







 本文提出 InstructGLM,旨在用自然语言指令调优大语言模型处理图机器学习问题。它具有灵活性、可扩展性和兼容性,能解决图节点分类任务,并通过自监督链接预测增强性能。实验表明,InstructGLM 在多个数据集上超越了竞争性 GNN 基线和基于 Transformer 的方法。
本文提出 InstructGLM,旨在用自然语言指令调优大语言模型处理图机器学习问题。它具有灵活性、可扩展性和兼容性,能解决图节点分类任务,并通过自监督链接预测增强性能。实验表明,InstructGLM 在多个数据集上超越了竞争性 GNN 基线和基于 Transformer 的方法。
目录
4.4 Instruction Tuning at Low Label Ratio
论文链接:https://arxiv.org/pdf/2308.07134.pdf
摘要
ChatGPT 等大规模预训练语言模型的出现,彻底改变了人工智能的各个研究领域。基于 Transformer 的大语言模型 (LLM) 已逐渐取代 CNN 和 RNN,以统一计算机视觉和自然语言处理领域。与图像、视频或文本等相对独立存在的数据相比,图是一种包含丰富的结构和关系信息的数据。同时,自然语言作为最具表现力的媒介之一,擅长描述复杂的结构。
然而,现有的将图学习问题纳入生成语言建模框架的工作仍然非常有限。随着大型语言模型的重要性不断增长,探索 LLM 是否也可以取代 GNN 作为图的基础模型变得至关重要。
在本文中,我们提出InstructGLM(Instruction-finetuned Graph Language Model),系统地设计基于自然语言指令的高度可扩展的提示,并使用自然语言描述图的几何结构和节点特征,以便指令调优LLM来执行学习以及以生成方式对图进行推理。我们的方法超越了 ogbn-arxiv、Cora 和 PubMed 数据集上的所有竞争性 GNN 基线,这证明了我们方法的有效性,并揭示了生成大语言模型作为图机器学习的基础模型。
Introduction
在 Transformers [1] 出现之前,具有不同归纳偏差的各种人工智能领域具有不同的基础模型架构。例如,CNN [2, 3] 的设计考虑了图像的空间不变性,从而在计算机视觉任务中具有卓越的性能 [4, 5]。 RNN [6] 和 LSTM [7, 8] 等记忆增强模型被广泛用于处理自然语言 [9] 和音频 [10] 等序列数据。图神经网络(GNN)擅长通过消息传递和聚合机制捕获拓扑信息,使其长期以来成为图学习领域的首选[11-13]。近年来,人工智能社区见证了众多强大的预训练大型语言模型(LLM)的出现[14-18],它们正在推动巨大的进步并导致对可能的通用人工智能(AGI)的追求[19] 。在此背景下,不同领域的模型架构出现了统一的趋势。具体来说,预训练的 Transformer 在各种模式上都表现出了卓越的性能,例如计算机视觉中的图像 [20] 和视频 [21]、自然语言处理中的文本 [22]、图机器学习中的结构化数据 [23]、决策序列在强化学习中[24],以及多模态任务中的视觉文本对[25]。甚至有能够处理 12 种模式的 Transformer [26]。
除了模型架构之外,处理多模态数据的处理方法的统一也是一个值得关注的重要趋势。 T5[15]建立了文本到文本框架,统一了所有NLP任务作为序列生成问题。此外,像 CLIP [25] 这样的模型利用图像-文本对来完成多模态任务,并使用自然语言描述的图像。至于强化学习,Di Palo 等人。 [24]采用自然语言来描述智能体的环境状态,成功解决了许多强化学习(RL)问题。 P5 [27] 通过prompt将所有个性化推荐任务重新表述为语言建模任务,进一步推动了这一趋势。上述工作共同表明,利用自然语言进行多模态信息表示已成为一个突出且有前途的趋势。
然而,在图机器学习领域,利用自然语言处理图相关任务的探索仍然有限。利用大型语言模型处理图任务的现有方法可大致分为两类: 1) 结合 LLM 和 GNN,其中 LLM 充当特征提取器或数据增强模块,以提高下游 GNN 的性能 [28 -30 ]。这类方法通常需要训练多个模型,因此会产生巨大的计算开销。此外,由于 GNN 仍负责学习图的结构信息,它们往往会继承 GNN 的缺点,如容易过度平滑 [31]。2) 仅依赖transformer,但需要对节点和边进行新颖的标记嵌入设计 [32] 或创建复杂的图注意模块来学习结构信息 [33 , 34]。这类方法要求在每个优化步骤中对每个节点进行局部注意力计算,从而导致相当大的计算成本,并因此将每个节点的范围限制在只有 1 跳邻居的范围内。同时,复杂管道通过特殊的注意力机制或token表示来传递结构信息,这使得模型无法像 GNN 那样直接观察和学习结构信息,从而限制了性能的进一步提高。
为了解决基于 LLM 的图学习器中存在的问题并弥合基于自然语言的图学习的差距,我们提出了 InstructGLM(指令微调图语言模型)。鉴于 LLM 在许多 AI 领域占据主导地位,我们的目标是回答这样一个问题:LLM 是否也可以取代 GNN 作为图机器学习的基础模型?直观上,作为最具表现力的媒介之一,自然语言擅长描述复杂的结构,因此 InstructGLM 相对于 GNN 具有以下优势:
1) 灵活性。自然语言句子能够有效描述任何所需的跳数级别和中间路径的连接性,而无需信息传递和聚合。甚至节点和边的多模态特征也可以直接整合到自然语言prompt中,这使得自然语言成为一种非常灵活的媒介,既能传递图的结构信息,也能传递图的内容信息。
2) 可扩展性。在多个自然语言句子中注入图结构可实现小批量训练和独立梯度传播,从而进一步方便地扩展到海量图上的分布式训练和推理,同时降低机器通信开销。
3) 兼容性。在结构描述的辅助下,InstructGLM 可以将各种图学习流水线一致地重新表述为语言建模任务,从而很好地融入基于 LLM 的多模态处理框架,为将图学习与视觉、语言和推荐等其他人工智能任务集成以构建统一的人工智能系统铺平了道路。
在本文中,我们专注于解决图节点分类任务,同时通过自监督链接预测对其进行增强以提高性能。受到 GNN 中各种消息传递管道的启发 [35, 36],我们设计了一系列可扩展的图prompt,用于在生成 LLM 上进行指令调整 [37, 38]。具体来说,在确定中心节点并进行邻居采样后,我们根据prompt系统地使用自然语言来描述图的拓扑。通过这样做,可以清晰直观地向LLM提供图结构,而无需针对图定制复杂的流程。因此,我们可以通过普通的 Transformer 架构 [1] 和语言建模目标 [39] 以生成的方式高效、简洁地处理图形任务。此外,我们的方法确保了图学习、NLP 以及多模态处理之间的高度兼容性,从而在各个领域的多任务学习中表现出高可扩展性。总的来说,我们的贡献可以概括为以下四点
据我们所知,我们是第一个提出纯粹使用自然语言进行图结构表示,并对生成式 LLM 进行指令调整来解决图相关问题的人。我们消除了设计特定的复杂注意力机制或为图量身定制的分词器的要求。相反,我们为图机器学习提供了一个简洁高效的自然语言处理接口,它对统一的多模式和多任务框架表现出高可扩展性,符合其他人工智能领域的当前趋势。
• 受GNN 中各种消息传递机制的启发,我们为通用图结构表示和图机器学习设计了一系列基于规则、高度可扩展的指令prompt。尽管在本文中,我们的重点在于探索大型语言模型的指令调优,但这些提示也可以用于LLM的零样本实验。
• 除了节点分类之外,我们还进行自监督链接预测作为辅助任务,并在多任务指令调优框架下进一步研究其对主要任务的影响。这一探索为未来基于LLM的多任务图学习提供了宝贵的见解,证明了自监督链接预测对于大型语言模型更好地理解图结构的重要性。
• 我们对三个广泛使用的数据集进行了广泛的实验:ogbn-arxiv、Cora 和 PubMed。结果表明,我们的 InstructGLM 在所有三个数据集上均优于之前的竞争性 GNN 基线和基于 Transformer 的方法,实现了顶级性能。这些发现验证了我们提出的方法的有效性,并强调了利用生成式大语言模型作为图机器学习的基础模型的趋势。
Related Work
基于 GNN 的方法
图神经网络(GNN)[40, 41] 长期以来在图机器学习领域占据主导地位。利用消息传递和聚合机制,GNN 擅长同时学习节点特征、边缘特征和拓扑结构信息。总的来说,GNN 可以分为基于空间的 GNN [12、13、42、43] 和基于频谱的 GNN [11、44、45],具有各种消息传递机制。为了解决一些固有问题,例如过度平滑[31],研究人员提出了一些方法,例如将中间层特征合并到最终表示中[36],对从不同跳级别提取的多个子图进行卷积[35],以及将边缘丢弃到防止过度拟合[46]。 GNN 的一个主要缺点是它们无法直接处理来自各种模式的原始数据,需要大量的特征工程作为预处理步骤。 GNN 无法直接处理文本或图像等非数字信息。为了解决这个问题,现有的工作使用 BoW、TF-IDF 或 Skip-gram 等技术来构造浅嵌入作为 GNN 的输入[47]。它与现有的大规模生成模型缺乏兼容性,这对于与视觉和语言等其他人工智能领域集成到统一的智能系统中提出了重大挑战。
基于 Transformer 的方法
基于注意力的 Transformer 模型还可以通过将图中的每个节点和边表示为不同的token来用于图处理[48]。然而,这种简单的方法提出了两个挑战:首先,处理大规模图时计算量很大。其次,具有基本注意力机制的全局加权平均计算无法有效捕获和学习图的拓扑结构[32]。为了克服这些问题,人们提出了各种方法来改进 Transformer 结构或图形表示方法。一些方法将图结构信息合并到注意力矩阵[23]或系数[49]中,而其他方法将注意力限制在局部子图[34]或巧妙地为节点和边缘标记设计正交向量以编码结构细节[32]。这些增强通常涉及复杂的注意力机制或数据转换,使得图结构的直接表示具有挑战性,并显着增加了模型训练的难度。唯一与我们相似的工作是Zhang等人。 [50],它利用专门制定的仅编码器模型和自然语言模板来解决生物学概念链接问题[51, 52]。然而,与我们的方法不同,它不是为一般图学习而设计的,并且由于使用仅编码器模型而难以扩展到分类任务之外[53]。此外,它的自然语言模板是为生物概念链接领域量身定制的,因此不如我们的方法那么富有表现力和灵活性
Fuse GNN 和 Transformers
GNN 擅长学习结构信息,而 Transformers 擅长捕获多模态特征。许多作品将 GNN 和 Transformer 结合起来,以有效地解决与图相关的任务。例如,Chien 等人 [54]利用多标签邻居预测任务将结构信息合并到语言模型中,生成名为 GIANT 的增强特征,以提高下游 GNN 的性能。马夫罗马蒂斯等人 [29] 使用 GNN 对语言模型进行知识蒸馏,Zhao 等人 [30] 在变分推理框架中迭代训练 GNN 和语言模型,Rong 等人 [55]尝试用 GNN 取代 Transformers 中的注意力头,以更好地捕获全局信息。上述方法的主要缺点是 Transformer 模型和 GNN 之间缺乏解耦,需要训练多个模型,并且很容易产生大量的计算开销 [34]。此外,模型性能仍然容易受到 GNN 固有问题的影响,例如过度平滑[56]。此外,与单个生成式 LLM 框架的简单性相比,训练多个模型的流程通常非常复杂。
基于大语言模型(LLM)的方法
受LLM在各个AI领域卓越的零样本能力的启发,利用LLM解决图问题引起了研究人员的广泛关注。现有的工作已经包括利用LLM根据查询自动选择最合适的图处理器[57],利用LLM的零样本预测和数据增强的相应解释来获得最先进的TAPE图特征嵌入[28] ],生成提示来解决图构建问题[58]、结构推理任务[59]和分子属性预测任务[60]。此外,基于LLM的新图问题数据集和基准已经被收集和发布[61]。有三项工作与我们的方法有相似之处。郭等人 [61]尝试通过描述图来完成图任务。然而,它不像我们的prompt那样使用自然语言。相反,它使用复杂的形式语言,如 Brandes 等人[62]和希姆索尔特[63]王等人 [64]和陈等人。[65]都探索使用自然语言与LLM来解决图问题,[64]更多地关注小图上的数学问题,而[65]则专注于文本属性图(TAG)中的节点分类[66]。与王等人相比 [64]和陈等人[65],我们设计的自然语言指令prompt表现出更好的规律性和可扩展性,适用于小型和大型图,并且不限于特定类型的图数据。相比之下,上述作品中的某些自然语言模板是由LLM针对特定任务指令生成的,还通过思想链(CoT)等高级提示技术进行了增强[67]。总体而言,这三篇相关工作仅探讨了在零样本设置下利用 LLM 进行图任务的基本能力。由于它们不采用指令调优 [37],因此它们的性能在大多数情况下都不会超过 GNN 基线,仅展示了 LLM 作为图形任务选项的潜力。相比之下,我们的工作通过简单的提示对生成式 LLM 进行指令调整,成功地弥补了这一差距,取得了超越竞争性 GNN 基线的实验结果。
3 InstructGLM
在本节中,我们将详细介绍我们提出的指令微调图语言模型,即 InstructGLM,一个利用自然语言将图结构和节点特征描述为生成大语言模型的框架,并通过指令进一步解决与图相关的问题调整。我们从符号设置开始,然后介绍指令提示及其设计原理,然后更详细地解释所提出的管道。
3.1 Preliminary
形式上,图可以表示为 G = (V, A, E, {Nv }v∈V , {Ee}e∈E ),其中 V 是节点的集合,E 是边的集合,A ∈ { 0, 1}|V|×|V|是邻接矩阵,Nv 是 v ∈ V 的节点特征,Ee 是 e ∈ E 的边特征。值得注意的是,节点特征和边特征可以是多种形式的各种模态。例如,节点特征可以是引文网络或社交网络中的文本信息、摄影图中的视觉图像、客户系统中的用户配置文件,甚至电影网络中的视频或音频信号,而边缘特征可以是用户-项目交互中的产品评论推荐系统图。
3.2 Instruction Prompt Design
为了全面传达图的结构信息,保证创建的指令提示对各类图的适应性,我们系统地设计了一套以中心节点为中心的图描述提示。这些提示可以根据以下三个问题来区分: i) 提示中中心节点的邻居信息的最大跳数是多少? ii) 提示是否包含节点特征或边特征? iii) 对于中心节点具有大(≥ 2)跳级邻居的提示,提示是否包含有关中间节点或沿相应连接路由的路径的信息?
关于第一个问题,提示可以分为两种类型:仅包含 1 跳连接信息的prompt和最多包含 2 跳或 3 跳连接详细信息的prompt。先前的研究表明,利用最多 3 跳连接足以获得出色的性能 [11-13],而超过 3 跳的信息通常对改进影响较小,甚至可能导致负面影响 [31, 68]。因此,prompt中包含的邻居信息的最大级别为三级。然而,受益于自然语言的灵活性,我们设计的prompt实际上可以容纳任何跃点级别的结构信息。对于后两个问题,每个问题有两种可能的情况,即是否在prompt中包含节点或边特征,以及是否在prompt中包含连接路线信息。
然后,我们将指令prompt表示为 T (·),使得 ![]() 是 LLM 的输入句子,v 是该提示的中心节点及其相应的用自然语言描述的图结构。例如,包含最多 2 跳邻居详细信息的图描述的最简单形式是:
是 LLM 的输入句子,v 是该提示的中心节点及其相应的用自然语言描述的图结构。例如,包含最多 2 跳邻居详细信息的图描述的最简单形式是:
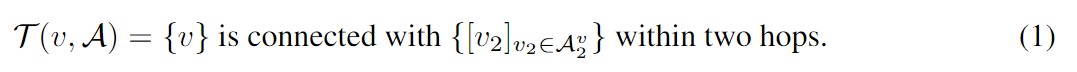
而其最详细的形式应包括节点特征、边缘特征和相应的不同路径:
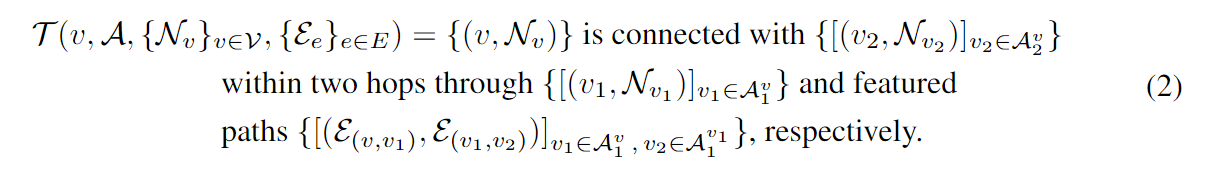
其中 表示节点 v 的 k 跳邻居节点列表。本质上,上面的prompt包含具有节点和边缘特征的所有 2 跳路径,例如
![]() 以节点v为中心。我们设计的所有指令提示都总结在附录中.
以节点v为中心。我们设计的所有指令提示都总结在附录中.
3.3 节点分类的生成指令调整
在prompt工程[69 - 71]或上下文学习[72]中,预先训练的模型通常是冻结的,这阻碍了它们在下游任务中实现最佳性能。然而,指令调整 [ 37, 38]在多prompt训练的框架下,通过将原始输入数据与特定于任务的指令prompt融合,将下游任务的要求直接传达给预训练模型。这有助于非常有效的微调,尤其是与人类反馈相结合时[18]。指令调优已经成为微调最强大的大型语言模型不可或缺的技术。
在本文中,我们介绍 InstructGLM 作为图学习的多prompt指令调优框架。具体来说,我们采用以编码器-解码器或仅解码器架构作为主干的生成性大型语言模型,然后融合我们设计的所有指令prompt,这些指令prompt跨越不同的跳跃级别,具有不同的结构信息,一起作为LLM的输入,实现指令之间的相互增强。通过专门使用自然语言来描述图结构,我们向LLM简洁地呈现图的几何形状,并为所有与图相关的任务提供纯NLP接口,使它们可以通过统一的管道以生成方式解决。值得注意的是,本研究中我们专注于解决节点分类任务。我们训练 InstructGLM 严格生成自然语言的类别标签,并选择语言建模中流行的负对数似然(即 NLL)损失作为我们的目标函数.
形式上,给定图![]() 和特定的指令提示 T ∈ {T (·)},我们将 x 和 y 表示为 LLM 的输入,和目标句。那么我们的管道可以形成为:
和特定的指令提示 T ∈ {T (·)},我们将 x 和 y 表示为 LLM 的输入,和目标句。那么我们的管道可以形成为:
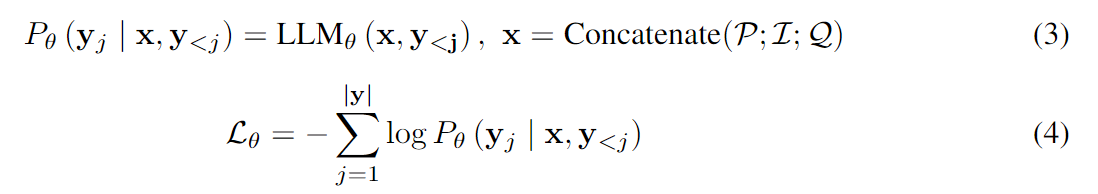
其中 L 表示 NLL 损失,![]() 是以节点 v ∈ V 为中心的图结构描述,P 和 Q 是任务特定指令前缀和查询。具体来说,对于节点分类,我们设计节点分类的 P 和 Q 如下: P = ‘将中心节点分为以下类别:[<所有类别>]。注意节点之间的多跳链接关系。”和Q =“{v}应该属于哪一类?”。管道的更多细节如图 2 所示。
是以节点 v ∈ V 为中心的图结构描述,P 和 Q 是任务特定指令前缀和查询。具体来说,对于节点分类,我们设计节点分类的 P 和 Q 如下: P = ‘将中心节点分为以下类别:[<所有类别>]。注意节点之间的多跳链接关系。”和Q =“{v}应该属于哪一类?”。管道的更多细节如图 2 所示。
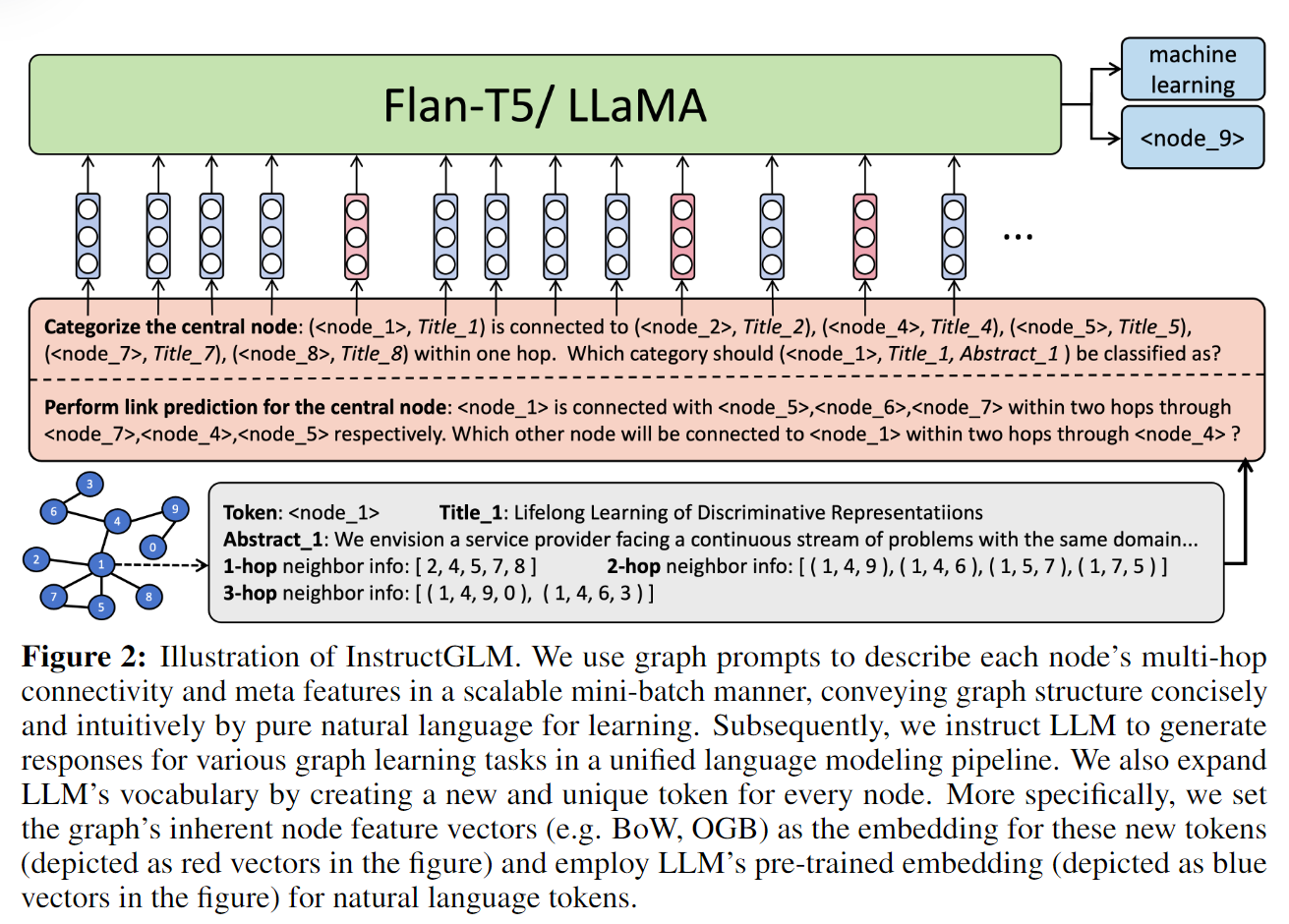
(图 2:InstructGLM 图示。我们使用图prompt以可扩展的小批量方式描述每个节点的多跳连接和元特征,通过纯自然语言简洁直观地传达图结构以供学习。随后,我们指示 LLM 在统一的语言建模管道中生成各种图学习任务的响应。我们还通过为每个节点创建一个新的、独特的代币来扩展 LLM 的词汇量。更具体地说,我们将图的固有节点特征向量(例如 BoW、OGB)设置为这些新标记的嵌入(如图中的红色向量所示),并采用 LLM 的预训练嵌入(如图中的蓝色向量所示)自然语言标记。)
我们的 InstructGLM 在机制上与各种 GNN 有本质的相似之处,因此也涵盖了它们的优点。首先,我们在训练过程中将具有不同跳级信息的prompt信息混合在一起,这与 MixHop [ 35 ] 在不同跳级提取的子图上进行图卷积的做法类似。其次,跳跃知识(Jumping Knowledge)[36] 通过跳跃连接将来自不同卷积层的结果结合在一起,这与我们以中间信息和高跳级邻居为特征的prompt相一致。此外,由于 LLM 的输入长度限制,我们与 GraphSAGE [ 13 ]类似,在填写prompt时对中心节点进行邻居采样,以形成迷你批量训练。这一操作也类似于防止过度平滑的图正则化技术,如 DropEdge [46] [73]。
此外,与 GNN 相比,我们的 InstructGLM 表现出更强的表达能力。在我们的方法中,即使是包含中间路径和 k 跳邻居信息的单个图描述,在表达能力上也相当于 k 层 GNN。因此,InstructGLM 可以轻松适应图任务的归纳偏差,而无需对 LLM 的架构和流程进行任何更改。例如,由于我们的输入是直接展示相应多跳邻居的集中图描述,因此应用于此类输入的自注意力 [1] 可以被视为 GAT 的高级加权平均聚合机制 [12, 74],从而促进 InstructGLM有效掌握不同邻居对中心节点的不同重要性。
3.4 辅助自监督链路预测
SuperGAT[75]和DiffPool[76]都引入了辅助链接预测任务,从而成功地获得了更好的节点表示和节点或图分类的性能,表明这种辅助任务可以显着增强模型对图结构的理解。受它们的启发,也为了消除我们的指令prompt只能将标记训练节点视为单任务半监督学习中的中心节点的限制,我们引入自监督链接预测作为 InstructGLM 的基础辅助任务。给定任意跳跃级别,对于图中的每个节点,我们可以随机选择该跳跃级别的邻居或非邻居作为其候选者。然后,我们prompt我们的模型要么判别中心节点和候选节点之间的该跳级别是否存在连接(判别提示),要么以生成方式直接生成正确的邻居(生成提示)。
更正式地说,给定图 ![]() ,链路预测的管道与上述方程 3 和 4 完全一致。唯一的区别在于新设计的特定于任务的前缀和两个不同的查询模板。具体来说,我们设计用于链路预测的 P 和 Q 如下: P = '对中心节点进行链路预测。注意节点之间的多跳链接关系。', Qgenerative = '{h} hop 内哪个节点将连接到 {v}?' and Qdiscriminative = '{~v} 会连接到 {v} {h} hop?' 内,其中 v 为中心节点,~v 为候选节点,h 为指定的跳级。
,链路预测的管道与上述方程 3 和 4 完全一致。唯一的区别在于新设计的特定于任务的前缀和两个不同的查询模板。具体来说,我们设计用于链路预测的 P 和 Q 如下: P = '对中心节点进行链路预测。注意节点之间的多跳链接关系。', Qgenerative = '{h} hop 内哪个节点将连接到 {v}?' and Qdiscriminative = '{~v} 会连接到 {v} {h} hop?' 内,其中 v 为中心节点,~v 为候选节点,h 为指定的跳级。
因此,我们将 InstructGLM 扩展为多任务、多提示指令调优框架。无论 InstructGLM 最终目标是什么图类型和与图相关的任务,包含辅助自监督链接预测都可以使图中的每个节点在训练期间充当多个指令prompt中的中心节点。因此,它不仅可以作为数据增强,还可以鼓励 LLM 理解图的全局连接模式,为 InstructGLM 提供进一步提高主要任务性能的有希望的潜力。
4 Experiments
4.1 Experimental Setup
在本文中,我们主要利用InstructGLM进行节点分类,并进行自监督链路预测作为辅助任务。具体来说,我们选择以下三个流行的图:ogbn-arxiv [66]、Cora 和 PubMed [77],其中每个节点代表特定主题的学术论文,其标题和摘要包含在原始文本格式中,并且如果两篇论文之间存在引用,那么对应的两个节点之间就会有一条边。 ogbn-arxiv 的图相对较大,而 Cora 和 PubMed 的图较小。我们所有的实验都采用数据集提供的默认数字节点特征嵌入,通过添加节点方式新构建的标记来扩展 LLM 的词汇量。值得注意的是,这些数据集使用不同的技术来生成默认的节点特征嵌入,我们使用它们的默认嵌入而不进行修改。表 1 总结了详细的数据集特定信息。
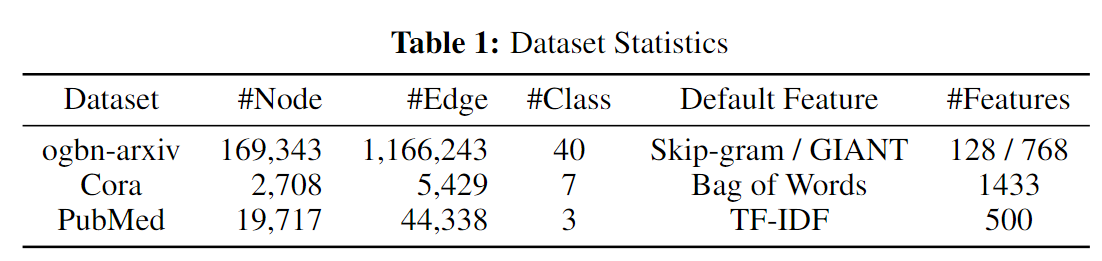
我们为所有实验采用多prompt指令调整框架,并将测试准确性报告为我们的指标。对于ogbn-arxiv数据集,我们采用与OGB开放基准[66]完全相同的数据集分割,即54%/18%/28%。对于 Cora 和 PubMed 数据集,我们使用 He 等人提出的包含原始文本信息的版本。 [28] 并在我们的实验中采用 60%/20%/20% 的训练/验证/测试分割。跟随 Yang 等人的研究,研究 InstructGLM 在低标签比训练环境下的表现。 [77],我们在 PubMed 数据集上进行了进一步的实验,每类固定 20 个标记训练节点,标签比率为 0.3%。
4.2 Main Results
我们的结果达到了最先进的性能,在所有三个数据集上超过了所有单一模型图学习器,包括代表性的 GNN 模型和图转换器模型,这表明大型语言模型作为图学习的基础模型是大有可为的趋势。更详细的结果和分析见下文。
4.2.1 ogbn-arxiv
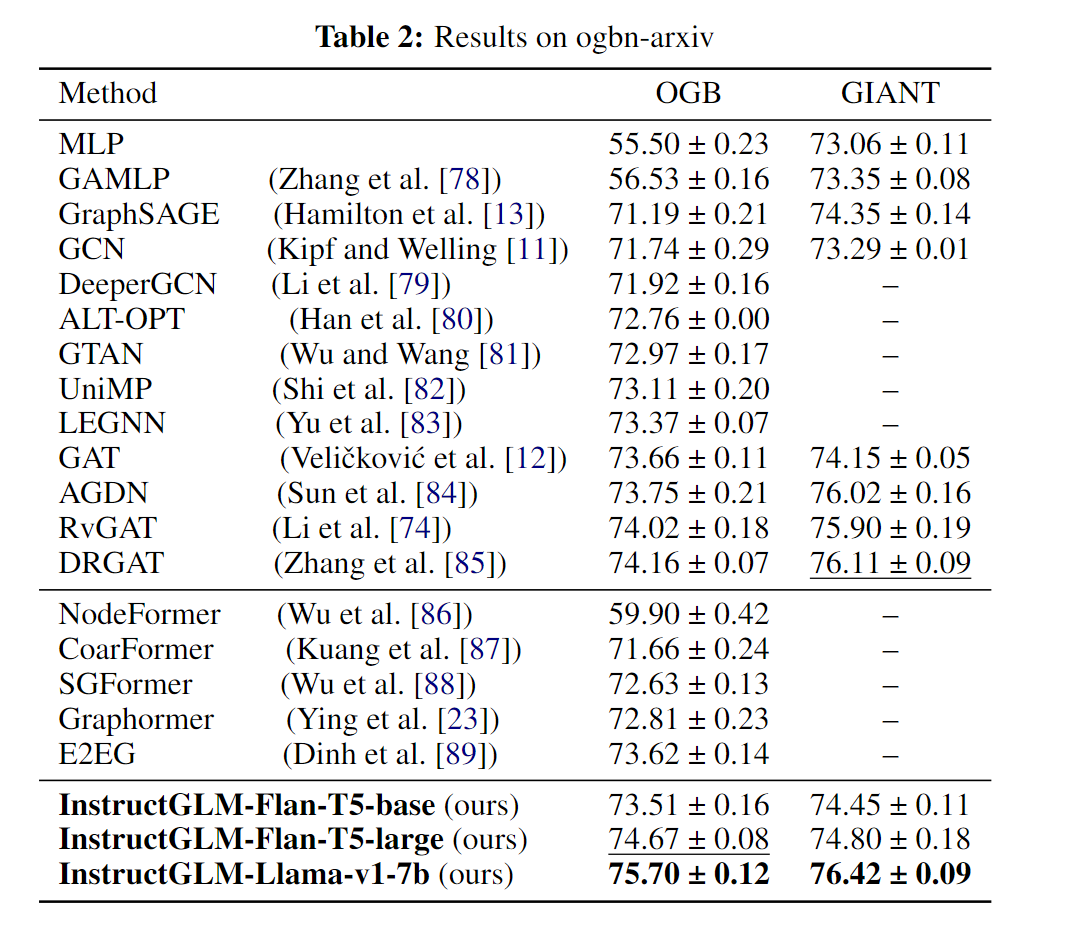
对于ogbn-arxiv数据集,我们从OGB Leaderboard1中选择一系列排名靠前的GNN,包括DRGAT、RevGAT、AGDN等作为基线。几个最强大的基于 Transformer 的单模型图学习器(例如 OGB 基准上的 Graphormer 和 E2EG)也被视为与我们提出的 InstructGLM 的比较方法。
我们对 Flan-T5 [38] 和 Llama-v1-7b [ 17] (LoRA) [ 90] 进行了指令微调,以此作为 InstructGLM 的基础。表 2 中的实验结果表明,InstructGLM 的性能优于所有的GNN 和基于 Transformer 的方法。特别是,当使用 Llama-v1-7b 作为 OGB 特征的骨干时,我们的 InstructGLM 比最好的 GNN 方法提高了 1.54%,比最好的基于 Transformer 的方法提高了 2.08%。同时,我们还在 GIANT [54] 特征上获得了新的 SoTA 性能。
4.2.2 Cora & PubMed
在 Cora 和 PubMed 数据集的比较方法方面,我们从两个相应的 benchmark2 3 中选择排名靠前的 GNN,包括 Snowball、MixHop、RevGAT、FAGCN 等作为基线。此外,这两个基准上三个最强大的基于 Transformer 的单模型图学习器,即 CoarFormer、Graphormer 和 GT,也被认为是与我们提出的 InstructGLM 进行比较的方法。
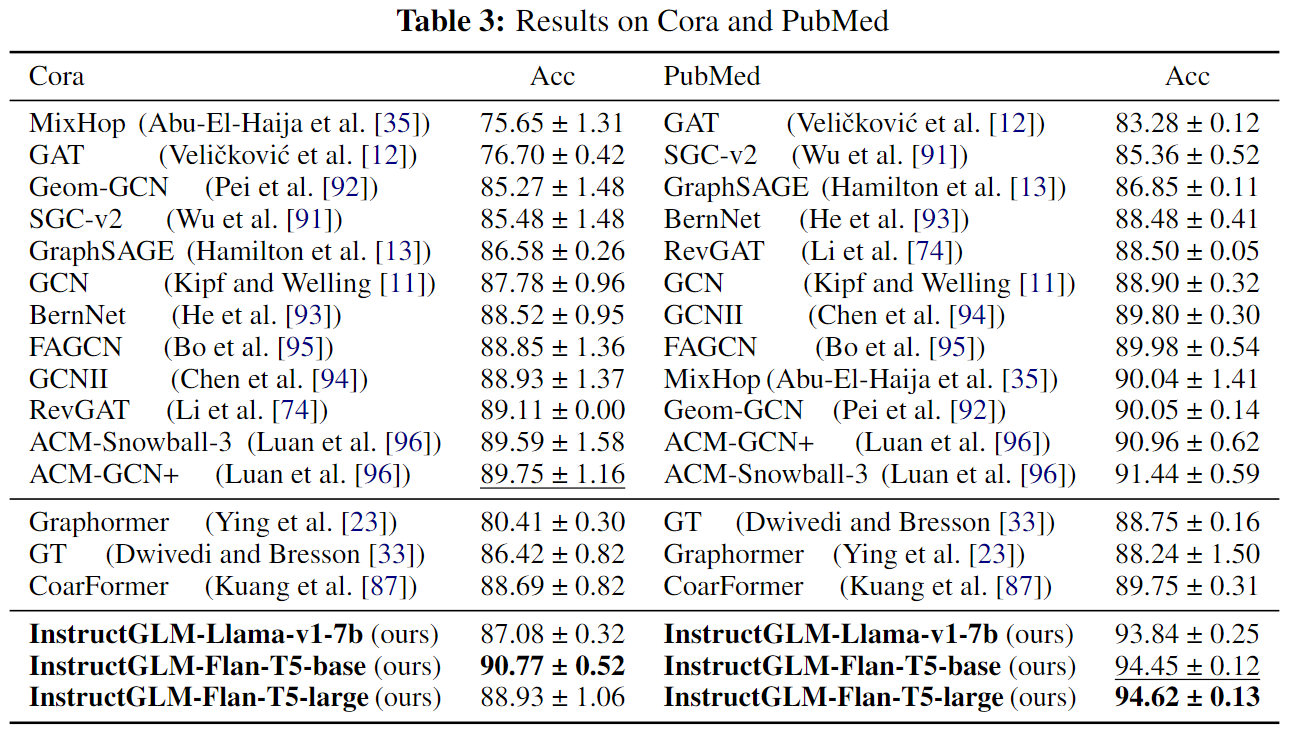
我们将 Flan-T5 和 Llama-v1 (LoRA) 作为 InstructGLM 的主干进行指令调节。表 3 中的实验结果表明,我们的 InstructGLM 优于所有 GNN 和基于变换器的方法。具体来说,在 Cora 数据集上,InstructGLM 比最佳 GNN 方法提高了 1.02%,比基于变换器的最佳方法提高了 2.08%;在 PubMed 数据集上,InstructGLM 比最佳 GNN 方法提高了 3.18%,比基于变换器的最佳方法提高了 4.87%。
4.3 Ablation Study
在我们的实验中,有助于 Instruct-GLM 在节点分类中取得卓越性能的两个关键操作是多提示指令调整,它为 LLM 提供多跳图结构信息,以及利用自监督链接预测作为一项辅助任务。为了验证两个关键组件对模型性能的影响,我们对所有三个数据集进行了消融实验,结果如表4所示。
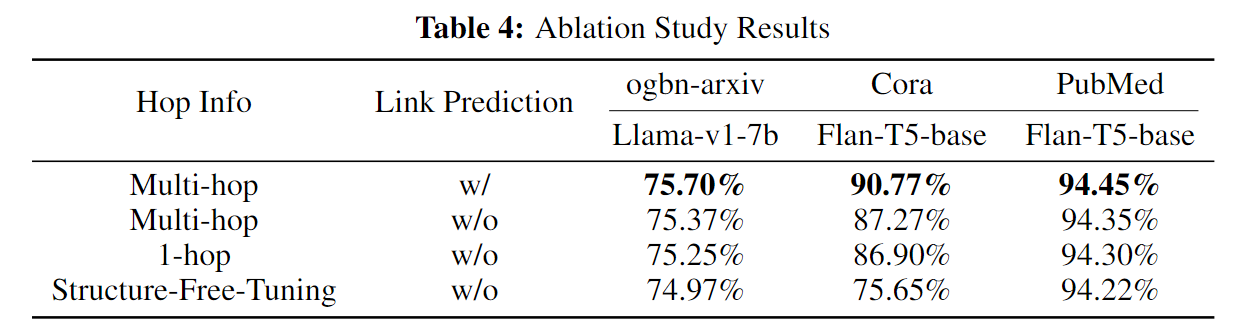
关于跳数信息一栏,无结构调整表示我们不考虑图的结构,即直接根据节点的标题和摘要对模型进行微调。而单跳(1-hop)和多跳(Multi-hop)分别表示我们使用的提示信息只包括来自单跳邻居的信息,以及包括来自更高跳数邻居的信息。实验结果表明,包含多跳信息和链接预测任务都能提高模型在节点分类任务中的性能。
4.4 Instruction Tuning at Low Label Ratio
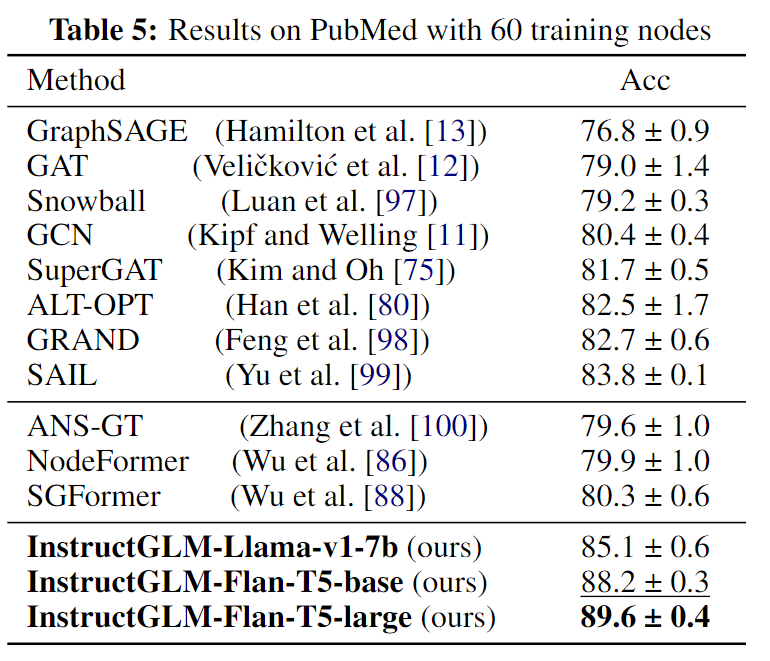
在之前的实验中,我们的数据分割都保证了相对较高的标记训练节点比例。为了进一步研究 InstructGLM 的可扩展性和鲁棒性,我们使用其另一个广泛使用的标签比率极低的分割在 PubMed 数据集上进行实验。具体来说,我们在此设置中只有 60 个可用的训练节点,因此标签比率为 0.3%。
我们考虑相应排行榜中排名靠前的 GNN,包括 SAIL、ALT-OPT、GRAND 等,作为与我们的 InstructGLM 进行比较的基线。我们还考虑了该数据集设置下三个最优秀的基于 Transformer 的图学习器。然后,我们对 Flan-T5 和 Llama 进行指令微调,将其作为 InstructGLM 的骨干。表5中的实验结果表明,Instruct-GLM优于所有GNN方法,相对于最佳GNN基线提高了5.8%,同时也超过了最好的基于Transformer的模型9.3%,成功实现了新的状态-排行榜上最先进的表现
5 Future Work
在本文中,我们对文本属性图(TAG)进行了广泛的实验,以展示我们提出的 InstructGLM 在解决图机器学习问题方面的强大功能。我们的指令prompt旨在用自然语言描述图形结构,表现出高度的通用性和可扩展性,使其适用于几乎所有类型的图形。未来潜在的有价值的工作可以从三个维度进行探索:
对于 TAG,我们的实验仅使用默认的 OGB 特征嵌入。未来的工作可以考虑使用更高级的 TAG 相关嵌入功能,例如基于 LLM 的功能,如 TAPE [28]。此外,利用LLM的思想链、结构信息汇总和其他数据增强技术来生成更强大的指令PROMPT将是图语言模型的一个有前途的研究方向。
• InstructGLM 可以集成到 GAN、GLEM 等框架中以进行多模型迭代训练,或利用现成的 GNN 进行知识提炼。此外,标签重用、Self-KD、正确和平滑等经典图机器学习技术可以进一步提高模型的性能。
• 受益于自然语言强大的表达能力和指令提示的高度可扩展设计,InstructGLM 可以在统一的生成语言建模框架内轻松扩展到各种图形,解决广泛的图形学习问题。例如,我们设计的指令prompt可以直接进一步用于链接预测和归纳节点分类任务。只需对我们的提示稍作修改,就可以有效部署诸如图分类、中间节点/路径预测甚至具有丰富边缘特征的知识图中基于关系的问答任务等任务

















 3425
3425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









