







2023 AAAI
1 intro
1.1 背景
- 序列推荐:根据用户的历史交互序列预测下一个时间点用户访问的项目
- 论文发现序列中两个项目交互的时间间隔并没有得到广泛的关注,特别是考虑到兴趣偏移时。
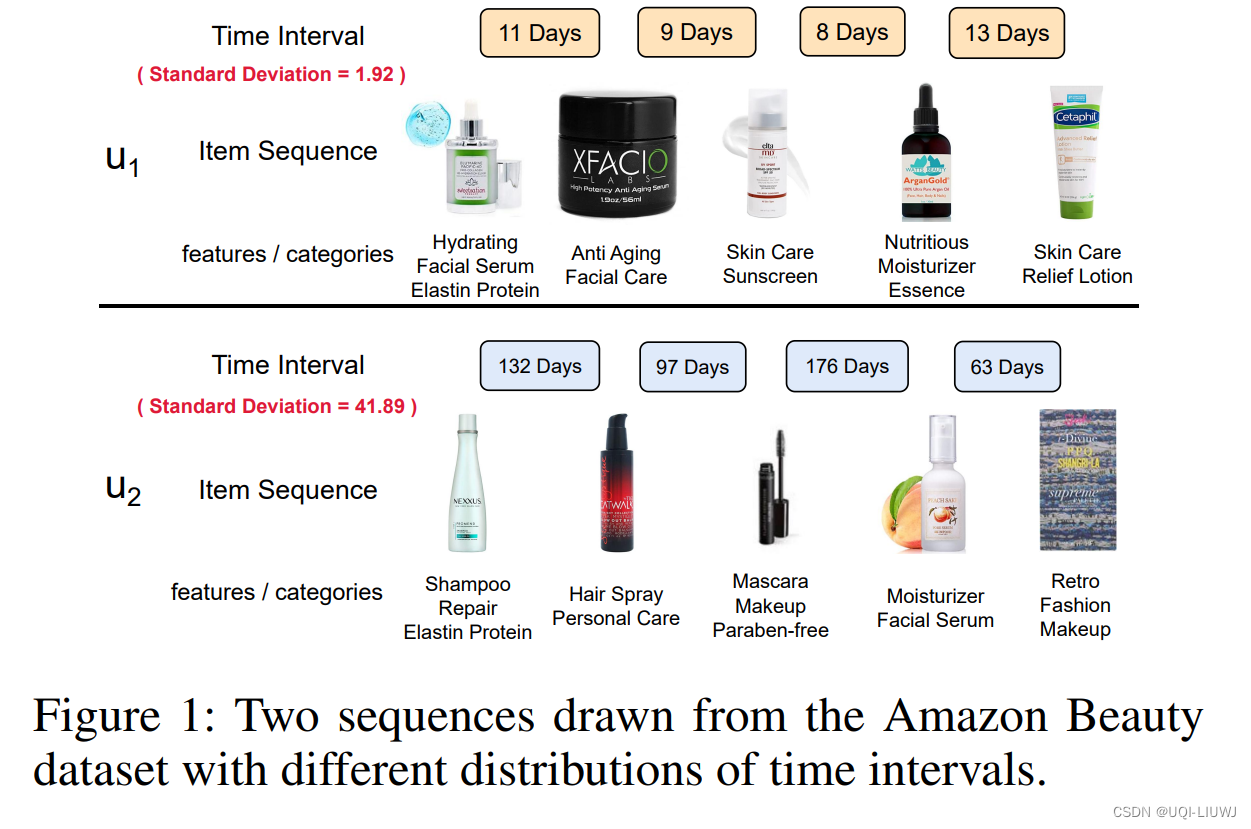
- 图1是从真实数据集中抽取的一个例子。
- 两个用户拥有相同长度的交互序列,但他们交互间隔的分布却相差很多。
- 用户1的时间间隔分布相对用户2更为均匀。
- 用户1购买的大多数产品都属于皮肤/面部护理类别,而用户2购买的产品类别却随着时间发生了较大的改变(从发胶到睫毛膏,从睫毛膏到保湿霜)。
- 由于用户1的序列比其他用户分布更均匀,因此模型可以更好地学习用户偏好。
- 作者将用户1这种序列称为“均匀序列”,用户2称为“非均匀序列”。
1.2 论文思路
- 本文进行了实证研究来进一步验证这一猜想(均匀序列比非均匀序列可以显著提高序列推荐的性能)
- 然而,真实数据集中序列在时间间隔上不能均匀分布是一个很普遍的现象。
- 基于实证研究的结果,作者提出了五个时间间隔感知的数据增强算子(Ti-Crop, Ti-Reorder, Ti-Mask, TiSubstitute, Ti-Insert)来将非均匀序列转换为均匀序列
2 实证研究
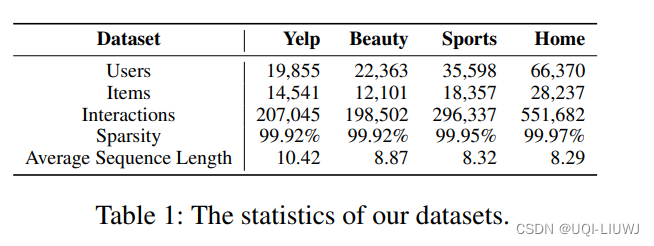
2.1 使用的数据集
2.2 均匀/非均匀序列的判断
- 论文用序列时间间隔的标准差来判定序列是否均匀。
- 如果一个序列的时间间隔的标准差较小,那么它为均匀序列,如果时间间隔的标准差较大,那么它为非均匀序列。
- 论文计算了数据集中所有序列时间间隔的标准差。
- 通过设置不同的标准差阈值来分析数据集中均匀(非均匀)序列的数量
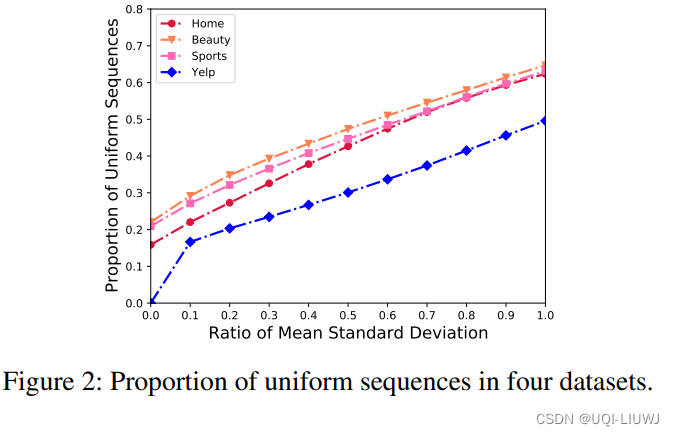
- 横轴表示门槛值。
- 门槛值是数据集中所有序列标准差的均值的比率(例如0.5表示门槛为标准差均值×0.5)
- 序列的标准差小于门槛值即为均匀序列,大于门槛值即为非均匀序列
- 纵轴表示此时均匀序列的百分比。
- 总的来说非均匀序列占据了总体数据的很大一部分(40-50%)
2.3 实验验证“均匀序列比非均匀序列可以显著提高序列推荐的性能”
- 对每个数据集的所有序列按时间间隔的标准差由小到大进行排名。采取了三种不同的划分方式。(U为均匀子集,N为非均匀子集)
- 按用户划分(S):
- 排名前50%用户一个子集(S:U),后50%一个子集(S:N)
- 两个子集用户数相同,但交互数不同
- .按交互数量划分(I)
- 排名前50%的交互一个子集(I:U),后50%一个子集(I:N)
- 两个子集交互数相同,用户数不同
- 从数据集中随机抽取50%的序列(Random)
- 按用户划分(S):
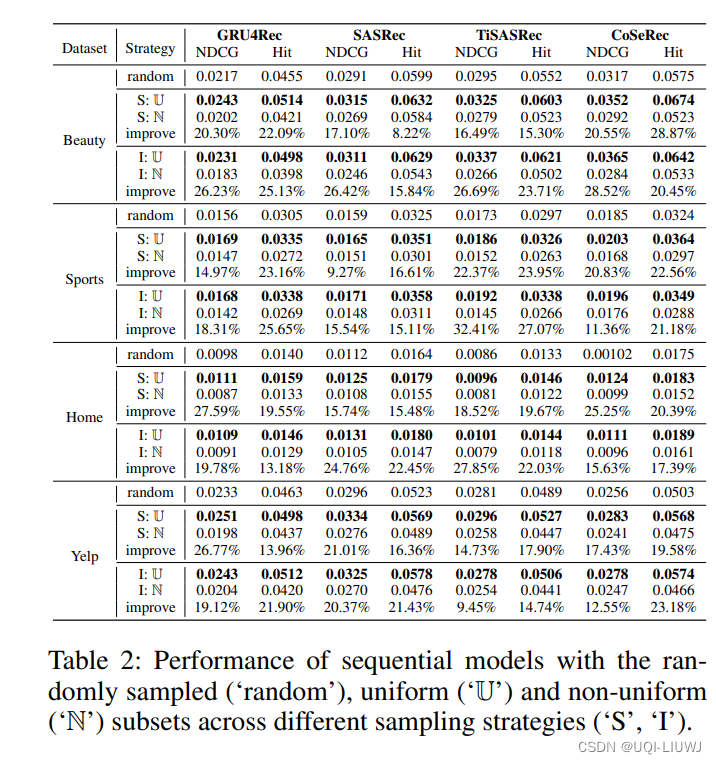
- 从结果中,可以看出模型在均匀子集上的表现普遍好于非均匀子集。且随机子集的结果在均匀子集与非均匀子集中间,即非均匀<随机<均匀
3 论文方法(和传统的增强方法的对比)
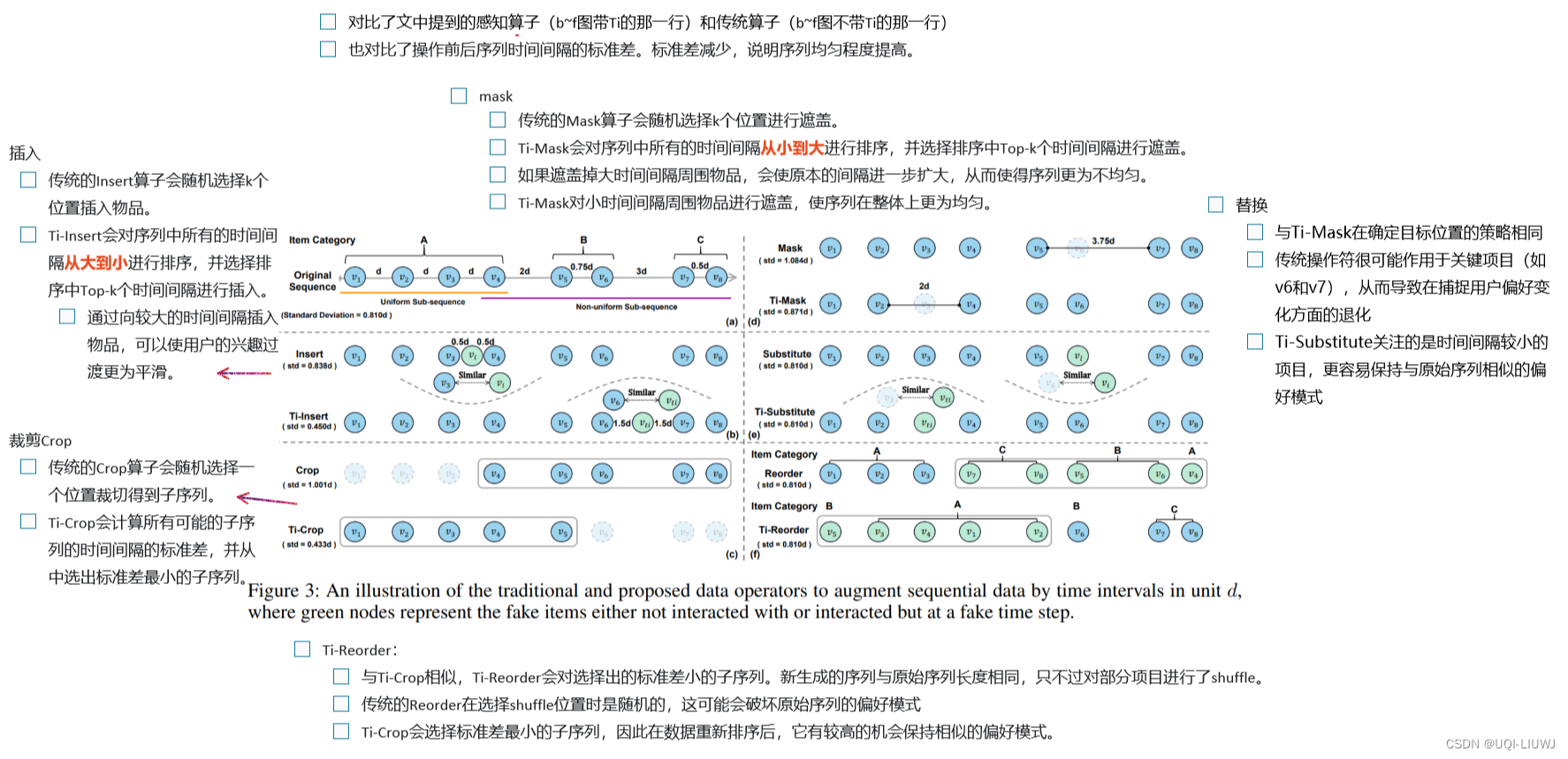
- 因为短序列对于裁切和遮盖更为敏感,所以参考CoSeRec,论文对不同长度的序列应用不同的数据增强算子
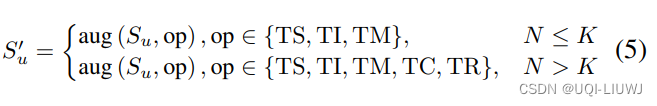
- N为序列长度,K为区分长短序列的阈值。Su为算子集。
- 每次数据增强时会从算子集中随机抽取两个进行数据增强,生成两个增强序列用于对比学习。
- 短序列不使用裁剪和重新排序
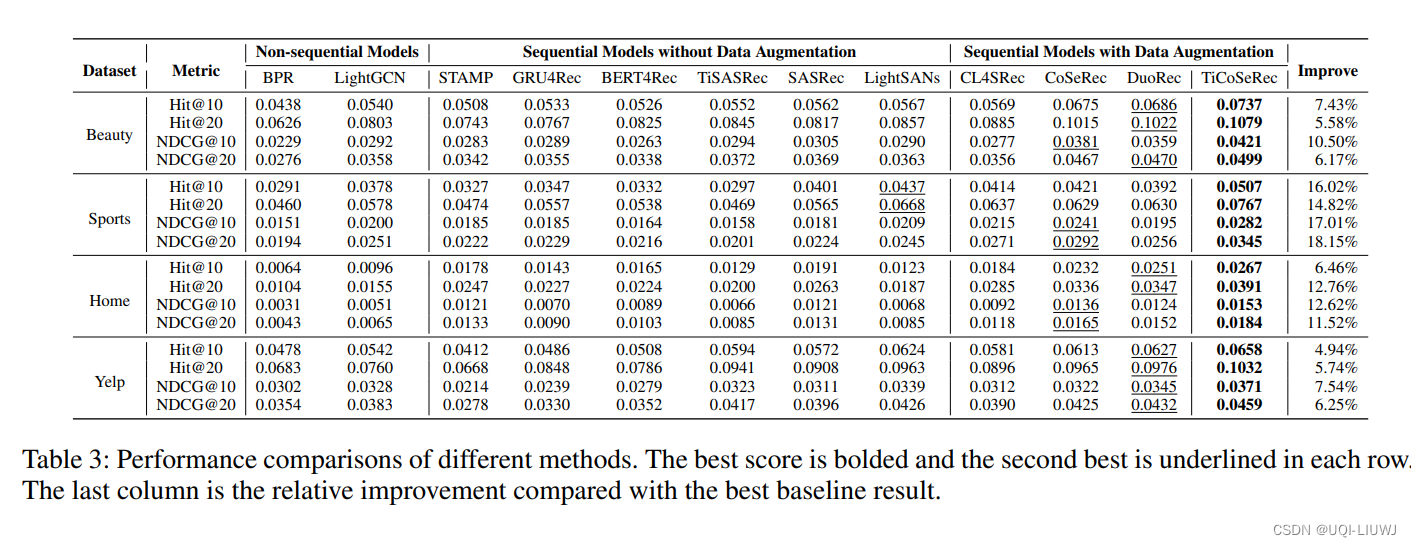
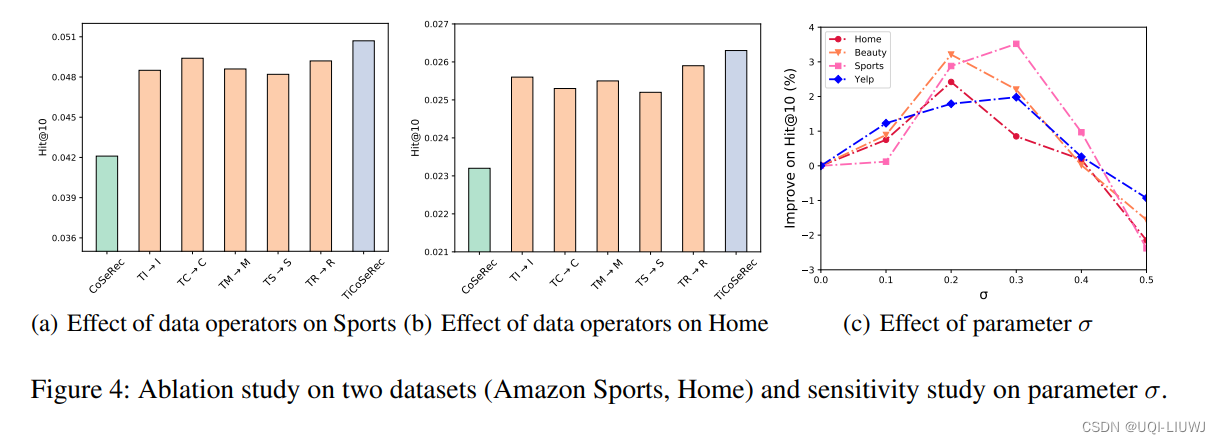
4 实验结果
















 2029
2029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











