




2024 KDD
1 intro
- GPS 技术的普及彻底改变了我们对人类移动模式的理解,在城市规划、基于位置的服务等多个领域产生了深远影响
- 然而,获取真实世界的 GPS 轨迹数据往往面临诸多严峻挑战,包括隐私问题 、数据收集成本 、专有权限制以及众多监管障碍
- 在此背景下,轨迹生成成为一个极具吸引力的解决方案,它提供了一种合成却逼真的 GPS 轨迹方式,从而绕过上述限制
- 通过生成合成轨迹,该方法不仅能够在没有真实数据集的情况下推进研究,还能满足严格的隐私保护和数据所有权要求,进而拓展诸多领域的研究与应用
- 为了生成能够真实反映现实复杂场景的轨迹,研究者们探索了多种策略
- 早期的方法依赖于基于规则或统计模型的方式,尽管具备一定的可解释性,但在模拟人类移动的随机行为方面表现不足
- 随着生成对抗网络(GAN)和变分自编码器(VAE)等机器学习方法的发展,研究者能够更复杂地建模轨迹分布。
- 然而,这些方法通常会将轨迹转换为简化的数据格式,如网格或图像,从而损害了数据的保真度和细粒度
- 此外,这些技术主要聚焦于群体移动的模拟,缺乏在 GPS 数据粒度上精细复现个体路径的能力
- 近年来,研究者尝试利用扩散模型的生成能力以实现更高分辨率的轨迹生成
- 尽管这种方法具有潜力,但仍无法根据道路网络控制生成轨迹的路径,或在不重新训练的情况下将模型应用于新城市
- 当前的研究仍存在两个显著空白:
- 一是难以生成高分辨率轨迹
- 二是缺乏对轨迹生成过程的道路网络控制能力
- 一个理想的轨迹生成解决方案应满足以下几点需求:
- 高保真度:模型应能生成具有细粒度、保持原始时空属性的轨迹;
- 灵活性:框架应具有适应性,使用户能够引导生成特定的移动模式,或遵守特定条件(如道路网络结构约束或不同时间段的出行特性)
- 泛化能力:模型应能超越训练数据的地理上下文,实现对新环境的通用适配,从而在未直接见过的条件下也能生成真实有效的轨迹。
- ——>提出了一种结合拓扑约束扩散模型的可控轨迹生成框架(ControlTraj)
- 通过融合道路网络信息,能够在用户引导下忠实遵循拓扑结构,生成更高分辨率的轨迹
- 此外,该模型展现出卓越的适应性与泛化能力,能够无需重新训练便迁移到新城市应用
2 preliminary
2.1 问题定义


2.2条件扩散概率模型(Conditional Diffusion Probabilistic Model)

2.2.1 前向过程

2.2.2 反向过程


2.3 生成阶段


3 方法
3.1 提取拓扑约束(Extracting Topology Constraint)
- 在构建可控轨迹生成框架时,提取条件引导信息 是关键的前置步骤。
- 对于基于扩散模型的计算机视觉(CV)或自然语言处理(NLP)任务而言,这一环节通常可通过预训练编码器(如 BERT 或 CLIP )轻松实现
- 然而,在轨迹生成任务中,由于带标注的道路网络数据稀缺以及地理结构的复杂性(例如道路不规则性与多样的拓扑形状),这一任务面临独特挑战。
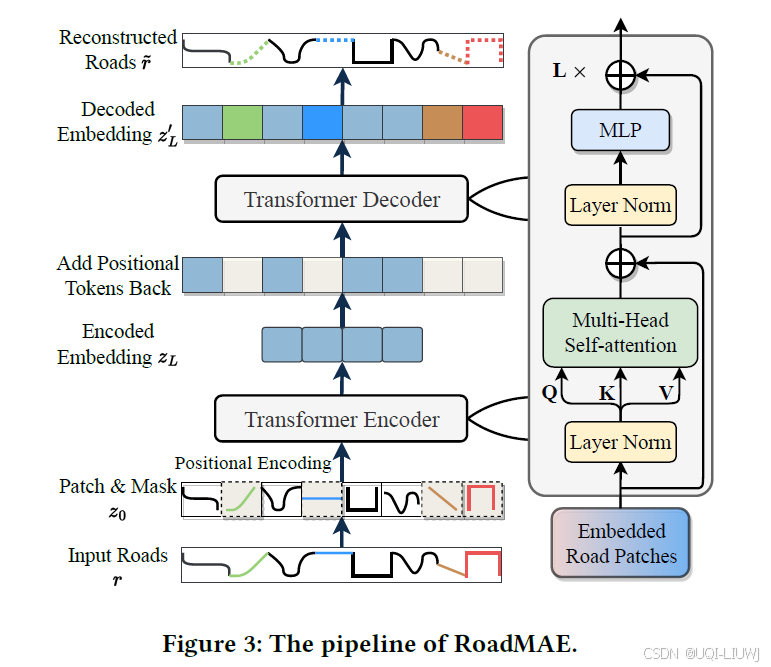
- ——>论文设计了一个 掩码式道路自编码器(Masked Road Autoencoder, RoadMAE),该模型采用自监督学习方式进行高效训练,并能捕捉道路网络的关键特征。
-
所提出的 RoadMAE 结构包括:
-
一个处理带有位置编码的道路片段的 Transformer 编码器;
-
一个用于重建道路片段的 Transformer 解码器。
-
-
3.1.1 道路片段的切分与掩码(Road Segments Patching and Masking)


3.1.2 基于 Transformer 的自编码器


3.2 GeoUNet 架构(GeoUNet Architecture)



3.3 可控轨迹生成(Control Trajectory Generation)

4 实验
4.1 实验设置
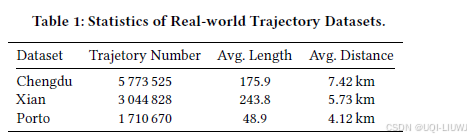
4.1.1 数据集
- 在三个真实世界的 GPS 轨迹数据集上开展实验,分别来自 成都、⻄安与波尔图(Porto)
4.1.2 评估指标
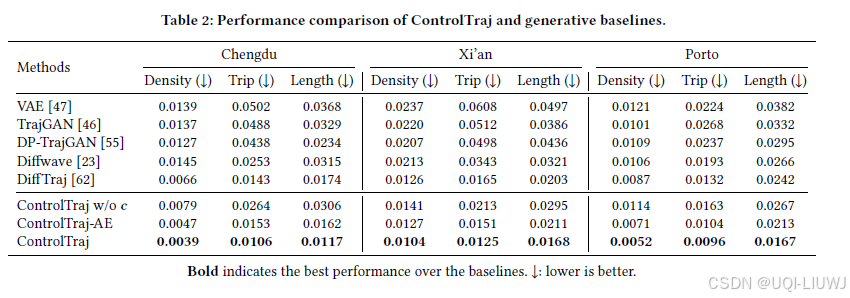
- 使用以下三个指标从定量上评估生成轨迹的保真度:
-
Density Error(密度误差)
-
Travel Error(出行误差)
-
Length Error(长度误差)
-
- 由于 ControlTraj 具备修改轨迹模式的能力,直接比较轨迹模式相似性并不适用
- 因此,论文计算了生成轨迹与真实轨迹分布之间的 Jensen-Shannon 散度(JSD),并在 10 次独立运行中取平均以提高可靠性
4.2 整体性能
4.2.1 定量分析
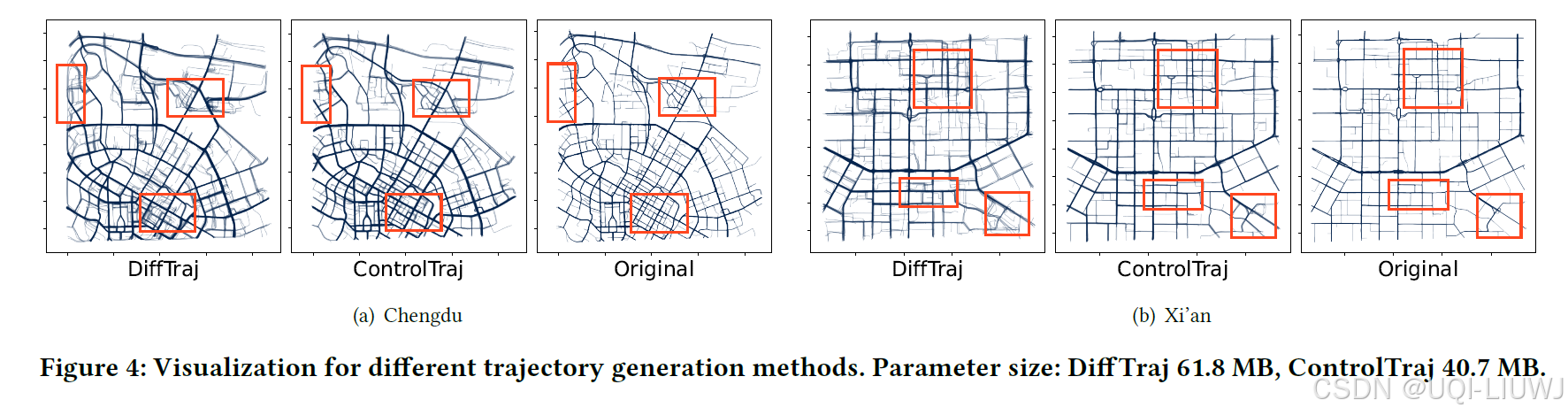
4.2.2 可视化分析
4.3 生成轨迹分析
从三个方面展开分析:
-
首先,展示生成轨迹与真实轨迹在一天内的分布热力图;
-
接着,展示原始与生成轨迹在出行量与平均速度随时间变化方面的对比图;
-
最后,通过交通流量预测任务验证生成数据的实际效用。
4.3.1 热力图与雷达图分析
展示了一天内不同时段的人类活动模式。
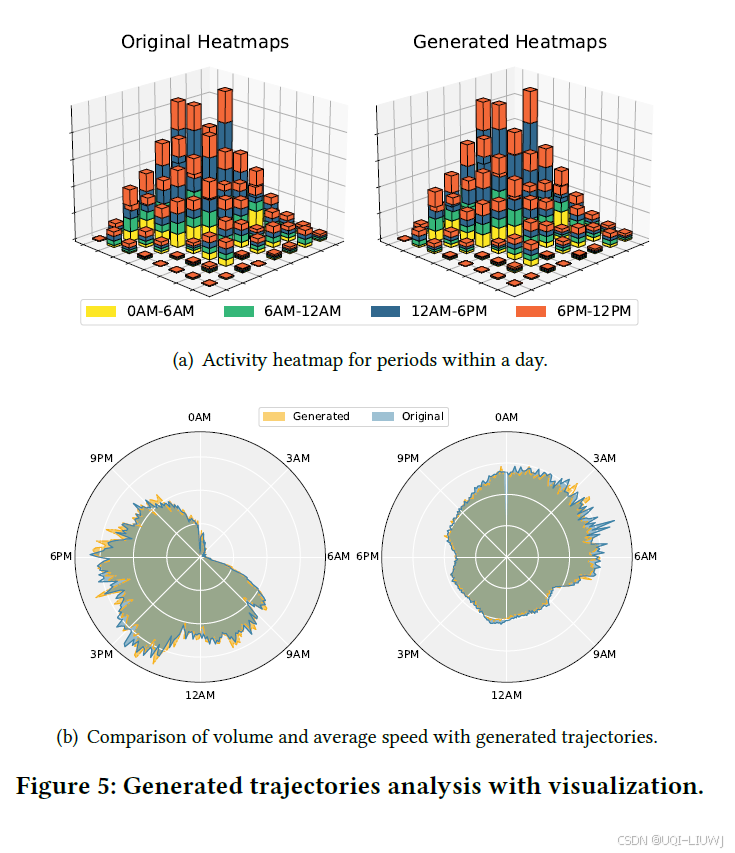
在时间与空间分布层面,生成轨迹与原始轨迹高度一致,说明生成模型成功捕捉了人类活动的动态特征。
4.3.2 交通流预测任务中的数据实用性评估
- 进一步通过一个经典的交通流量预测任务,验证 ControlTraj 生成数据的实际应用价值
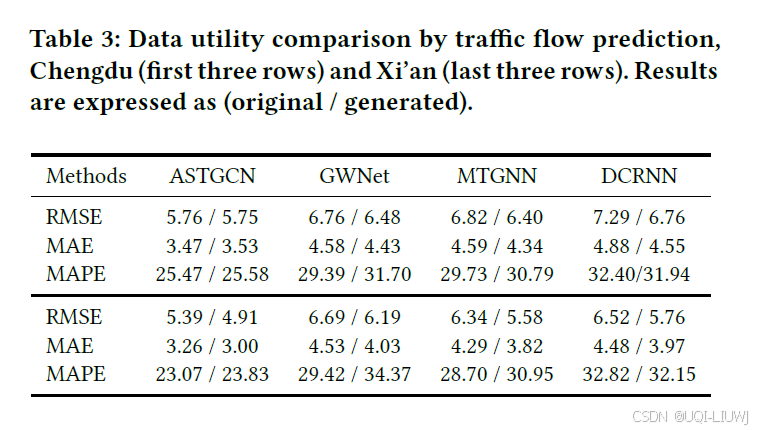
实验结果表明:
-
三项评估指标在原始数据与生成数据之间的差距非常小;
-
特别是 ASTGCN 模型在两种数据下的表现几乎一致;
-
各模型在不同指标上的性能差异比例保持在可接受的范围内。


















 1815
1815



 到【灌水乐园】发言
到【灌水乐园】发言










