










写在前面
1、本文内容
cmake编译测试openmp的效果
2、平台/环境
windows/linux均可,cmake
3、转载请注明出处:
https://blog.csdn.net/qq_41102371/article/details/131629705
代码
代码包含同样的for循环使用openmp加速,使用openmp加速并使用critical,不使用openmp的测试, 代码目录结构如下,请将test_openmp.cpp和CMakeLists.txt放入src
test_openmp.cpp
#include <iostream>
#include <vector>
#include <chrono>
#include <omp.h>
void computeWithOpenMP(const std::vector<int> &data)
{
// #pragma omp parallel
{
std::vector<int> result(data.size());
#pragma omp parallel for
for (int i = 0; i < data.size(); ++i)
{
if (i >= 0 && i <= 1000000)
{
// 使用 OpenMP 并行计算
result[i] = data[i] * 2;
}
}
}
}
void computeWithOpenMPCritical(const std::vector<int> &data)
{
{
std::vector<int> result(data.size());
int count = 0;
#pragma omp parallel for
for (int i = 0; i < data.size(); ++i)
{
if (i >= 0 && i <= 1000000)
{
#pragma omp critical
// 使用 OpenMP 并行计算
result[i] = data[i] * 2;
}
}
}
}
void computeWithoutOpenMP(const std::vector<int> &data)
{
std::vector<int> result(data.size());
for (int i = 0; i < data.size(); ++i)
{
// 未使用 OpenMP,串行计算
if (i >= 0 && i <= 1000000)
{
result[i] = data[i] * 2;
}
}
}
int main(int argc, char **argv)
{
#ifdef _OPENMP
std::cout << "use _OPENMP" << std::endl;
std::cout << "max tread: " << omp_get_max_threads() << std::endl;
#else
std::cout << "no _OPENMP" << std::endl;
#endif
int size = std::atoi(argv[1]);
std::vector<int> data(size, 1);
// 使用 OpenMP 加速的计算
auto start = std::chrono::high_resolution_clock::now();
computeWithOpenMP(data);
auto end = std::chrono::high_resolution_clock::now();
auto durationOpenMP = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / 1000.0;
// 使用 OpenMP 加速,并使用了critical
start = std::chrono::high_resolution_clock::now();
computeWithOpenMPCritical(data);
end = std::chrono::high_resolution_clock::now();
auto durationOpenMPCritical = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / 1000.0;
// 未使用 OpenMP 的计算
start = std::chrono::high_resolution_clock::now();
computeWithoutOpenMP(data);
end = std::chrono::high_resolution_clock::now();
auto durationNoOpenMP = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / 1000.0;
// 打印时间结果
std::cout << "With OpenMP: " << durationOpenMP << " ms" << std::endl;
std::cout << "With OpenMPCritical: " << durationOpenMPCritical << " ms" << std::endl;
std::cout << "No OpenMP: " << durationNoOpenMP << " ms" << std::endl;
return 0;
}
CMakeLists.txt
cmake_minimum_required(VERSION 3.18)
project(TestOpenMP)
find_package(OpenMP)
add_executable(test_openmp ./test_openmp.cpp)
if(OpenMP_CXX_FOUND)
target_link_libraries(test_openmp OpenMP::OpenMP_CXX)
endif()
compile.bat
cmake -DCMAKE_BUILD_TYPE=Release -S ./src -B ./build
cmake --build ./build --config Release --target ALL_BUILD
run.bat
.\build\Release\test_openmp.exe 500000000
其中参数500000000是数据量,测试时修改不同值看效果
编译运行
编译
cd test_openmp
./compile.bat
运行
./run.bat
下面是数据量是500000000是在笔记本i7-12700H上的结果
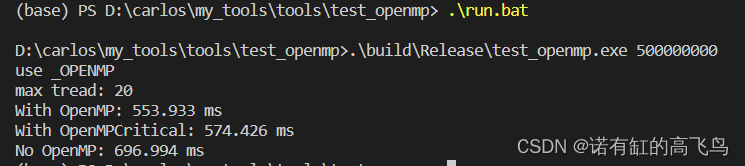
请通过第一个打印信息use _OPENMP或者no _OPENMP来判断openmp是否正常配置或可用
关于加速效果
根据实测,加速效果根据硬件、for循环的计算内容、数据量而不同,有时候还看运气。
下面是chatgpt关于openmp加速效果的回答:
当使用 OpenMP 进行并行化时,性能的提升并不是绝对的,它取决于多个因素,包括但不限于以下几点:
-
并行化开销:并行化需要额外的开销来进行线程间的同步和任务划分。当问题规模较小时,这些开销可能会超过并行化带来的性能收益,从而导致性能下降。
-
数据访问模式:并行化的效果受到数据访问模式的影响。如果数据访问存在竞争条件或者导致缓存冲突,那么并行化可能会导致性能下降。在某些情况下,串行执行可能更有效。
-
硬件资源限制:并行化的效果受到可用的硬件资源限制的影响。如果系统的物理核心数有限,而问题规模较大,那么并行化的效果可能会受到限制。
-
任务粒度:任务的粒度越细,可以提供更好的负载平衡和并行化效果。如果任务过于细小,可能会导致线程间的同步开销超过并行化带来的性能收益。
在使用 OpenMP 进行并行化时,可以尝试以下几种方法来判断是否应该使用 OpenMP:
-
基于经验:根据以往的经验,对问题规模、计算复杂度和硬件环境进行评估。如果问题规模较大,计算复杂度高,并且有足够的硬件资源,那么可能值得尝试使用 OpenMP 进行并行化。
-
性能分析:使用性能分析工具(如
perf、gprof、Intel VTune等)来评估串行代码的性能瓶颈,并检查是否存在并行化的潜在机会。通过性能分析,可以确定哪些代码段可以获得较大的性能提升,并尝试将其并行化。 -
实验验证:根据问题规模和计算复杂度,在小规模的样本上进行实验验证。比较串行和并行化的性能,并根据实验结果来决定是否使用 OpenMP 进行并行化。
重要的是要记住,并行化并不总是能够带来性能提升,有时甚至可能导致性能下降。在决定是否使用 OpenMP 进行并行化时,需要进行合理的评估和实验验证,结合问题的特点和硬件环境,做出明智的决策。
参考
CMakeLists 增加 OpenMP 的支持
CMake+OpenMP编译运行最简单的c++代码
完
主要做激光/影像三维重建,配准、分割等常用点云算法,技术交流、咨询可私信















 2558
2558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











