迹token序列
- 从中随机抽样token以获得三个子轨迹token序列 a、p 和 n ,使得 a 和 p 有更多的共同token。
- 这样选择背后的原理是,如果两个轨迹有更多的共同token,它们似乎更相似。
- 从中随机抽样token以获得三个子轨迹token序列 a、p 和 n ,使得 a 和 p 有更多的共同token。
- 关于轨迹的来源
- a 和 pi是从相同的精确移动路径派生(降采样或扭曲)的,而 ai和 ni是从两个不同的精确移动路径派生的
- 关于每个轨迹token序列
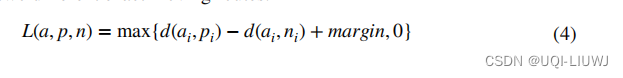
3.3.3 时间复杂度
- O(|τ|)时间将轨迹τ嵌入到表示向量v中
- O(|v|)时间来计算两个向量的欧几里得距离以进行相似性测量
- ——>总的时间复杂度是O(|τ| + |v|)
4 实验
4.1 实验数据
- 北京出租车数据集 (BJ)
- 一个星期内跟踪的10,000辆出租车的轨迹
- 平均采样间隔为177秒,距离约为623米
- 波尔图市 (PT)
- 170万条轨迹
- 每辆出租车每15秒报告一次其位置
4.2 平均rank 比较
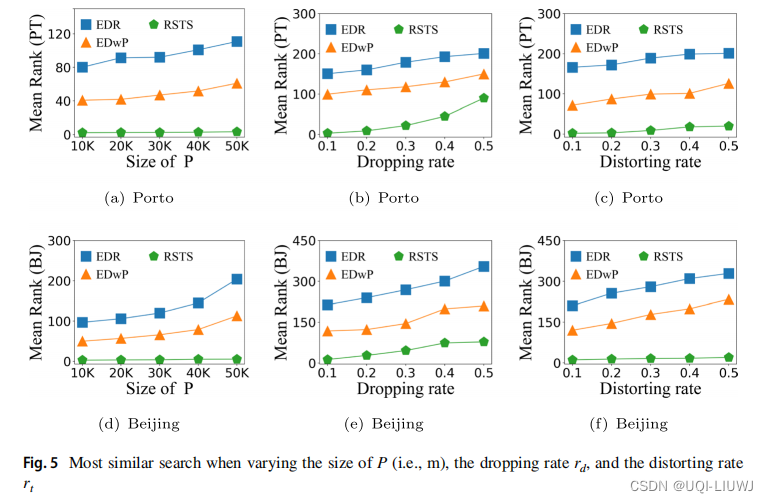
- 研究了最相似搜索的性能
- 从测试数据集中随机选择两组不同的轨迹,大小分别为100和m,分别表示为Q和P
- 通过交替地从每个轨迹τi ∈ Q中取点来创建两组子轨迹DQ和D′_Q
- 比如给定一个轨迹τ={s1,…,s10},将两个双胞胎子轨迹{s1,s3,s5,s7,s9} 和 {s2,s4,s6,s8,s10} 分别添加到DQ和D′_Q中
- 对P进行相同的操作,得到双胞胎DP和D′_P
- 接下来,对于每一个查询τa ∈ DQ,我们检索其在D′_Q ∪ D′_P中的前k个相似轨迹,并计算其双胞胎τ′a的排名
- 对于一个稳健的相似性度量,τ′a 期望被排在前面,因为它是从与τa 相同的源生成的
4.2.1 m(grid数量)的影响
- 在EDRt和EdwPt中都观察到了mean-rank的增加趋势,而RSTS中的增加趋势则不太明显,这表明RSTS模型在处理大数据集时具有更强的能力
4.2.2 丢弃率的影响
- 将丢弃率从0.1变到0.5时,所有方法的平均排名都会增加
- 与基线方法相比,RSTS始终达到了最佳性能
4.2.3 扭曲率的影响
- 将扭曲率从0.1变到0.5时,所有方法的平均排名都会增加。
- 与基线方法相比,RSTS始终达到了最佳性能
4.3 交叉相似性比较
- 一个好的相似性度量不仅应该识别出来自相同确切移动路线的轨迹变量,而且还应该保留不同轨迹之间的距离,而不考虑它们的采样策略。
- 采用交叉距离偏差作为评价标准,记为csd
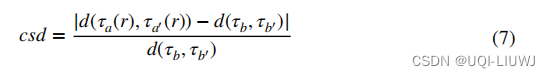
- τb 和 ′τb′ 是两个不同的原始轨迹
- τa(r)和τa′(r) 分别是τb 和τb′ 的两个变种,它们是通过下采样操作(或扭曲操作)得到的,具有一个丢失率(或扭曲率)r
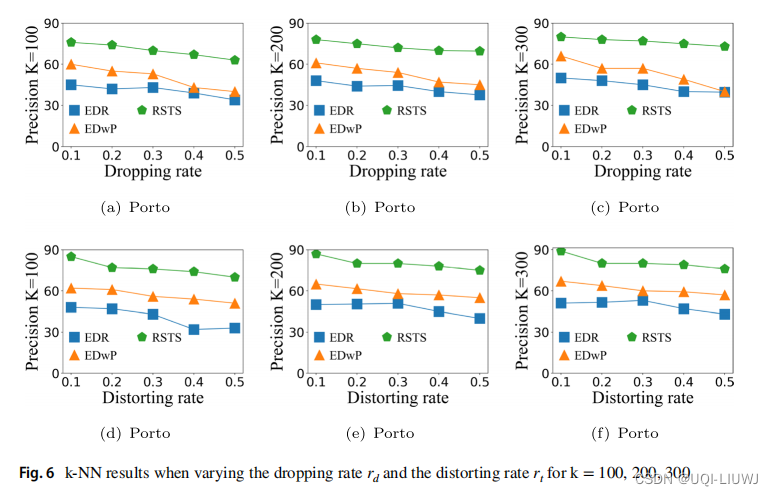
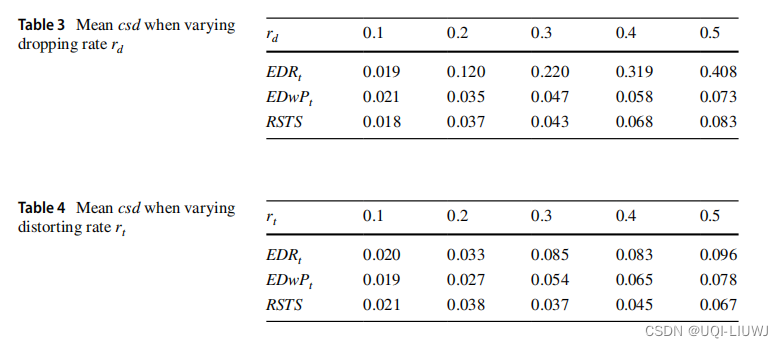 4.4 top-k相似轨迹
4.4 top-k相似轨迹
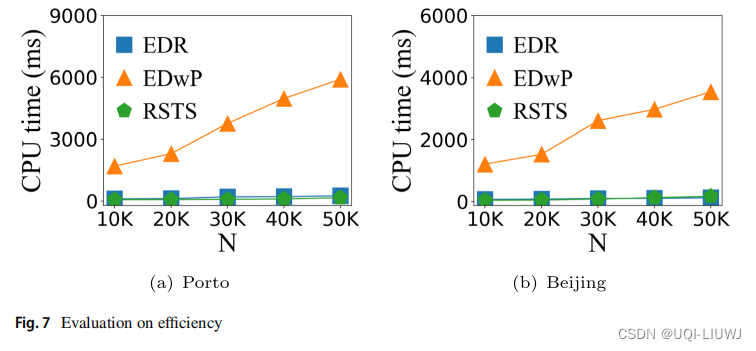
 4.5 效率
4.5 效率


















 666
666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











